
大模型推理正在重新定义AI基础设施。网络,已不再是过去的支撑性基础设施,而是演变为决定大模型推理系统吞吐、尾时延与MaaS综合成本的关键变量。
针对PD分离部署中日益严峻的结构性网络拥塞难题,智谱、驭驯网络与清华大学开展联合攻关,提出并在线上生产环境落地了ZCube组网架构。实践表明,架构层的系统创新,是释放硬件潜能最经济、最优雅的路径。
在GLM-5.1 coding生产环境的基准测试中,ZCube实现了纯粹靠架构调优带来的跨越:
- 成本优化: GPU、软件栈及应用保持不变,交换机与光模块资本支出减少33%;
- 吞吐提升: GPU平均推理吞吐提升15%;
- 时延改善: TTFT P99降低40.6%。
拥塞的根源在于推理流量模式的变化。 随着PD分离成为主流,KV Cache的跨节点传输使推理流量呈现出源端、目的端和流量规模动态变化的不对称特征。传统ROFT(Rail-Optimized Fat-Tree)架构的静态拓扑与端口映射,极易引发局部热点、队列堆积和PFC反压,进而形成“总带宽宽裕、局部频繁拥塞”的结构性问题。
ZCube的破局之道在于“以动制动”,采用全网扁平化拓扑,结合单/多轨混合接入机制,在结构层面对PD流量进行全局解耦与离散化路由,从根本上降低了结构性拥塞的发生概率,为下一代超大规模推理集群提供了更高效的网络底座。


网络正在影响推理系统的有效吞吐
当集群中数千张GPU同时为线上推理请求服务时,每一次KV Cache传输、每一次数据同步,都会经过GPU之间的互联网络。随着长上下文推理和PD分离推理逐渐成为主流,Prefill与Decode节点之间的数据交换持续增加,网络带宽及其有效利用能力开始直接影响集群吞吐和时延。为量化网络对推理性能的影响,我们首先在一个使用32卡的推理服务上进行了控制变量实验:保持GPU算力、软件栈、模型和应用逻辑不变,仅调整网卡可用带宽上限,并观察集群整体吞吐和首Token时延变化:
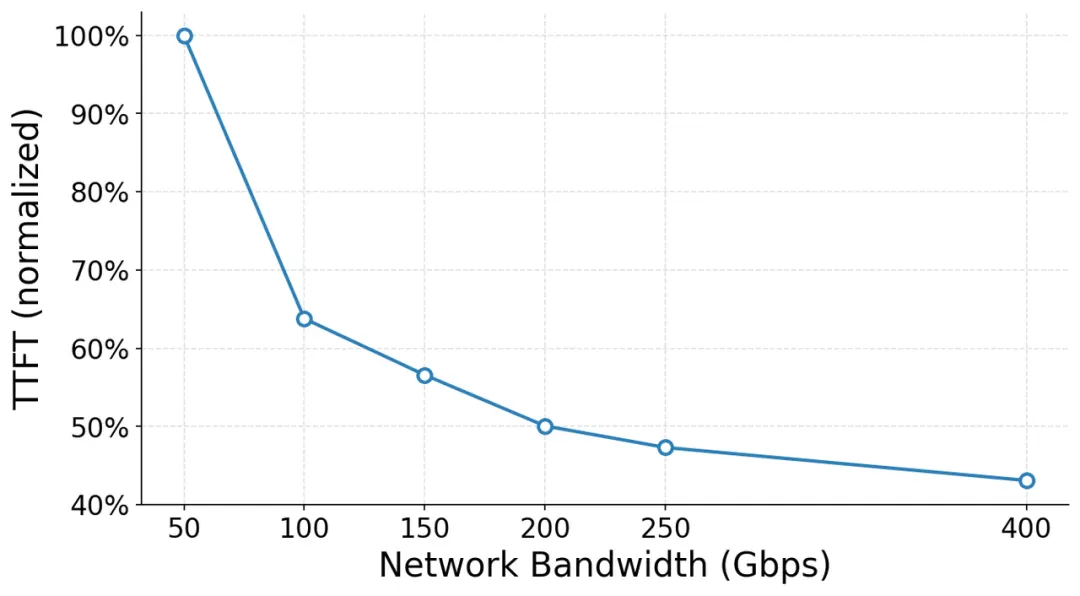

