
NVIDIA 推出了Llama Nemotron Nano VL,这是一种视觉语言模型 (VLM),旨在高效、精准地处理文档级理解任务。该版本基于 Llama 3.1 架构构建,并配备轻量级视觉编码器,面向需要精确解析复杂文档结构(例如扫描表单、财务报告和技术图表)的应用程序。
模型概述和架构
Llama Nemotron Nano VL 将CRadioV2-H 视觉编码器与Llama 3.1 8B 指令调优语言模型相结合,形成能够联合处理多模式输入的管道——包括具有视觉和文本元素的多页文档。
该架构针对高效标记推理进行了优化,支持跨图像和文本序列的上下文长度高达 16K。该模型可以处理多幅图像以及文本输入,非常适合处理长篇多模态任务。视觉-文本对齐是通过投影层和针对图像块嵌入量身定制的旋转位置编码实现的。
训练分三个阶段进行:
- 第 1 阶段:在商业图像和视频数据集上进行交错图像文本预训练。
- 第 2 阶段:多模式指令调整以实现交互式提示。
- 第 3 阶段:纯文本指令数据重新混合,提高标准 LLM 基准的性能。
所有训练均使用 NVIDIA 的Megatron-LLM 框架和 Energon 数据加载器进行,分布在具有 A100 和 H100 GPU 的集群上。
基准测试结果与评估
Llama Nemotron Nano VL 在OCRBench v2上进行了评估,该基准旨在评估 OCR、表格解析和图表推理任务中文档级视觉语言理解能力。OCRBench 包含 10,000 多个经人工验证的 QA 对,涵盖金融、医疗保健、法律和科学出版等领域的文档。
结果表明,该模型在该基准测试中达到了紧凑型可变长度语言模型 (VLM) 中的最高准确率。值得注意的是,其性能与规模较大、效率较低的模型相比毫不逊色,尤其是在提取结构化数据(例如表格和键值对)和回答与布局相关的查询方面。
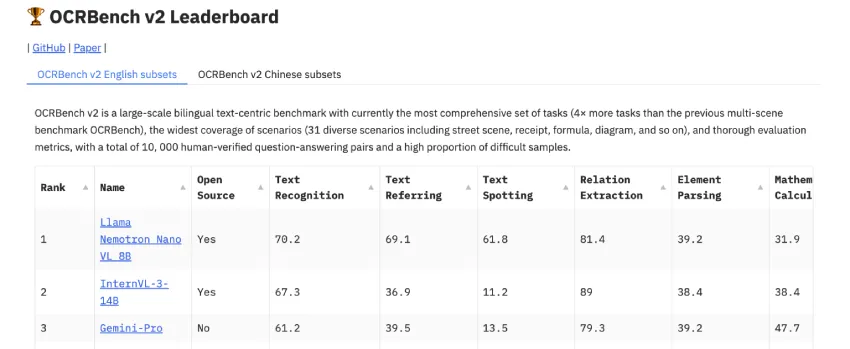

该模型还可推广至非英语文档和质量下降的扫描,反映了其在现实条件下的稳健性。
部署、量化和效率
Nemotron Nano VL 专为灵活部署而设计,支持服务器和边缘推理场景。NVIDIA 提供量化 4 位版本 (AWQ),可利用TinyChat和TensorRT-LLM进行高效推理,并兼容 Jetson Orin 和其他受限环境。
主要技术特点包括:
- 模块化 NIM(NVIDIA 推理微服务)支持,简化 API 集成
- ONNX 和 TensorRT 导出支持,确保硬件加速兼容性
- 预计算视觉嵌入选项,可减少静态图像文档的延迟
结论
Llama Nemotron Nano VL 在文档理解领域实现了性能、上下文长度和部署效率之间的完美平衡。其架构基于 Llama 3.1 并增强了紧凑型视觉编码器,为需要在严格延迟或硬件限制下进行多模态理解的企业应用提供了实用的解决方案。
Nemotron Nano VL 在保持可部署占用空间的同时,在 OCRBench v2 中名列前茅,将自己定位为自动文档 QA、智能 OCR 和信息提取管道等任务的可行模型。
更多详细信息请查看:https://huggingface.co/nvidia/Llama-3.1-Nemotron-Nano-VL-8B-V1
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/58582.html