
当前视频到音频(Video-to-Audio, V2A)模型可以从视觉输入中生成逼真的背景音频,但它们大多忽略了语音在视频音轨中的关键组成部分。近期,西工大音频语音与语言处理研究组(ASLP@NPU)联合巨人网络、University of Surrey合作的论文 “DualDub: Video-to-Soundtrack Generation via Joint Speech and Background Audio Synthesis” 被多媒体领域顶级会议 ACM MM 2025 接收。
论文题目:DualDub: Video-to-Soundtrack Generation via Joint Speech and Background Audio Synthesis
作者列表:田文杰,朱新发,刘濠赫,赵致闲,陈子浩,丁超凡,邸新汉,郑俊杰,谢磊
合作单位:巨人网络、University of Surrey
论文原文:https://arxiv.org/pdf/2507.10109
该论文提出了一个新任务:视频到音轨生成 (Video-to-SoundTrack, V2ST),旨在统一框架下联合生成和谐且同步的背景音频和语音。DualDub通过多模态编码器、多模态对齐模块,以及两个解码头,用于同时生成背景音频和语音。跨模态对齐模块结合了因果注意力与非因果注意力机制,以提升生成内容的时间同步性和声学和谐性。此外,为了应对数据稀缺的问题,我们设计了一种课程学习策略 ,逐步构建模型的多模态能力。最后,我们引入了DualBench,首个面向V2ST任务评估的基准测试集,包含精心整理的测试集和全面的评估指标。实验结果表明,DualDub在生成高质量、时间同步的包含语音和背景音频的音轨方面达到了当前先进的性能。
背景动机
近年来,视频生成音频(V2A)取得了显著进展。然而,语音作为视频中重要的声音内容,目前在V2A研究中仍被忽视。尽管大多数模型在训练时包含了语音数据,但并未引入抄本和说话人提示等条件信息。因此,语音被当作普通音效处理,生成结果往往含糊不清、无法理解,缺乏语言结构。这限制了V2A在需要同时生成背景音和语音的应用中的实际效果。因此,我们提出一个关键问题:能否构建一个统一的模型,同时生成清晰可懂的语音和连贯的背景声音?为了实现这一目标,DualDub 必须能处理多模态输入并进行跨模态融合,能够在一个统一的框架以实现音频和语音的联合生成。如图1所示,DualDub 能在给定参考语音, 文本转录和一段无声视频序列的情况下,和谐地生成背景音频和语音。

提出的方法
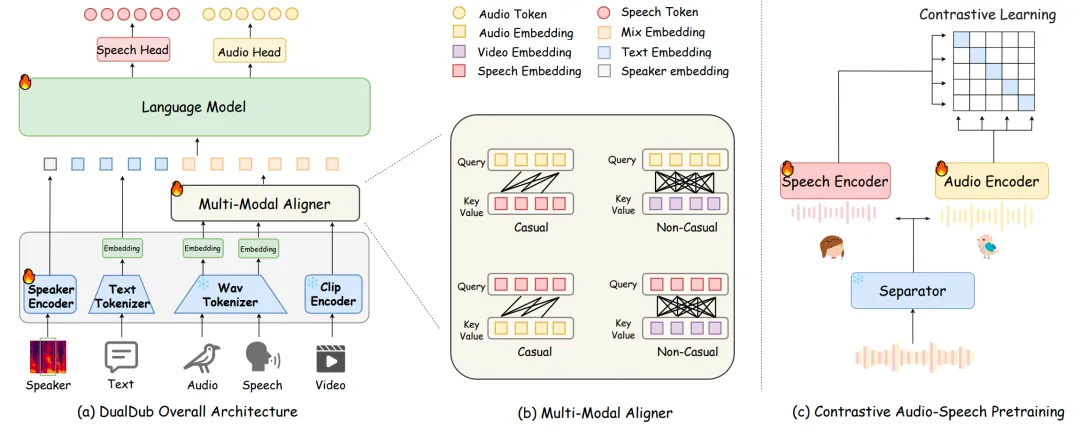
如图2所示,DualDub 包含三个主要组件:多模态编码器、多模态对齐器、多模态语言模型。具体来说,多模态编码器接收并处理多模态输入,随后,多模态语言模型以自回归方式处理说话人提示、文本序列以及融合后的多模态序列同时输出audio and speech。因此,在视频、文本和说话人提示的共同引导下,语音与音频配对生成,实现了视频到原声带(V2ST)的生成。
多模态编码器
