
Hugging Face 刚刚发布了FineVision,这是一个开放的多模态数据集,旨在为视觉语言模型 (VLM) 树立新标准。FineVision 拥有1730 万张图片、2430 万个样本、8890 万个问答轮换和近100 亿个答案标记,使其成为规模最大、结构最完善的公开 VLM 训练数据集之一。
FineVision 将 200 多个数据源聚合成统一的格式,并严格过滤重复数据和基准污染。该数据集通过多个质量维度进行系统评级,使研究人员和开发者能够构建强大的训练混合模型,同时最大限度地减少数据泄露。
为什么 FineVision 对于 VLM 培训很重要?
大多数最先进的可变长度模型 (VLM) 依赖于专有数据集,限制了更广泛研究群体的可重复性和可访问性。FineVision 通过以下方式弥补了这一缺陷:
- 规模和覆盖范围:9 个类别的 5 TB 精选数据,包括通用 VQA、OCR QA、图表和表格推理、科学、字幕、基础和计数以及 GUI 导航。
- 基准增益:在11 个广泛使用的基准(例如 AI2D、ChartQA、DocVQA、ScienceQA、OCRBench)中,在 FineVision 上训练的模型的表现明显优于其他替代方案 –比 LLaVA 高出 46.3%,比 Cauldron 高出 40.7%,比 Cambrian 高出 12.1%。
- 新技能领域:FineVision 引入了用于 GUI 导航、指向和计数等新兴任务的数据,将 VLM 的功能扩展到传统字幕和 VQA 之外。
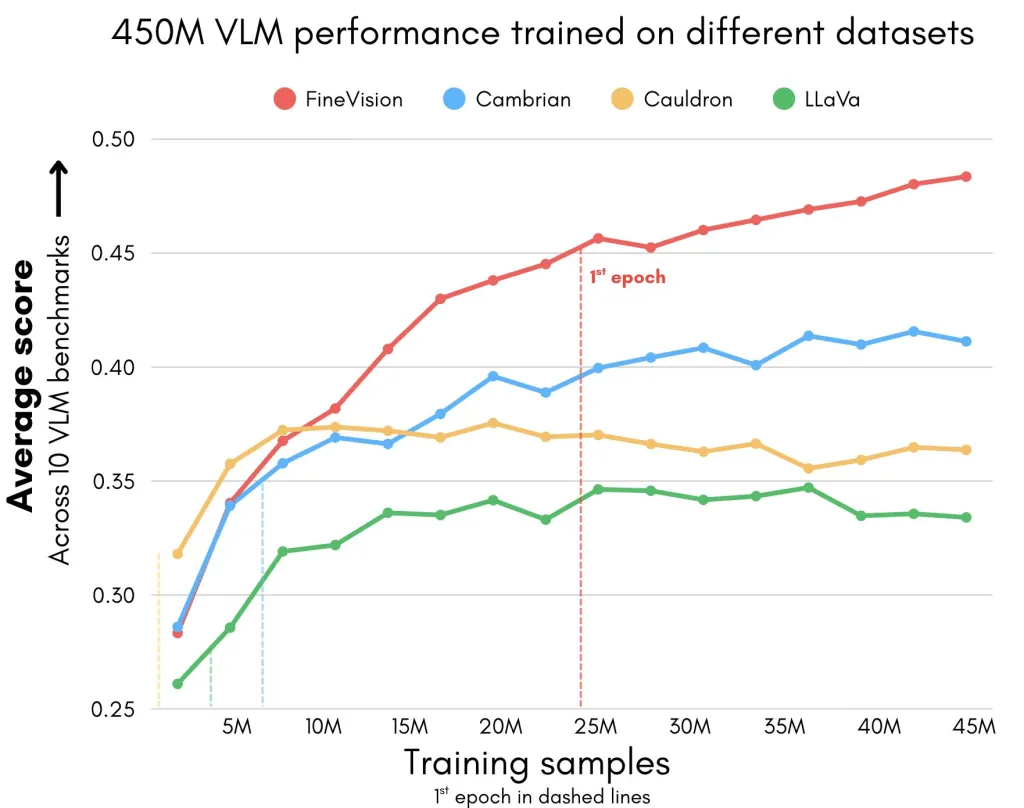

FineVision 是如何构建的?
数据整理流程遵循三个步骤:
- 收集与增强:
我们收集了超过 200 个公开的图像文本数据集。缺失的模态数据(例如纯文本数据)被重新格式化为问答对。代表性不足的领域(例如 GUI 数据)则通过有针对性的收集进行补充。 - 清洗
- 删除了过大的 QA 对(>8192 个标记)。
- 将大图像调整为最大 2048 像素,同时保持纵横比。
- 丢弃损坏的样本。
- 质量评级
使用Qwen3-32B和Qwen2.5-VL-32B-Instruct作为评判标准,对每个 QA 对进行以下四个方面的评级:- 文本格式质量
- 问答相关性
- 视觉依赖性
- 图像-问题对应
这些评级使得选择性训练混合成为可能,尽管消融表明保留所有样本可获得最佳性能,即使包含评级较低的样本也是如此。
性能洞察
- 模型设置:使用nanoVLM(460M 参数)进行消融,结合SmolLM2-360M-Instruct作为语言主干,SigLIP2-Base-512作为视觉编码器。
- 训练效率:在 32 个 NVIDIA H100 GPU 上,一个完整的时期(12k 步)需要约 20 小时。
- 性能趋势:
- FineVision 模型通过接触多样化数据而稳步改进,在约 12k 步后超越了基线。
- 重复数据删除实验证实,与 Cauldron、LLaVA 和 Cambrian 相比,FineVision 的泄漏较低。
- 即使主干是单语的,多语言子集也显示出轻微的性能提升,这表明多样性比严格一致性更重要。
- 多阶段训练(两阶段或 2.5 阶段)的尝试并没有产生一致的好处,这再次证明规模 + 多样性比训练启发式更为重要。
为何 FineVision 树立新标准?
- 平均性能提升 +20%:在 10 多个基准测试中超越所有现有的开放数据集。
- 前所未有的规模:1700 万+ 张图像、2400 万+ 个样本、100 亿个令牌。
- 技能扩展:包括 GUI 导航、计数、指向和文档推理。
- 最低数据泄漏:污染率为 1%,而其他数据集的污染率为 2-3%。
- 完全开源:可在 Hugging Face Hub 上通过
datasets库立即使用。
结论
FineVision 标志着开放多模态数据集的重大进步。其大规模、系统化的管理和透明的质量评估,为训练最先进的视觉语言模型奠定了可重复、可扩展的基础。通过减少对专有资源的依赖,FineVision 使研究人员和开发者能够构建具有竞争力的系统,并加速文档分析、视觉推理和代理多模态任务等领域的进展。
参考资料:
https://huggingface.co/datasets/HuggingFaceM4/FineVision
https://huggingface.co/spaces/HuggingFaceM4/FineVision
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/61335.html