
本文提出了一种新的量化方法(ERVQ),其通过码本内和码本间优化来减轻码本崩溃并提高编解码器性能。实验表明,融入到多种神经音频后均能起到较好的性能提升效果。
文章来源:TASLP 2025
论文作者:Rui-Chen Zheng, Hui-Peng Du, Xiao-Hang Jiang, Yang Ai and Zhen-Hua Ling
论文题目:ERVQ: Enhanced Residual Vector Quantization with Intra-and-Inter-Codebook Optimization for Neural Audio Codecs
论文链接:https://ieeexplore.ieee.org/document/11031216
内容整理:刘昱涵
引言
当前的神经音频编解码器通常使用残差矢量量化(RVQ)来离散化音频信号。然而,它们经常会经历码本崩溃的问题,这减小了有效码本大小并导致性能损失。为了解决这个问题,我们提出了增强的残差矢量量化(ERVQ)。
ERVQ 通过码本内和码本间优化来减轻码本崩溃并提高编解码器性能。码本内优化结合了在线聚类策略和码平衡损失,以确保均衡和有效的码本利用率。码本间优化通过最小化连续的量化层之间的相似性来提高量化特征的多样性。
我们的实验表明,ERVQ 显著提高音频编解码器的性能,在不同的模型,采样率和比特率上,实现了更好的质量和泛化能力。 它还在最先进的神经音频编解码器上实现了 100%的码本利用率。进一步的实验表明,通过 ERVQ 策略改进的音频编解码器可以改进统一的语音和文本大语言模型(LLM),在下游zero shot文本到语音任务中生成的语音的自然度有显著的改善。
码本崩溃
RVQ量化器中,其中只有一小部分码向量(即,码本中的条目)接收用于优化的有用梯度。因此,大多数码向量变得无效,既不更新也不使用,导致码本利用不足。
这限制了RVQ进一步扩大码本规模的能力。
核心方法:ERVQ策略
ERVQ通过码本内优化和码本间优化两个层面解决上述问题:
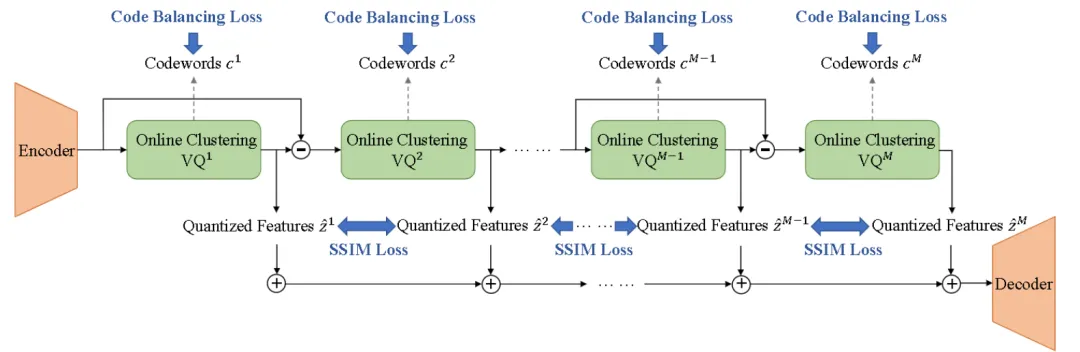

码本内优化
在线聚类策略:
在线聚类策略计算每次迭代时的平均码本使用率,并基于此使用率动态地重新分配码本,确保每个码向量都得到优化。通过动态公式调整码本使用:
- 累积平均使用频率:
