
大型语言模型 (LLM) 的预训练效率和泛化能力受到底层训练语料库质量和多样性的显著影响。传统的数据管理流程通常将质量和多样性视为独立的目标,先进行质量过滤,然后再进行领域平衡。这种顺序优化忽略了这些因素之间复杂的相互依赖关系。高质量数据集经常表现出领域偏差,而多样化数据集可能会损害质量。在固定训练预算的背景下,迫切需要同时优化这两个维度,以最大限度地提高模型性能。然而,定义并联合优化质量和多样性仍然是一项艰巨的挑战。
字节跳动推出 QuaDMix
字节跳动推出了 QuaDMix,这是一个统一的数据选择框架,能够在 LLM 预训练过程中系统地平衡质量和多样性。QuaDMix 根据多个质量标准和领域分类评估每个数据样本,并通过参数化函数确定其采样概率。该框架采用代理模型实验结合基于 LightGBM 的回归模型来预测下游性能,从而实现高效的参数优化,而无需进行大规模的穷举训练。实验表明,与分别优化质量和多样性的方法相比,QuaDMix 在多个基准测试中实现了 7.2% 的平均性能提升,彰显了联合方法的有效性。
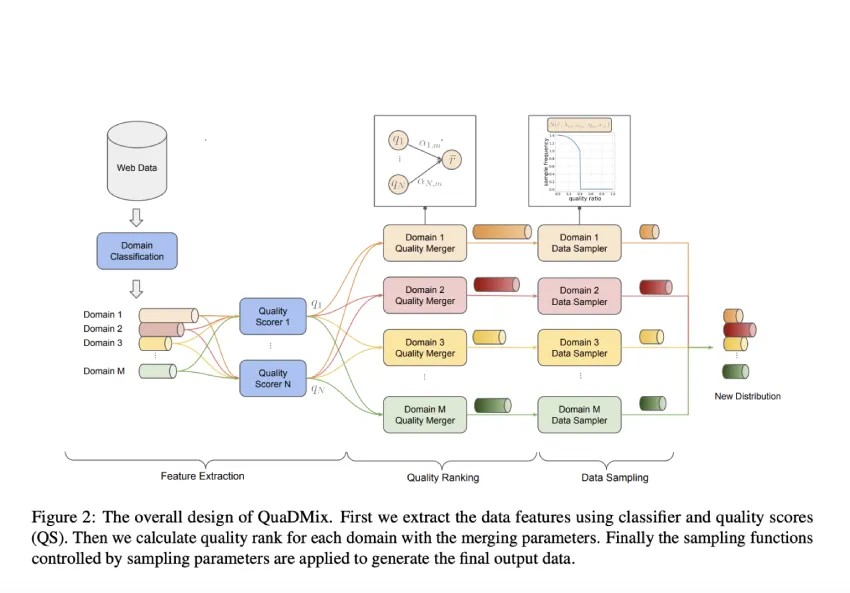

QuaDMix 的运行主要分为三个阶段:特征提取、质量聚合和质量多样性感知采样。首先,每个文档都标注有领域标签和多个质量分数。这些分数经过归一化处理,并使用特定领域的参数进行合并,以计算出聚合质量分数。随后,根据基于 S 型函数的文档采样,该函数优先考虑质量较高的样本,同时通过参数化控制保持领域平衡。
优化是通过在不同参数设置下训练数千个代理模型来实现的。基于这些代理实验训练的回归模型可以预测性能结果,从而确定最佳采样配置。这种方法可以对高维参数空间进行结构化探索,使数据选择与预期的下游任务更加紧密地协调一致。
QuaDMix 具有以下几个优点:
- 数据质量和领域多样性的统一优化。
- 通过代理评估目标选择来适应特定任务的要求。
- 通过规避详尽的全模型再训练来提高计算效率。
- 在不增加计算预算的情况下持续提高下游性能。
实验结果和见解
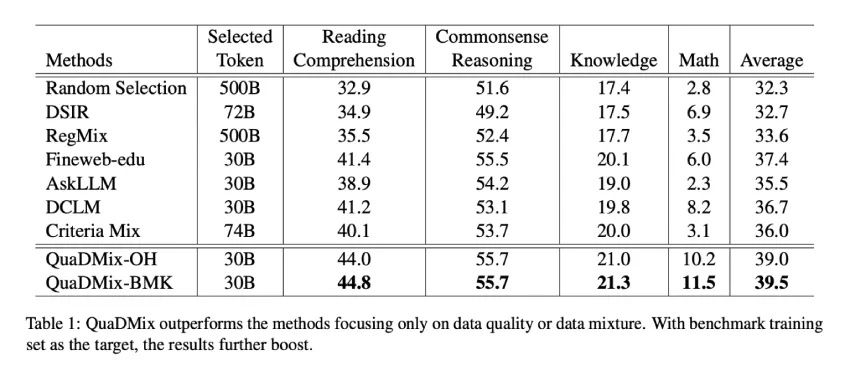
验证实验使用 RefinedWeb 数据集进行,从零开始训练了 5.3 亿个参数模型。QuaDMix 与多个基准方法进行了比较,包括 Random Selection、Fineweb-edu、AskLLM、DCLM、DSIR 和 RegMix。QuaDMix 的表现始终优于这些方法,在九个不同的基准测试中平均得分达到 39.5%。
主要观察结果包括:
- 联合优化策略始终优于孤立的以质量或多样性为重点的方法。
- 代理模型性能与大规模模型结果密切相关,验证了基于代理的方法的有效性。
- 针对特定下游任务优化的数据混合进一步提高了任务性能。
- 合并多个质量标准可以减少固有偏见并提高整体模型的稳健性。
- 将token多样性扩大到超过某个阈值会导致收益递减,强调了策划质量比纯粹数量的重要性。
结论
QuaDMix 提供了一种原则性的 LLM 预训练数据选择方法,解决了同时优化数据质量和多样性这一长期存在的挑战。通过在统一框架内集成质量聚合和领域感知采样,并利用基于代理的优化,QuaDMix 建立了一种可扩展的方法来提升 LLM 预训练效率。虽然未来仍有改进的空间,例如优化参数空间和增强代理模型保真度——但 QuaDMix 代表着朝着更系统、更有效的大规模模型开发数据管理策略迈出了重要一步。
论文地址:https://arxiv.org/abs/2504.16511
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/57764.html