
如何构建一个能够理解数千种语言(包括许多以前从未有过有效自动语音识别 (ASR )模型的语言)的语音识别系统? Meta AI 发布了 Omnilingual ASR,这是一个开源的语音识别套件,可扩展到 1600 多种语言,并且只需少量语音文本示例即可扩展到以前未见过的语言,无需重新训练模型。
数据和语言覆盖范围
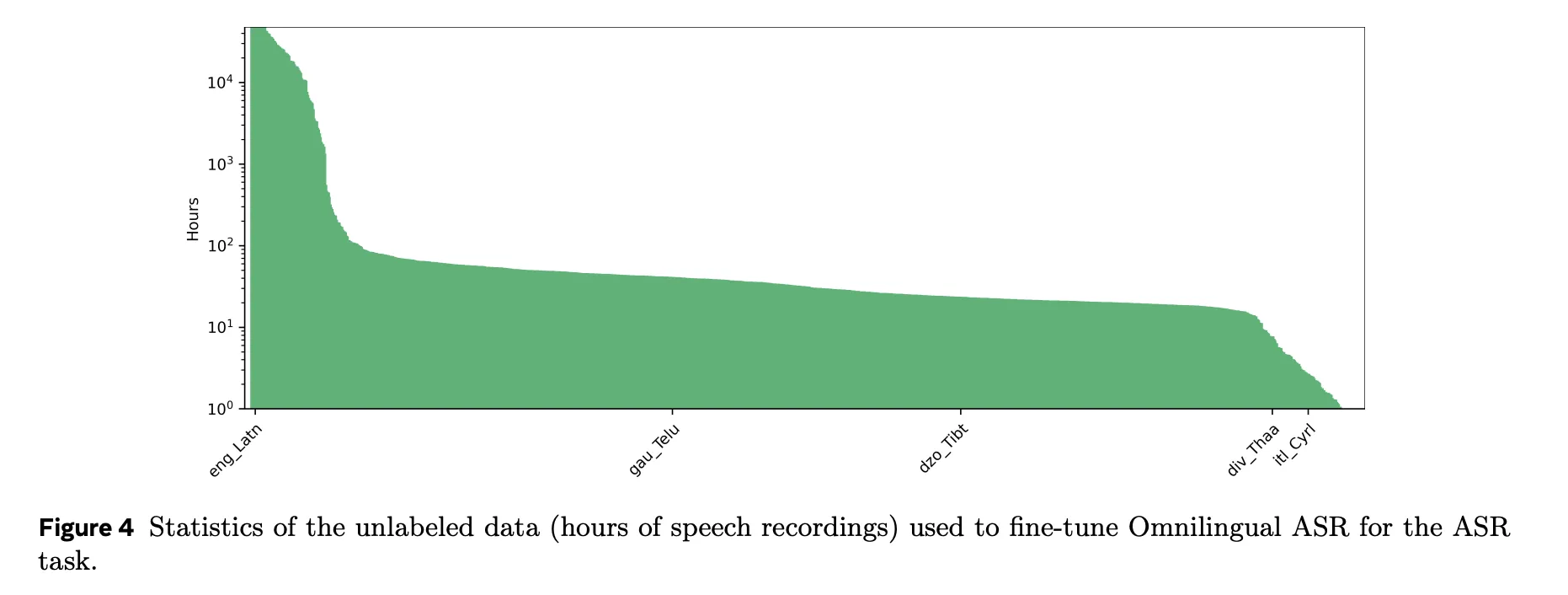
监督式训练数据来自一个名为 AllASR 的综合语料库。AllASR 包含 120,710 小时的带标签语音及其对应的转录文本,涵盖 1,690 种语言。该语料库整合了多个来源,包括开源数据集、内部和授权语料库、合作伙伴创建的数据以及一个名为Omnilingual ASR Corpus 的委托收集的语料库。
全语言自动语音识别语料库(Omnilingual ASR Corpus)包含348种语言的3350小时语音数据,这些数据是通过与非洲和南亚等地区的当地组织和说话者合作开展的实地调研收集的。提示语是开放式的,因此说话者可以用自己的语言自然地进行独白,而不是朗读固定的句子,这能够提供更真实的语音和词汇变化。


对于自监督预训练,wav2vec 2.0 编码器在一个大型未标注语音语料库上进行训练。该预训练数据集包含 384 万小时的语音,涵盖 1239 种语言,并已进行语言识别;此外,还包含 46 万小时的未标注语音。因此,用于预训练的未标注音频总量约为 430 万小时。这仍然远小于 USM 使用的 1200 万小时,因此从数据效率的角度来看,本文报告的结果更具吸引力。
模型家族
全语言ASR提供3个主要模型家族,它们均共享相同的wav2vec 2.0语音编码器骨干:
1. SSL编码器(OmniASR W2V)
具有以下参数数量的自监督wav2vec 2.0编码器:
- omniASR_W2V_300M:317,390,592个参数
- omniASR_W2V_1B:965,514,752个参数
- omniASR_W2V_3B:3,064,124,672个参数
- omniASR_W2V_7B:6,488,487,168个参数。
这些模型采用标准wav2vec 2.0对比目标进行训练。训练完成后,量化器被舍弃,编码器作为语音表示骨干网络使用。
2. 连接时序分类 (CTC ) ASR