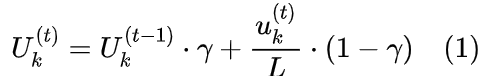
- 衰减系数:
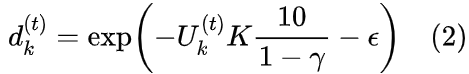
- 码字更新规则:
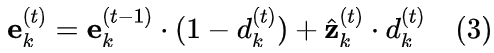
- 概率采样分布:
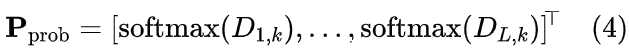
其中
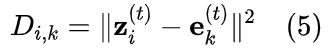
码平衡损失:
码平衡损失假设码应当服从均匀的先验分布,并通过最小化先验和后验码分布之间的差异来提高码本利用率。
其作用是通过损失,使得码本中的每一个向量都有相同的概率被使用,从而最大化码本内部的信息量。
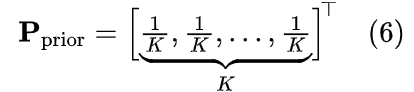
- 先验均匀分布:
- 后验分布估计:
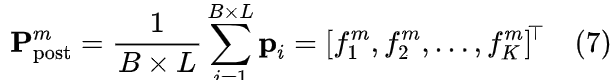
- 码平衡损失:
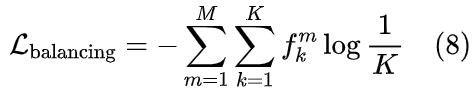
码本间优化
RVQ 是由多个堆叠的 VQ 组成的残差结构。随着 RVQ 的深度增加, RVQ 结构内的不同层上可能会重复关注类似的信号特征。先前的研究,如 SpeechTokenizer ,已经观察到 RVQ 的初始层主要捕获语义相关的特征,而后面的层倾向于编码声学信息。多个vq层可能都集中在类似的声学特性上,例如扬声器特性,而不是使其表示多样化。
所以我们需要最大化由每个相邻 VQ 量化的内容的差异,以减少量化特征之间的信息冗余,并进一步提高 RVQ 的整体表现力,这是通过最小化结构相似性(SSIM)损失的总和来实现的:
- SSIM 计算:
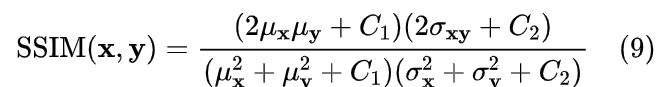
- 相邻量化器之间的损失:
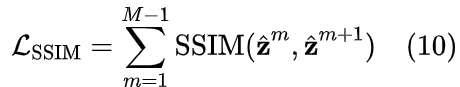
实验设置
模型设置
为了验证我们提出的 ERVQ 策略的有效性和泛化能力,我们将所提出的 ERVQ 策略应用于五个开源音频编解码器。
对于非流式编解码器,我们使用 HiFi-Codec,DAC和 APCodec。对于流式编解码器,我们使用 Encodec和 APCodecS。
