
如何构建一个能够可靠理解文本、图像、音频和视频,同时仍能高效运行的统一模型?来自哈尔滨工业大学深圳分校的研究团队推出了 Uni-MoE-2.0-Omni,这里一款全开放式全模态大型模型,将 Lychee 的 Uni-MoE 系列推向以语言为中心的多模态推理领域。该系统基于 Qwen2.5-7B 密集型骨干模型从零开始训练,通过动态容量路由扩展为专家混合架构,采用渐进式监督学习与强化学习方案,并匹配约 750 亿令牌的精心标注多模态数据集。它能处理文本、图像、音频和视频的理解任务,并可生成图像、文本及语音内容。

围绕语言核心的统一模态编码架构
Uni-MoE-2.0-Omni 的核心是一个 Qwen2.5-7B 风格的 Transformer 模型,它作为语言中心枢纽。围绕这个枢纽,研究团队集成了一个统一的语音编码器,该编码器将包括环境音、语音和音乐在内的各种音频映射到一个通用的表示空间。在视觉方面,预训练的视觉编码器处理图像和视频帧,然后将标记序列输入到同一个 Transformer 模型中。在生成方面,一个基于上下文感知 MoE 的 TTS 模块和一个基于任务感知的扩散 Transformer 模型分别负责语音和图像的合成。
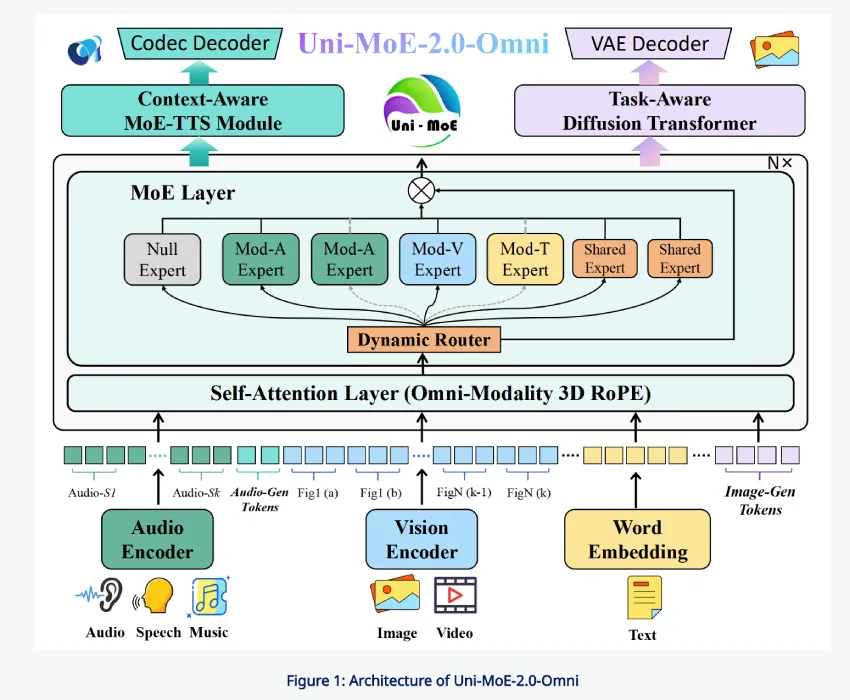
所有模态都被转换为词元序列,这些词元序列通过统一的接口与语言模型交互。这种设计意味着相同的自注意力层可以处理文本、视觉和音频词元,从而简化跨模态融合,并使语言模型成为理解和生成的核心控制器。该架构旨在支持 10 种跨模态输入配置,例如图像加文本、视频加语音以及三模态组合。
全模态 3D RoPE 和 MoE驱动融合
跨模态对齐由全模态 3D RoPE 机制处理,该机制将时间和空间结构直接编码到旋转位置嵌入中。系统并非仅使用一维位置来表示文本,而是为每个标记分配三个坐标:视觉和音频流的时间、高度和宽度,以及语音的时间。这使得 Transformer 能够明确地了解每个标记出现的时间和位置,这对于视频理解和视听推理任务至关重要。
混合专家模型(MoE)层用一个包含三种专家类型的MoE堆栈替换了标准的多层感知器(MLP)模块。空专家充当空函数,允许在推理时跳过计算。路由专家是模态特定的,存储音频、视觉或文本的领域知识。共享专家规模较小且始终处于激活状态,为跨模态的通用信息提供通信路径。路由网络根据输入词元选择激活哪些专家,从而实现专业化,而无需付出所有专家都激活的密集模型的全部成本。
训练方案,从跨模态预训练到 GSPO DPO
