
听说过通用人工智能 (AGI) 吗?来认识一下它在听觉领域的对手,通用音频智能 (Audio General Intelligence )。NVIDIA 凭借Audio Flamingo 3 (AF3),在机器理解和推理声音方面实现了重大飞跃。虽然过去的模型可以转录语音或对音频片段进行分类,但它们缺乏以丰富的语境和类似人类的方式解读音频的能力——涵盖语音、环境声、音乐以及长时长音频。AF3 改变了这一切。
NVIDIA 推出了 Audio Flamingo 3,这是一个完全开源的大型音频语言模型 (LALM),它不仅能够聆听,还能理解和推理。AF3 基于五阶段课程构建,并由 AF-Whisper 编码器提供支持,支持长达 10 分钟的长音频输入、多轮多音频聊天、按需思考,甚至语音对语音交互。这为 AI 系统与声音的交互树立了新的标杆,让我们更接近 AGI。
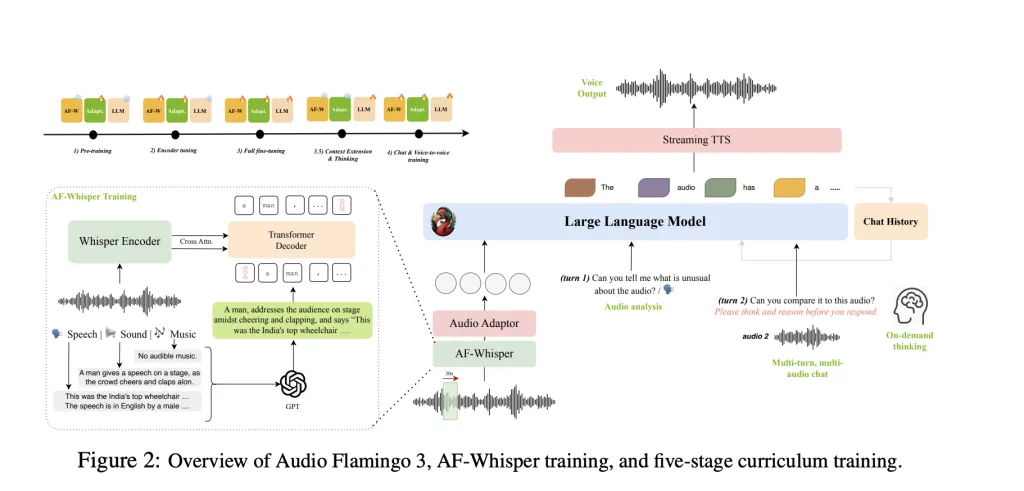

Audio Flamingo 3 背后的核心创新
- AF-Whisper:统一音频编码器。AF3 使用 AF-Whisper,这是一款改编自 Whisper-v3 的新型编码器。它使用相同的架构处理语音、环境声音和音乐,解决了早期 LALM 使用独立编码器导致不一致的主要缺陷。AF-Whisper 利用音频字幕数据集、合成元数据和密集的 1280 维嵌入空间来与文本表示对齐。
- 音频的思维链:按需推理。与静态问答系统不同,AF3 具备“思考”能力。使用 AF-Think 数据集(25 万个示例),该模型可以根据提示进行思维链推理,从而能够在得出答案之前解释其推理步骤——这是迈向透明音频 AI 的关键一步。
- 多回合、多音频对话。借助 AF-Chat 数据集(7.5 万条对话),AF3 可以进行跨回合、多音频输入的上下文对话。这模拟了现实世界中的互动,即人类会参考之前的音频提示。此外,它还引入了使用流式文本转语音模块的语音对语音对话。
- 长音频推理。AF3 是首个完全开放的模型,能够对长达 10 分钟的音频输入进行推理。该模型使用 LongAudio-XL(125 万个样本)进行训练,支持会议摘要、播客理解、讽刺检测和时间基础等任务。

先进的基准测试和实际能力
AF3 在 20 多项基准测试中超越了开放式和封闭式模型,其中包括:
AF3 在 20 多个基准测试中超越了开放和封闭模型,其中包括:
- MMAU(平均): 73.14%(比 Qwen2.5-O +2.14%)
- LongAudioBench: 68.6(GPT-4o 评估),击败 Gemini 2.5 Pro
- LibriSpeech(ASR): WER 为 1.57%,优于 Phi-4-mm
- ClothoAQA: 91.1%(Qwen2.5-O 为 89.2%)
这些改进并非微不足道,而是重新定义了人们对音频语言系统的期望。AF3 还引入了语音聊天和语音生成方面的基准测试,实现了 5.94 秒的生成延迟(Qwen2.5 为 14.62 秒),并获得了更高的相似度得分。
数据管道:教授音频推理的数据集
NVIDIA 不仅扩展了计算能力,还重新思考了数据:
- AudioSkills-XL:结合环境、音乐和语音推理的 800 万个示例。
- LongAudio-XL:涵盖有声读物、播客、会议中的长篇演讲。
- AF-Think:促进简短的 CoT 式推理。
- AF-Chat:专为多轮、多音频对话而设计。
每个数据集都是完全开源的,并附带训练代码和配方,以实现可重复性和未来的研究。
开源
AF3 不仅仅是一个型号的下降。NVIDIA 发布:
- 模型权重
- 训练食谱
- 推理代码
- 四个开放数据集
这种透明性使 AF3 成为最易用、最先进的音频语言模型。它为听觉推理、低延迟音频代理、音乐理解和多模态交互等研究方向开辟了新的方向。
结论:迈向通用音频智能
Audio Flamingo 3 证明了深度音频理解不仅可行,而且可重复且开放。通过结合规模、新颖的训练策略和多样化的数据,NVIDIA 提供了一个能够以以往 LALM 无法企及的方式进行聆听、理解和推理的模型。
资料
- 论文地址:https://huggingface.co/nvidia/audio-flamingo-3
- 代码:https://github.com/NVIDIA/audio-flamingo
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/59811.html