我们在 RVQ 中用在线聚类 VQ 模块代替标准 VQ 模块,并在最终的编解码器损失函数中加入了码均衡损失和 SSIM 损失。
当将 ERVQ 策略应用于 Encodec 时,我们用在线聚类策略取代了原始码本重置策略。对于使用 GRVQ 的 HiFi-Codec,将 ERVQ 策略单独应用于 GRVQ 内的每个组,其中将从每个组获得的代码平衡损失和 SSIM 损失组合用于梯度反向传播。对于 DAC 和 APCodec,我们保留了原始的因子分解和 L2 归一化码策略,直接将 ERVQ 策略与它们集成。
数据集设置
| 数据集 | 采样率 | 场景 | 训练/验证/测试规模 | 备注 |
|---|---|---|---|---|
| VCTK-0.92 | 48 kHz(并下采样至 24 kHz / 16 kHz) | 英文多说话人朗读 | 训练:40 936 句,100 人 测试:2 937 句,8 人 | 主实验、通用音频编码评测 |
| LibriTTS | 16 kHz | 英文有声书 | 官方划分:train-clean-100+360 dev-clean / test-clean | 补充实验,验证大规模数据上的效果 |
| FSD50K | 44.1 kHz | 通用声音事件(非语音) | 训练:40 966 句 测试:10 231 句 | 验证非语音场景的泛化能力 |
| Opencpop | 44.1 kHz | 中文高质量流行歌曲 | 训练:3 367 句 测试:389 句 | 验证音乐/歌声场景 |
| LibriTTS(LLM 实验) | 16 kHz | 英文有声书 | 585 h 官方划分 | 用于 LauraGPT 零样本文本转语音任务 |
客观指标
| 指标 | 全称 | 适用范围 | 含义/数值范围 |
|---|---|---|---|
| ViSQOL | Virtual Speech Quality Objective Listener | 48 kHz & 16 kHz 直接测;24 kHz 需先上采样到 48 kHz | MOS-LQO,1–5(16 kHz)或 1–4.75(48 kHz),越高越好 |
| STOI | Short-Time Objective Intelligibility | 通用 | 0–1,越高越清晰 |
| LSD | Log-Spectral Distance | 通用 | dB 值,越低谱失真越小 |