例如,网络带宽从100Gbps提升到200Gbps后,推理总吞吐(throughput)提升约19%,首Token时延(TTFT)下降约22%。这说明,在大模型推理中,网络带宽已经成为制约服务性能的核心因素之一。
推理网络拥塞
当前业界普遍采用Clos架构(Fat-Tree)进行智算集群组网,其基本思路是通过多层交换机堆叠实现规模扩展,但Clos的性能高度依赖于交换机之间实现理想的负载均衡。现实中受路由策略和流量模式影响,这种理想状态往往很难成立。例如,很多集群采用的两层Fat-Tree架构(分 Spine 层和 Leaf 层)中,Spine层交换机之间的流量就存在严重负载不均,从而使得上层应用无法得到预期的网络性能。为了减少跨层转发带来的开销,业界常采用ROFT(Rail Optimized Fat-Tree)架构[1]。如图3所示,ROFT架构将所有GPU按照索引号(rail)分组,相同索引号的GPU连接到同一台Leaf交换机,以减少一部分跨Spine的通信代价。

ROFT在部分训练流量模式下能够取得较好的效果,但在PD分离推理场景里,我们观察到了一个更突出的问题:KV Cache传输具有明显的源-目的不对称性。不同GPU、不同网卡承担的通信负载差异很大(如图4所示),这让ROFT的rail映射不再天然等价于负载均衡,反而容易把流量集中到少数Leaf交换机和链路上,引发了链路拥塞和传输性能下降。具体表现为:
- 某些Leaf交换机成为负载热点,使得多条KV Cache传输流量在相同链路上竞争的概率增加,实际传输速率与网卡带宽上限相差较大;
- 某些Leaf交换机的部分出口队列深度持续高位,频繁触发PFC反压,如图5所示;
- 链路拥塞进一步放大尾时延,影响TTFT与整体吞吐。


需要明确的是,网络拥塞可以分为两类(如图6所示):
- 不可避免的拥塞:例如多个 GPU 同时向同一目的地发送数据,在最后一跳链路上必然发生竞争;
- 可避免的拥塞:由拓扑结构、流量映射方式或多路径负载不均导致,本质上属于架构设计问题。

对于第一类问题,我们通常依赖拥塞控制、流量整形等机制来缓解;但对于第二类问题,可以通过实现新的网络传输协议(如adaptive routing[2]、packet spraying[3,4]、MRC[5]),更有效的办法是通过网络架构层面的创新,来避免本不该出现的网络冲突。PD分离推理正是这样一个典型场景:如果组网结构无法适配其流量模式,系统就会周期性地产生负载热点和链路冲突。要真正解决问题,就需要重构推理网络架构本身。
ZCube网络架构
为解决上述问题,我们实践了全新的ZCube组网架构[6],该架构打破了Clos架构中层次化堆叠交换机的传统组网思路,设计了一种完全扁平的方式进行GPU服务器互联。与ZCube架构适配的ZCube路由策略,充分利用了扁平组网的结构特征,可以实现全网交换机之间的完美流量负载均衡,从而极大提升集群的总体网络带宽。ZCube架构相比Clos架构在负载均衡能力方面的这种天然优势,使其无论在训练集群,还是在推理集群,都可以获得性能上的显著提升。而这种优势,还是在ZCube相比Clos减少了三分之一交换机和光模块的成本优势下取得的。基于当前业界的交换机和网卡配置,ZCube可实现数万张甚至数十万张GPU卡规模的扁平组网。
1.ZCube核心架构
如图7所示,ZCube的核心思想是:
- 1. 取消Spine层交换机;
- 2. 将Leaf交换机划分为相同数量的两组(按序号奇偶分为奇数交换机和偶数交换机);
- 3. 两组之间进行完全二部图互联;
- 4. 每张GPU网卡的两个端口分别以单轨和多轨的方式接入这两组中的相应交换机。