如图2(a)所示,在 DualDub 中,多模态编码器接收并处理多模态输入,并将其转换为嵌入表示。我们使用了一个统一编码音频和语音的Tokenizer (WavTokenizer[1])离散化背景音频和语音。使用Clip[6]提取视频特征,文本使用BPE,并且使用一个可训练的说话人编码器提供语音的声学信息。
多模态对齐器
在 DualDub 中,我们设计了一个跨模态对齐模块,用于同步视频、背景音频和语音的时间并实现融合,同时确保生成内容的一致性。如图2(b)所示,该模块受交叉注意力掩码策略启发[2],采用混合交叉注意力机制,结合模态内因果注意力和模态间非因果注意力,提升跨模态的同步性与声学协调性。该模块将音频、语音和视频信息融合为一个序列,用于语言模型处理。
多模态语言模型
多模态语言模型以自回归方式处理说话人提示、文本序列以及融合后的多模态序列,通过两个语言模型头将隐藏输出分别映射到两个标记流,其中一个流对应音频标记,另一个流对应语音标记。最使用一个波形解码器从预测的音频和语音标记中重建高质量的语音和音频波形。因此,在视频、文本和说话人提示的共同引导下,语音与音频实现配对生成,实现了V2ST的生成。
课程学习
训练多模态语言模型需要大量视频-文本-语音-音频配对数据,但这类数据非常稀缺,给训练带来巨大挑战。为此,我们提出了一种三阶段课程学习策略,让模型在少量数据下逐步学习到各种生成能力。每一阶段在前一阶段基础上进阶,既实现了知识迁移,又避免了灾难性遗忘,有效提升了模型在低资源条件下的表现。具体而言,在第一阶段,只使用V2A数据进行训练,使模型具有V2A的生成能力。第二阶段加入TTS数据,让模型能够分别单独生成语音和音频。第三阶段加入配对数据,使模型能够实现模态间的信息融合,学会在文本和视频的共同引导下生成音轨。
波形重建
音频编解码器主要用于音频信号的传输,其首要目标是实现较低的比特率,因此在一定程度上牺牲了音质。为此,我们提出了一种两阶段解码器,用以替代 WavTokenizer 的解码器,从而提升合成音质。受到最新 Flow-matching 模型研究成果的启发,我们利用变分自编码器(VAE)强大的音频重构能力,使用VAE提取音频模态的潜在表示,并引入基于 DiT 的 Flow-matching 网络,将语言模型预测出的离散音频标记转换至 VAE 的潜在空间中,最后利用VAE 的解码器重构回音频。
基准构建
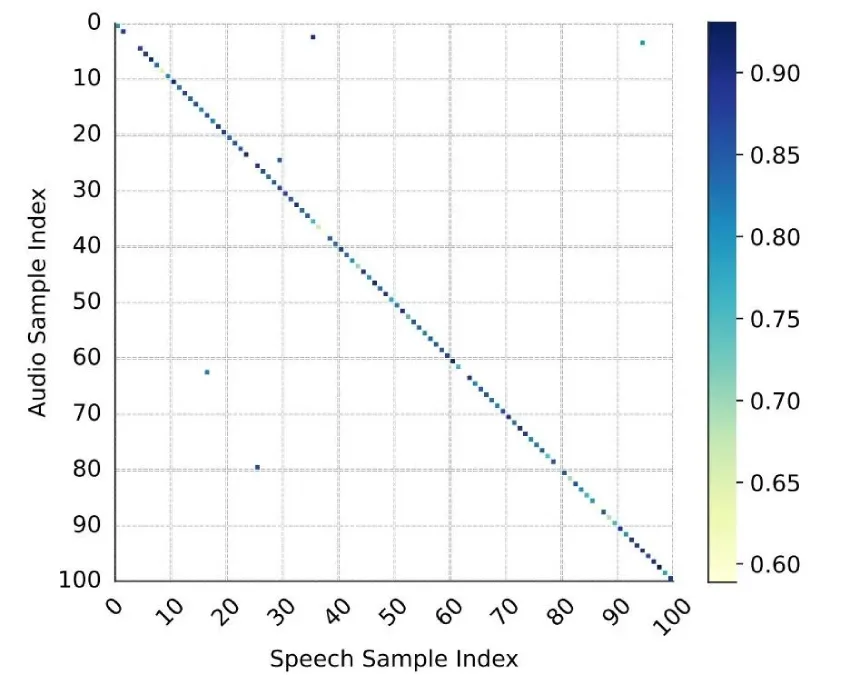
由于配对的视频,文本,音频,语音数据缺乏,因此我们提出了一套用于构建相关配套数据的流程。此外,为了评估生成的音频和语言的和谐程度,我们提出了DualScore这一客观评估指标。如图2(c)所示,受到Clip[6]启发,采取对比学习的方式分别训练音频和语音两个分支,从而实现评估音频和语言的和谐度。值得注意的是,我们采用相同结构的语音编码器和音频编码器,但是语音分支随机初始化,音频分支使用BEATs[7]预训练模型初始化。此外,大量的语音和音频配对数据我们选择了电影数据,将音轨通过MelBandRoformer[8]分离得到音频-语音数据对进行训练。如图3所示,该对比模型实现了 70% 的 Top1 准确率、90% 的 Top3 准确率和 95% 的 Top5 准确率,这充分证明了 DualScore 的有效性。
实验验证
实验数据