| CER / WER | Character/Word Error Rate | LLM 零样本文本转语音 | % 越低,内容保真度越高 |
| SS | Speaker Similarity | LLM 实验 | Cosine 相似度 0–1,越高越像提示说话人 |
| UTMOS | UTokyo-SaruLab MOS | LLM 实验 | 非侵入式自然度评分,1–5 |
实验结果
1. 客观指标
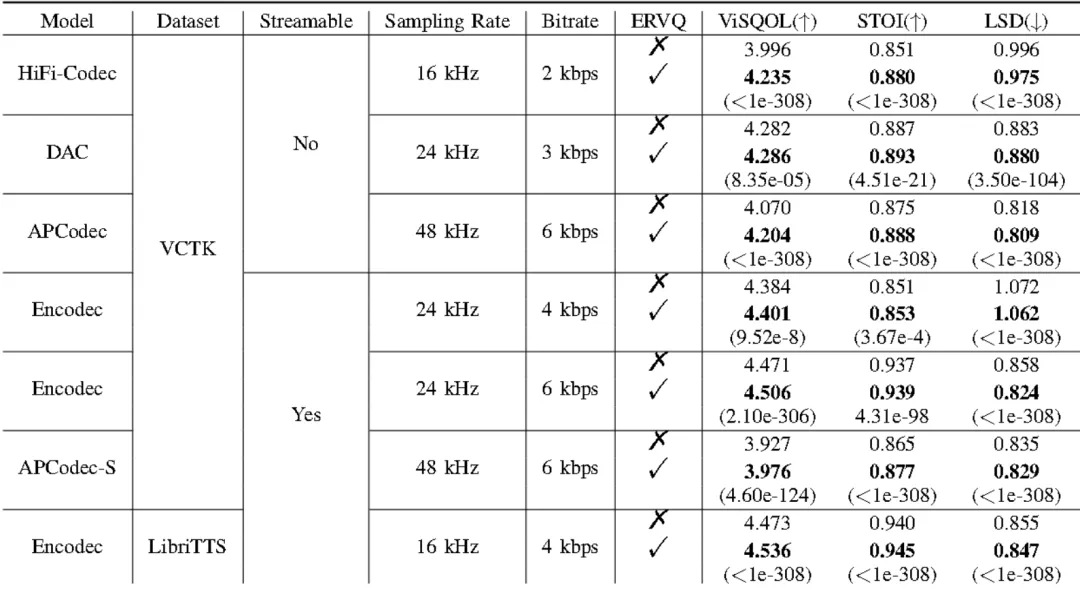
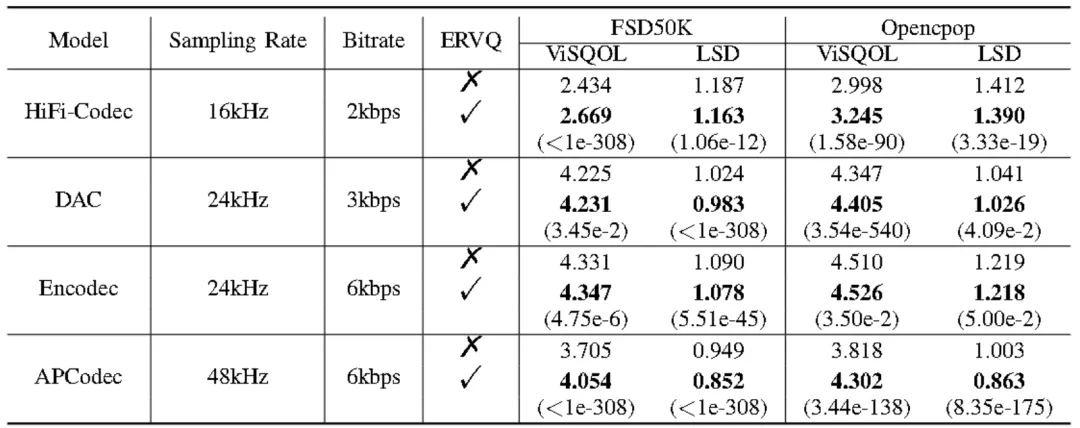
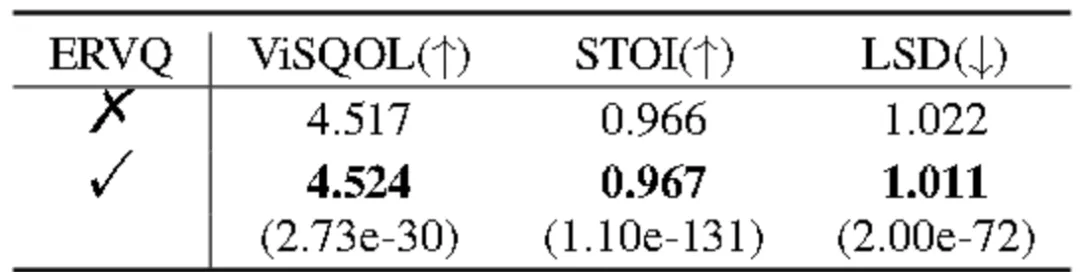
在各种模型结构和比特率下,利用我们提出的 ERVQ 策略的神经音频编解码器在语音编码性能方面始终优于所有基线,其中 HiFi-Codec,APCodec 和 Encodec 的改进尤为显着。
表1中的第五行和第六行之间的比较示出了所提出的 ERVQ 策略对量化级的数量或比特率约束不敏感。表 I 的最后一行所示,ERVQ 在 LibriTTS 数据集上继续产生相对于基线的一致改进,证明了其在不同数据集规模上的有效性。在 FSD 50K 和 Opencpop 测试集上进行评估时也观察到类似的趋势,如表 II 所示,进一步证实了 ERVQ 策略在音频编码中的有效性。 所有指标的改善都具有统计学显著性,配对 t 检验中 p 值<0.05。
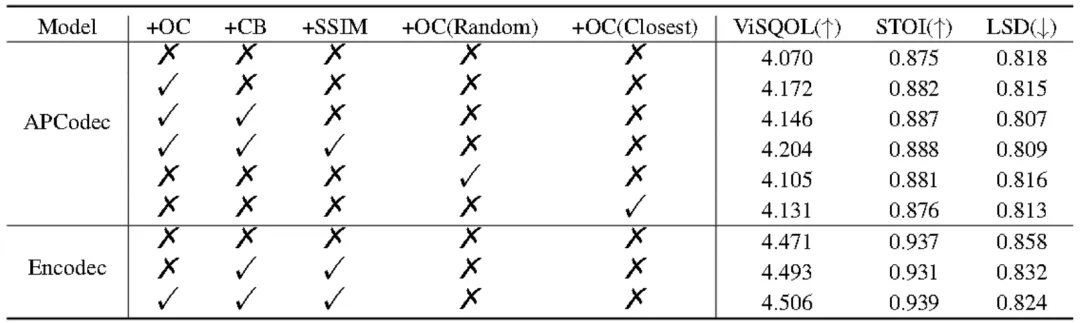
在线聚类策略显着提高了系统性能.合并代码平衡损失进一步提高了可理解性,ViSQOL 分数略有下降,但 STOI 和 LSD 的改善表明可理解性和频谱保真度增强。这表明 CB 损失促进了更有效的代码使用。此外,引入 SSIM 损失显著提高了语音的整体质量和可懂度。此外,当仅应用代码平衡损失和 SSIM 损失时,在 Encodec 上观察到较差的结果,突出了在线聚类策略优于码本重置策略。这些发现共同验证了 ERVQ 框架中每个组件的有效性。
除了上述概率随机抽样方法外,还探索了两种额外的抽样方法:最近抽样和随机抽样。