模型在编码器之上添加了一个简单的线性层,并使用字符级 CTC 损失进行端到端训练。已发布的 CTC 模型参数量从 325,494,996 到 6,504,786,132 不等,对于 A100 上的 300M 模型,在批大小为 1 的情况下处理 30 秒音频,实时性指标可低至 0.001。
3. LLM ASR模型
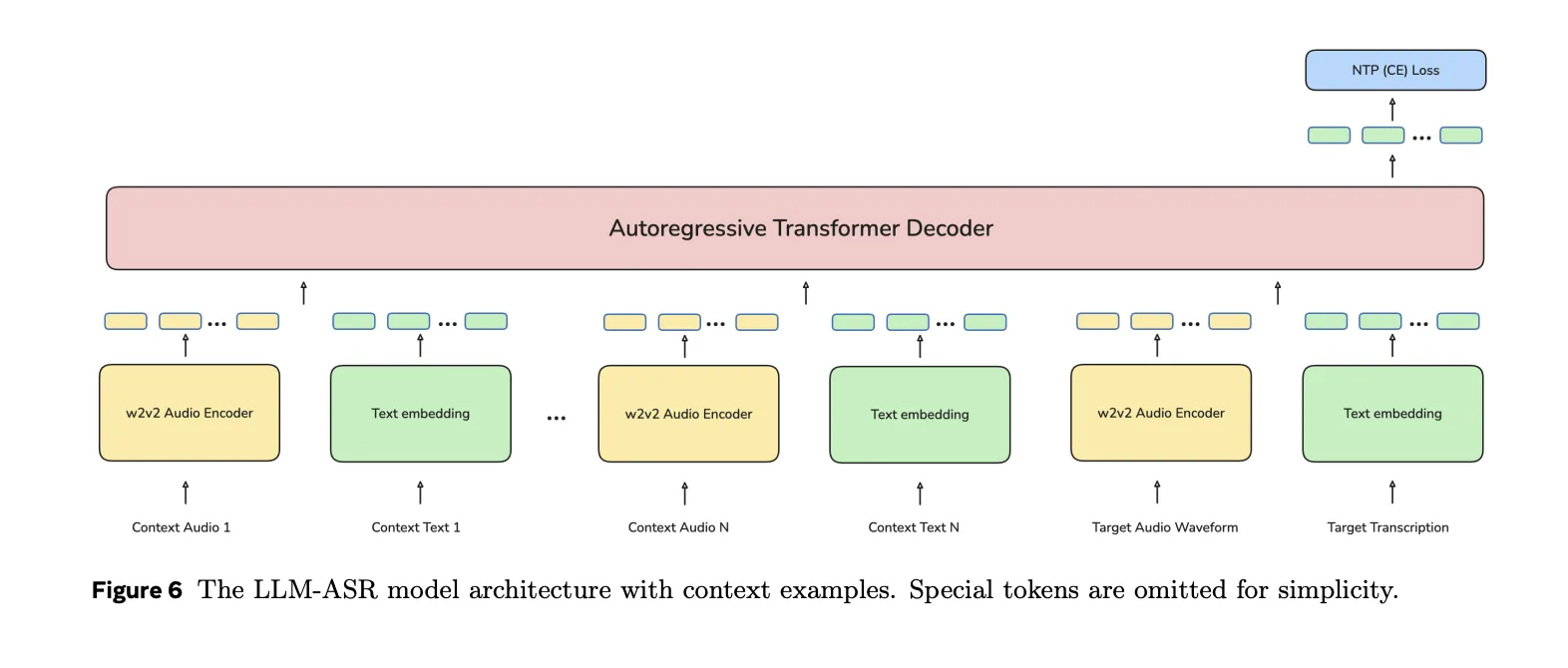
LLM ASR在wav2vec 2.0编码器之上叠加Transformer解码器。解码器采用类似Transformer的语言模型架构,处理字符级标记及<BOS>、<EOS>等特殊标记。训练采用标准下一标记预测机制,处理序列形式为gs(x), gt(<BOS>), gt(y), gt(<EOS>),其中gs为语音编码器,gt为文本嵌入矩阵。LLM ASR系列模型参数规模从omniASR_LLM_300M的约16.3亿参数,到omniASR_LLM_7B的7,801,041,536个参数。其中独立的omniASR_LLM_7B_ZS检查点(参数数7,810,900,608)专用于零样本ASR任务。
所有LLM ASR模型均支持可选语言条件设置。语言以{language_code}_{script}形式表示,例如英语拉丁字符集为eng_Latn,简体中文为cmn_Hans。模型会将针对语言字符集标识符训练出的嵌入向量注入解码器输入。训练过程中语言ID令牌有时会被丢弃,因此模型在推理时也可在无显式语言标签的情况下运行。
基于上下文示例与SONAR技术的零样本ASR
监督学习模型覆盖超过 1600 种语言。然而,许多语言仍缺乏转录的 ASR 数据。为解决此类场景,Omnilingual ASR 通过上下文示例训练的零样本模式扩展了 LLM ASR 模型。
在零样本变体训练过程中,解码器消耗来自同一语言的 N+1 组语音文本对。前 N 组数据作为上下文,末组数据作为目标文本。所有数据经语音编码器与文本嵌入矩阵处理后,拼接成单一解码器输入序列。损失函数仍采用目标转写文本的下一个词预测机制。此机制使解码器能够通过少量同语言示例提示,推断特定语言中语音到文本的映射关系。
在推理阶段,omniASR_LLM_7B_ZS 模型可接收任意语言的少量语音文本示例(包括未参与训练的语言),随后无需更新权重即可转录该语言的新语音。这体现了 ASR 的上下文学习能力。