本文使用包含VGGSound[3]、LibriTTS[4]、Anim-400K[5] 等开源数据和100小时配对的电影数据数据,这些数据都是经过我们提出的数据处理流程之后使用的。
评估指标
对于V2ST任务,我们将评估指标主要分为了三类指标:生成质量,音视频对齐度,音频-语音和谐度。
- 生成质量具体包含:FD,FAD,IS,KL,SIM,WER,UTMOS。前四个用于评估生成的音频的质量,后三个用于评估生成的语音的质量。
- 音视频对齐度具体包含:AV-Align
- 音频-语音和谐度具体包含:DualScore
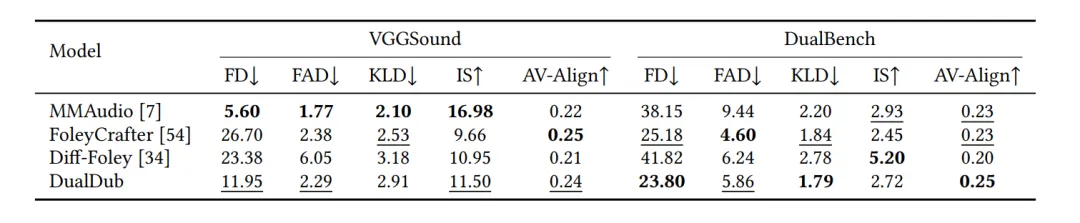
Video-to-Audio
本文对比了单独的Video-to-Audio任务,DualDub在能够实现Video-to-SoundTrack的同时,在单独的Audio generation上也能实现不错的表现。
Video-to-Speech
本文对Video-to-Speech任务也做了实验,DualDub在音频质量以及WER上有明显提升,体现了在零样本文本转语音任务中利用语言模型的优势,展示了DualDub强大的语音生成能力。
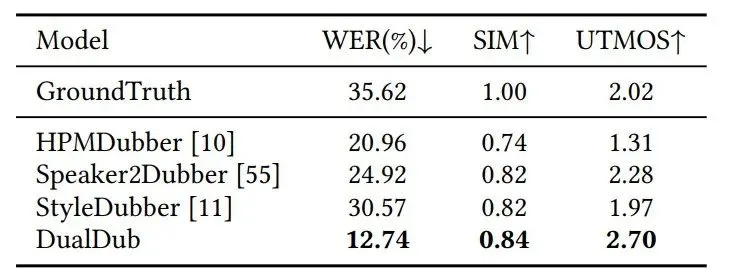
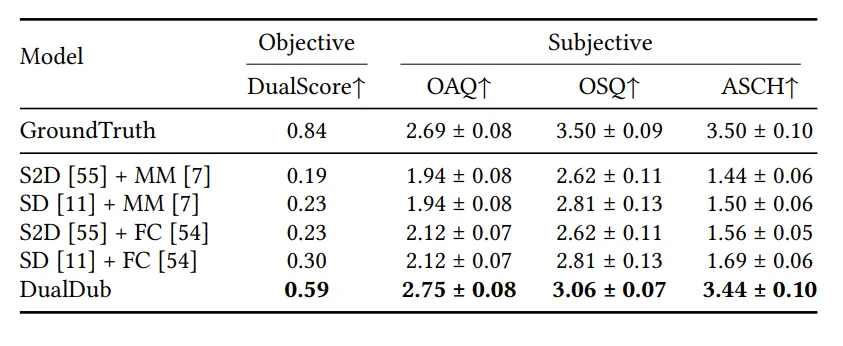
Video-to-SoundTrack
实验表明,由于加入了对多种模态以及任务的同时训练,DualDub在生成的Speech和Background Audio在和谐度上有明显优势。此外,我们可以发现部分V2A任务的模型,在对白电影场景下的表现较差,但是DualDub能够兼顾各种场景以及实现音轨生成。
参考文献
[1] Shengpeng Ji, Ziyue Jiang, Xize Cheng, Yifu Chen, Minghui Fang, Jialong Zuo, Qian Yang, Ruiqi Li, Ziang Zhang, Xiaoda Yang, Rongjie Huang, Yidi Jiang, Qian Chen, Siqi Zheng, Wen Wang, and Zhou Zhao. 2024. WavTokenizer: an Efficient Acoustic Discrete Codec Tokenizer for Audio Language Modeling. CoRR abs/2408.16532 (2024)
[2] Shun Lei, Yixuan Zhou, Boshi Tang, Max WY Lam, Hangyu Liu, Jingcheng Wu, Shiyin Kang, Zhiyong Wu, Helen Meng, et al. 2024. Songcreator: Lyrics-based universal song generation. Advances in Neural Information Processing Systems 37 (2024), 80107–80140
[3] Honglie Chen, Weidi Xie, Andrea Vedaldi, and Andrew Zisserman. 2020. Vggsound: A large-scale audio-visual dataset. In ICASSP 2020-2020 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 721–725.