设每个GPU对应的网卡都具有两个端口(p=2),一共有n个GPU(GPU与网卡编号相同,为1,2,…,n)。设k为一台交换机连接的GPU数量,交换机总数量为2*n/k(编号为1,2,…,2*n/k)。编号为i的GPU(1<=i<=n)的第一个端口与奇数交换机(编号为 ((i-1) mod (n/k))*2 + 1 )互联;编号为i的GPU的第二个端口与偶数交换机(编号为⌈i/k⌉*2)互联。两组交换机之间,采用完全二分图的形式相连,即每台奇数交换机要与所有偶数交换机连接。双端口网卡配置下ZCube组网架构(p=2,n=32,k=8)如图7所示。
2.ZCube架构特性
网络直径:ZCube架构的网络直径为2跳,即全网GPU经过两台交换机互达,这介于一层交换机组网(1跳,但规模受限)和二层交换机组网(3跳,规模大但延迟高)之间。
负载均衡:首先,ZCube路由策略确保任意一对GPU之间都只有一条最优路径,避免了多路径选路时出现的流量冲突问题。其次,ZCube架构中一组交换机与GPU连接方式为“单轨”(交换机连接连续标号的GPU),另一组交换机与GPU连接方式为“多轨”(交换机连接相同标号的GPU)。这种独特设计,使得ZCube无论在智算训练场景的典型流量模式(如AllReduce,All2All等)下,还是智算推理场景的典型流量模式(流量源-目的对应关系不确定,不同网卡的负载不均),都可以在全网交换机之间实现较为理想的负载均衡,从而从架构层面避免前文提到的“第二类网络拥塞”。如图8所示,在ROFT架构下会发生冲突的流量在ZCube架构下独享整条网络路径,避免拥塞。

扩展性:ZCube架构在保持其良好性能特征的前提下,具有良好的扩展性。比如使用一层容量为51.2T的交换机(128个400Gbps端口),就能构建一个连接16384块400Gbps网卡的ZCube网络。如果使用更高容量的交换机,或者将ZCube网络划分为更多平面,ZCube架构的扩展性会进一步提升,可支持数万甚至数十万块GPU互联。
成本:在相同规模下,ZCube可以比传统Clos/ROFT架构减少约三分之一的交换机和光模块成本,比如对于万卡智算集群,ZCube架构可节省网络硬件投资约2.1亿~6.4亿元,上述特性表明ZCube架构付出更低网络成本的同时还可获得更好的负载均衡与性能表现。
3.集群实测:在降低网络成本的同时提升推理性能
我们在一个运行GLM-5.1 coding推理服务的千卡集群中,将原本部署的ROFT网络架构升级为ZCube网络架构。由于ZCube网络架构取消了传统Clos架构中的Spine层交换机,原有Clos架构下形成的布线模式、IP编址策略、路由策略以及交换机配置方法,均无法直接复用,需要针对ZCube架构进行重新设计。
为了应对这些挑战,驭驯网络团队围绕ZCube架构设计了完整的网络解决方案,开发了ZCube控制器、机房布局设计工具和连线正确性检测程序等自动化工具,实现了机房部署规划、布线正确性校验、配置自动生成与批量下发等能力,有效解决了ZCube部署中的诸多挑战。这是能在极短时间内成功完成大规模生产集群改造的关键因素。
在顺利完成网络架构改造后,我们在该集群运行GLM-5.1 coding推理服务来对ZCube架构进行实测。通过对比改造前后集群推理性能,我们发现,ZCube相比ROFT架构,将GPU的平均推理吞吐率提升了15%以上(如图9所示),TTFT的P99分位数下降了40.6%。


总结来说,对相同规模和配置的GPU及服务器硬件,在不修改任何应用的前提下,组网架构升级为ZCube之后,我们不但节省了1/3的光模块和交换机硬件,而且集群每秒能多服务15%的推理请求。这在当前推理业务暴增、算力资源紧缺的背景下,显得非常具有实用价值。当前,该ZCube集群已稳定运行两周多,在GLM-5.1 coding推理服务中发挥着重要作用。
结语
大模型推理已从单点优化走向系统协同,网络与推理引擎之间的耦合正在加深,成为推理系统的关键组成部分。ZCube的落地实践表明,组网架构创新可以直接释放推理系统的有效产能。通过让网络架构更适配KV Cache传输和PD流量特征,ZCube从源头降低结构性拥塞形成的概率,在提升吞吐、降低延迟的同时改善集群成本效率。
面向下一代大模型基础设施,网络设计将从通用互联走向模型流量驱动的系统协同。长上下文、PD分离、MoE和训推一体正在改变集群内部通信模式,要求网络拓扑、通信库与调度策略围绕真实模型流量共同优化。未来,我们将继续面向更大规模推理与训练集群探索新型智算网络架构,让网络从连接GPU的底层设施,升级为提升Token生产效率、系统稳定性和成本效率的核心能力。
Blog地址:https://z.ai/blog/zcube
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。