该系统包含基于 SONAR 的多语言多模态编码器示例检索机制,该编码器将音频与文本投影至共享嵌入空间。目标音频经单次嵌入后,通过在语音文本对数据库中进行最近邻搜索,筛选出最相关的示例纳入上下文窗口。相较于随机示例选择或简单文本相似度匹配,这种基于 SONAR 的筛选机制显著提升了零样本性能。
质量与基准测试
在支持的 1600 多种语言中,omniASR_LLM_7B 模型有 78% 的语言实现了低于 10% 的字符错误率。
研究团队报告称,在 FLEURS 102 等多语言基准测试中,该 7B LLM 语音识别模型不仅超越了 7B CTC 模型,更在平均字符错误率上胜过谷歌 USM 变体——尽管其仅使用约 430 万小时无标签数据(而非1200万小时),且采用更简化的预训练流程。这表明扩展 wav2vec 2.0 编码器并添加 LLM 风格解码器,是实现高覆盖率多语言 ASR 的有效路径。
要点总结
- Omnilingual ASR 提供超过 1600 种语言的开源 ASR 覆盖范围,并且可以使用零样本上下文学习推广到超过 5400 种语言。
- 这些模型基于大规模的 wav2vec 2.0 编码器构建,这些编码器使用来自 1,239 种已标注语言的约 430 万小时未标注音频以及额外的未标注语音进行训练。
- 该套件包括 wav2vec 2.0 编码器、CTC ASR、LLM ASR 和专用零样本 LLM ASR 模型,编码器大小从 300M 到 7B 参数,LLM ASR 最大可达约 7.8B 参数。
- 7B LLM ASR 模型在 1600 多种受支持的语言中,有 78% 的语言字符错误率低于 10%,这在资源匮乏的环境中与之前的多语言系统相比具有竞争力或更胜一筹。
Omnilingual ASR 是一项意义重大的系统级贡献,因为它将多语言 ASR 视为一个可扩展的框架,而非固定的语言列表。它结合了 7B wav2vec 2.0 编码器、CTC 和 LLM ASR 解码器,以及一个零样本 LLM ASR 模型,该模型只需少量上下文示例即可适应新语言,同时在超过 1600 种支持的语言中,78% 的语言字符错误率低于 10%。此外,它还以 Apache 2.0 和 CC BY 4.0 许可发布。总而言之,此次发布使 Omnilingual ASR 成为目前最具扩展性的开源语音识别模型。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/62910.html