训练流程采用数据匹配式方法。首先,以语言为中心的跨模态预训练阶段使用配对的图像文本、音频文本和视频文本语料库。此步骤教会模型将每种模态映射到与语言一致的共享语义空间。基础模型使用约 750 亿个开源多模态词元进行训练,并配备了特殊的语音和图像生成词元,以便通过语言线索来学习生成行为。
接下来,渐进式监督微调阶段会激活按模态分组的专家,这些专家分为音频、视觉和文本类别。在此阶段,研究团队引入特殊的控制标记,使模型能够在同一语言界面内执行诸如文本条件语音合成和图像生成等任务。经过大规模监督微调 (SFT) 后,数据平衡退火阶段会对跨模态和任务的数据集混合进行重新加权,并使用较低的学习率进行训练。这可以避免模型过拟合单一模态,并提高最终全模态行为的稳定性。
为了实现长篇推理,Uni-MoE-2.0-Omni 增加了一个基于 GSPO 和 DPO 的迭代策略优化阶段。GSPO 使用模型自身或其他 LLM 作为评判者来评估响应并构建偏好信号,而 DPO 则将这些偏好转化为比基于人类反馈的标准强化学习更稳定的直接策略更新目标。研究团队将此 GSPO DPO 循环应用多轮,从而形成了 Uni-MoE-2.0-Thinking 变体,该变体继承了全模态基础并增加了更强大的逐步推理能力。
生成、MoE TTS 和任务感知扩散
在语音生成方面,Uni-MoE-2.0-Omni 使用了一个基于上下文感知的 MoE TTS 模块,该模块位于语言模型之上。语言模型 (LLM) 会发出描述音色、风格和语言以及文本内容的控制标记。MoE TTS 模块接收此序列并生成离散的音频标记,然后由外部编解码器模型将其解码为波形,与输入端的统一语音编码器进行匹配。这种设计使得语音生成成为一个一级控制生成任务,而不是一个独立的流程。
在视觉方面,任务感知扩散变换器同时以任务标记和图像标记为条件。任务标记编码系统应执行文本到图像的生成、编辑还是低级增强操作。图像标记可以从全模态主干网络捕获语义信息,例如来自文本加图像的对话。轻量级投影器将这些标记映射到扩散变换器的条件空间,从而实现指令引导的图像生成和编辑,同时在最终的视觉微调阶段保持主全模态模型的冻结状态。
基准测试和开放检查点
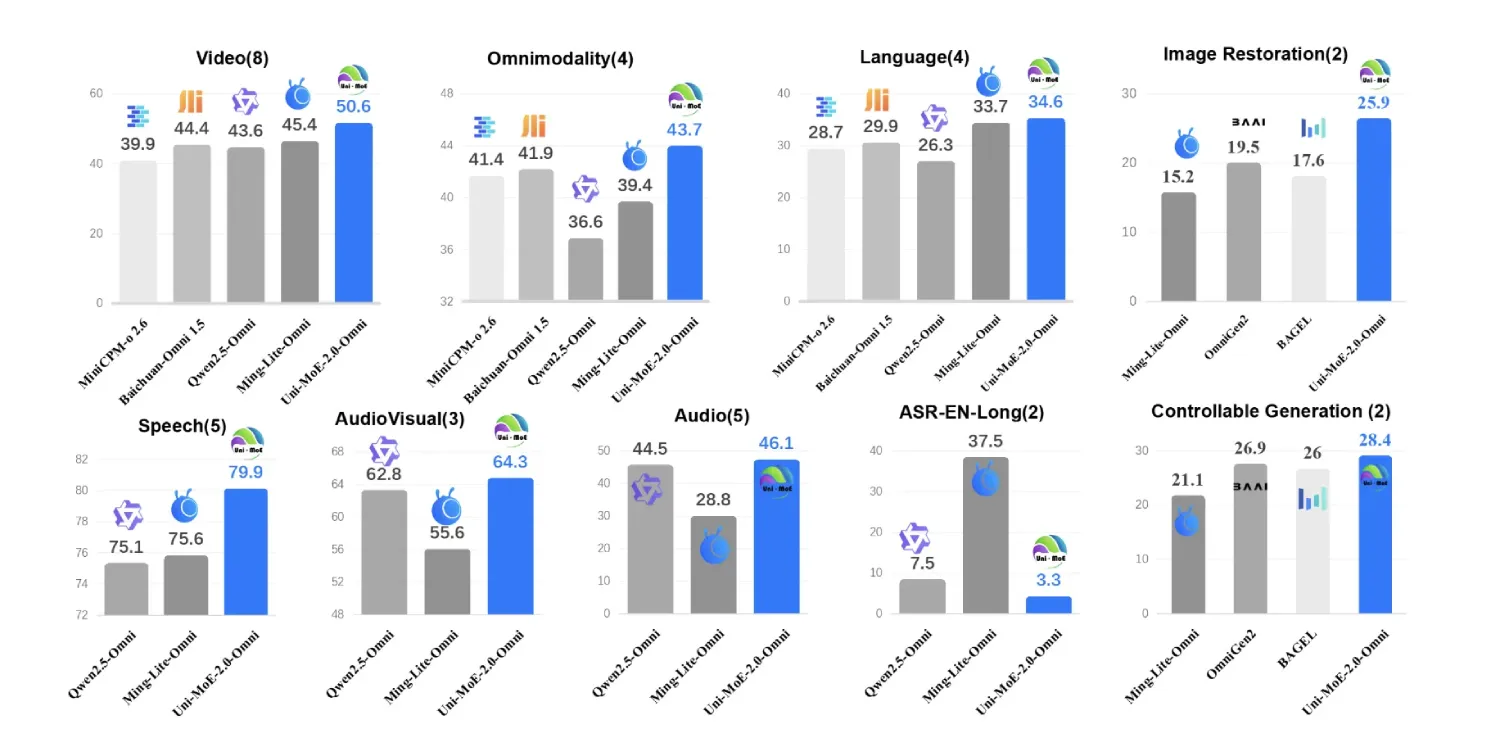
Uni-MoE-2.0-Omni 模型在涵盖图像、文本、视频、音频以及跨模态或三模态推理的 85 个多模态基准测试中进行了评估。该模型在 76 个共享基准测试中的 50 多个测试中超越了使用约 1.2T 个 token 训练的 Qwen2.5-Omni 模型。具体而言,该模型在 8 项视频理解任务中的平均性能提升约 7%,在包括 OmniVideoBench 和 WorldSense 在内的 4 项基准测试中全模态理解任务的平均性能提升约 7%,以及在音视频推理任务中的平均性能提升约 4%。