[4] Heiga Zen, Viet Dang, Rob Clark, Yu Zhang, Ron J Weiss, Ye Jia, Zhifeng Chen, and Yonghui Wu. 2019. Libritts: A corpus derived from librispeech for text-to-speech. arXiv preprint arXiv:1904.02882 (2019).
[5] Kevin Cai, Chonghua Liu, and David M Chan. 2024. Anim-400K: A Large-Scale Dataset for Automated End to End Dubbing of Video. In ICASSP 2024-2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP). IEEE, 11796–11800.
[6] Alec Radford, Jong Wook Kim, Chris Hallacy, Aditya Ramesh, Gabriel Goh, Sandhini Agarwal, Girish Sastry, Amanda Askell, Pamela Mishkin, Jack Clark, Gretchen Krueger, and Ilya Sutskever. 2021. Learning Transferable Visual Models From Natural Language Supervision. In Proceedings of the 38th International Conference on Machine Learning, ICML 2021, 18-24 July 2021, Virtual Event (Proceedings of Machine Learning Research, Vol. 139), Marina Meila and Tong Zhang (Eds.). PMLR, 8748–8763.
[7] Sanyuan Chen, Yu Wu, Chengyi Wang, Shujie Liu, Daniel Tompkins, Zhuo Chen, and Furu Wei. 2022. Beats: Audio pre-training with acoustic tokenizers. arXiv preprint arXiv:2212.09058 (2022).
[8] Ju-Chiang Wang, Wei-Tsung Lu, and Minz Won. 2023. Mel-Band RoFormer for Music Source Separation. arXiv preprint arXiv:2310.01809 (2023).
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。