我们的结果表明,采样方法的选择可能会显著影响音频编解码器的整体性能。不同抽样方法的 ViSQOL 评分配对 t 检验表明,概率随机抽样方法与随机和最接近方法之间的差异具有统计学意义(p < 0.05)。
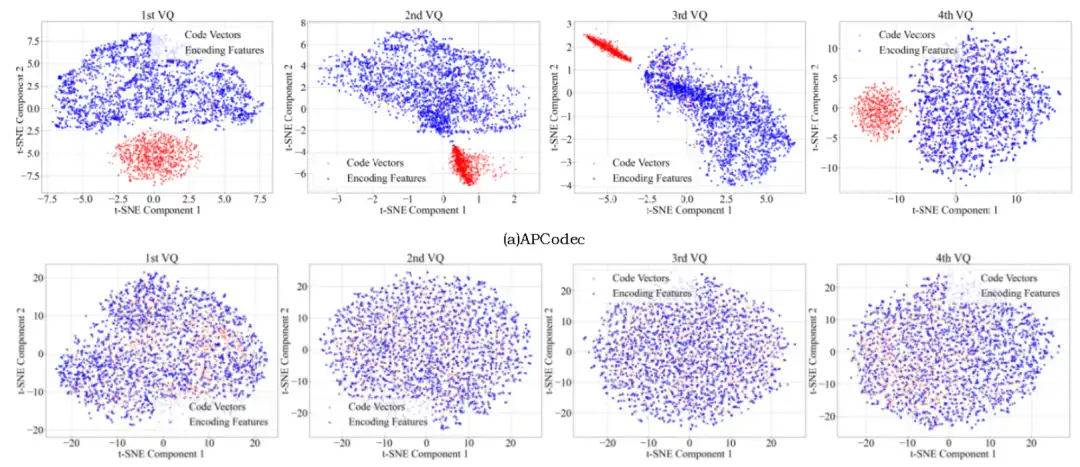
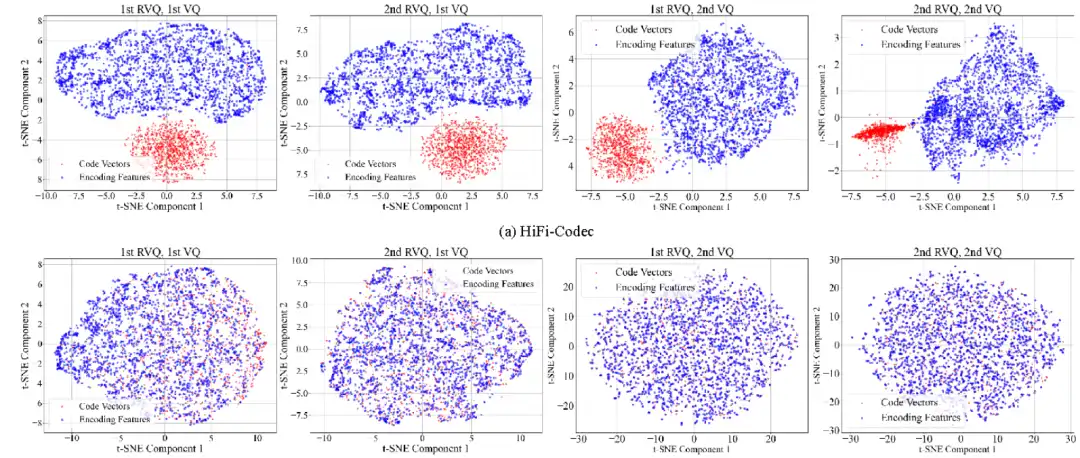
码本利用率分析
ERVQ实现了码本利用率的显著提升:
- APCodec的码本利用率从14.7%~41.2%提升至100%
- HiFi-Codec中第一VQ的利用率从6.05%提升至98.6%
- 比特效率提升超过27%


主观实验
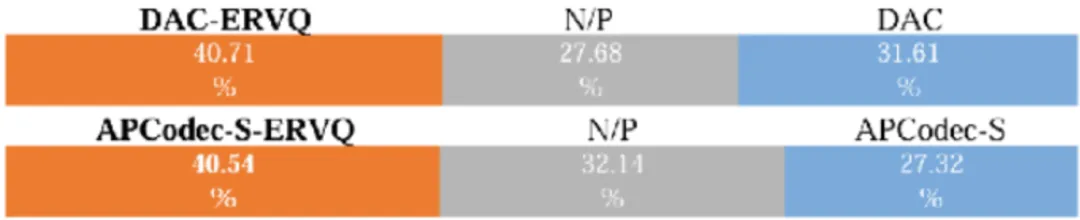
我们进一步在 Amazon Mechanical Turk 平台上进行了 ABX 偏好收听测试,以主观评估采用 ERVQ 策略前后的音频编解码器。具体来说,在每个 ABX 测试中,从原始和 ERVQ 增强的音频集中随机选择 20 个话语,并由至少 20 个母语英语听众进行评估。听众被要求判断每一对中哪一个话语的语音质量更好,或者是否没有偏好。
下游任务提升

结果表明,使用 ERVQ 增强的 FunCodec 生成的编解码器令牌训练 LauraGPT 显着提高了 zeroshot TTS 性能,特别是在自然度和扬声器相似性方面。它使音频编解码器能够学习和保留更多的语音细节,使 LauraGPT 能够产生更具表现力和情感丰富的语音。实验结果也证明了 ERVQ 策略在增强音频编解码器中 RVQ 模块的学习能力方面的有效性,表明了其在实际应用中的潜力。
总结
在这项研究中,我们引入了 ERVQ,旨在增强神经音频编解码器中使用的 RVQ 框架。通过码本内和码本间的优化,ERVQ 确保更平衡和有效的码本利用率。我们对各种音频编解码器的广泛实验证实,ERVQ 始终提高了音频压缩和重构的性能和质量。此外,ERVQ 增强型音频编解码器集成到统一的语音和文本 LLM 中,对下游 zeroshot TTS 任务也进行了显着增强,强调了其实用性。我们未来的工作旨在优化音频编解码器中的 RVQ 结构,以防止过多的音频信息被量化并存储在第一 VQ 中,从而提高音频编解码器的量化能力。扩展 ERVQ 标量量化框架也可以是一个有前途的未来方向。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。