对于长篇语音处理,Uni-MoE-2.0-Omni 在 LibriSpeech 长语音分割任务中,词错误率 (WER) 相对降低了高达 4.2%,在 TinyStories-en 文本转语音任务中,WER 也降低了约 1%。图像生成和编辑结果与专业的视觉模型相比毫不逊色。研究团队报告称,与 Ming Lite Omni 相比,Uni-MoE-2.0-Omni 在 GEdit Bench 测试中取得了约 0.5% 的稳定提升,同时在多个底层图像处理指标上也优于 Qwen Image 和 PixWizard。
要点总结
- Uni-MoE-2.0-Omni 是一个完全开放的全模态大型模型,它基于 Qwen2.5-7B 密集骨干网从零开始构建,并升级为混合专家架构,支持 10 种跨模态输入类型以及对文本、图像、音频和视频的联合理解。
- 该模型引入了具有共享、路由和空专家的动态容量 MoE,以及全模态 3D RoPE,它们通过按令牌路由专家来平衡计算和能力,同时在自注意力层内保持跨模态的时空对齐。
- Uni-MoE-2.0-Omni 使用分阶段训练流程、跨模态预训练、与模态特定专家进行渐进式监督微调、数据平衡退火和基于 GSPO 和 DPO 的强化学习,以获得 Uni-MoE-2.0-Thinking 变体,从而实现更强大的长形式推理。
- 该系统通过统一的以语言为中心的界面支持全模态理解和生成图像、文本和语音,并具有从同一基础衍生出的专用 Uni-MoE-TTS 和 Uni-MoE-2.0-Image 头,用于可控的语音和图像合成。
- 在 85 项基准测试中,Uni-MoE-2.0-Omni 在 76 项共享任务中的 50 多项上超越了 Qwen2.5-Omni,在视频理解和全模态理解方面提升了约 7%,在视听推理方面提升了 4%,在长语音方面相对 WER 降低了高达 4.2%。
参考资料
- 论文:https://arxiv.org/pdf/2511.12609
- 代码库:https://github.com/HITsz-TMG/Uni-MoE
- 项目:https://idealistxy.github.io/Uni-MoE-v2.github.io/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/63107.html