
- 在 Meta,WebRTC 为跨平台的实时音频和视频功能提供支持。但在我们的单一仓库(monorepo)中 fork 像 WebRTC 这样的大型开源项目,会带来独特的挑战。随着时间的推移,内部 fork 可能会与上游版本产生偏差,从而无法获得社区的更新。
- 我们将分享如何摆脱这一“fork 陷阱”:从构建支持 50 多个用例安全 A/B 测试的双栈架构,到如今确保我们持续同步上游更新的工作流。
- 这种方法提升了性能、缩小了二进制文件大小并增强了安全性。时至今日,我们仍在使用它对每个新的上游版本进行 A/B 测试,然后再进行发布。
作者:Boris Tsirkin) 、Joachim Reiersen
原文:https://engineering.fb.com/2026/04/09/developer-tools/escaping-the-fork-how-meta-modernized-webrtc-across-50-use-cases/
在 Meta,实时通信 (RTC) 为各种服务提供支持,从全球 Messenger 和 Instagram 视频聊天到 Meta Quest 上的低延迟云游戏和沉浸式 VR 投屏。为了满足数十亿用户的性能需求,我们花费数年时间开发了一个专用的高性能开源 WebRTC 库版本。
永久性地 fork 一个大型开源项目可能会导致一个常见的行业陷阱。起初可能是出于好意:你需要进行特定的内部优化或快速修复一个 bug。但随着时间的推移,上游项目不断发展,你的内部功能也不断积累,合并外部提交所需的资源可能会变得难以承受。
最近,我们正式完成了一项历时多年的大规模迁移,打破了这一恶性循环。我们成功地将 50 多个用例从一个独立的 WebRTC 分支迁移到了基于最新上游版本构建的模块化架构,以上游版本为框架,并注入了我们自主实现的关键组件。
本文详细介绍了我们如何设计解决方案来解决“fork 陷阱”,从而允许我们在单个库中同时构建两个版本的 WebRTC 以进行 A/B 测试,同时在 monorepo 环境中运行,并对正在测试的库进行持续升级。
挑战:单体仓库与静态链接器
升级 WebRTC 这样的库存在一定风险,尤其是在为数十亿用户提供服务的同时进行升级,且可能引入难以回滚的回归问题。此外,由于我们运行的设备和环境种类繁多,这也排除了“一次性升级”的可能性,因为这可能会破坏部分用户的体验。
为缓解这一问题,我们优先构建了 A/B 测试能力,以便在运行新上游版本(附带干净补丁)的同时,继续运行 WebRTC 的旧版本,并在同一应用中应用我们的功能,同时能够动态地在两个版本之间切换用户以验证新版本。
受应用程序构建图和大小限制的制约,我们还优先寻求将两个 WebRTC 版本静态链接的解决方案。但这违反了 C++ 链接器的“单一定义规则”(ODR),导致数千个符号冲突,因此我们转而寻找让同一库的两个版本在同一地址空间中共存的方法。
此外,Meta 采用单体仓库(monorepo)架构,我们不希望重复经历相同的开发流程。这促使我们寻找一种解决方案,以便在单仓库环境中维护开源项目的自定义补丁,同时能够反复从上游拉取新版本并应用这些补丁。
这促使我们专注于解决两个挑战:
- 我们需要A/B测试功能。为了实现这一点,由于应用限制,我们在同一个库中构建了两个WebRTC实例。
- 在单体仓库中没有特性分支的情况下,如何跟踪补丁并进行变基?其他基于 libwebrtc 的开源项目通常会在每次库升级时,将一组存储的补丁文件按顺序应用到干净的仓库之上。出于可扩展性的考虑,我们探索了更细致的方案。
方案 1:Shim 层与双栈架构
为了实现 A/B 测试功能,我们选择在同一个应用程序中构建两个 WebRTC 实例。然而,在同一个全局调用编排库中静态地实现这一点会带来一些独特的挑战。为了解决这个问题,我们在应用层和 WebRTC 之间构建了一个 shim 层。这是一个代理库,位于我们的应用程序代码和底层 WebRTC 实现之间。应用程序不再直接调用 WebRTC,而是调用 shim 的 API。该 shim 层提供了一个统一的、与版本无关的 API。
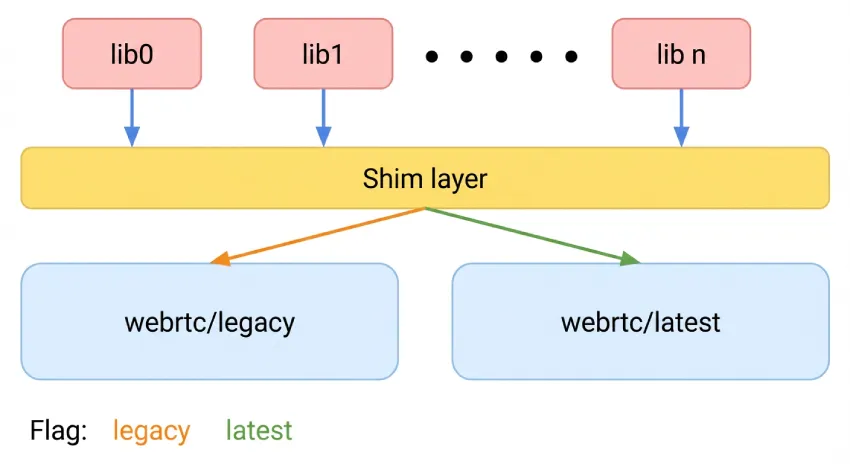

shim 层包含一个“flavor”配置,并在运行时将每个调用分派给旧版或最新的WebRTC 实现。这种方法在尽可能低的层级进行 shim 处理,避免了复制高层调用编排库所导致的二进制文件大小显著增加。复制会导致未压缩的文件大小增加约 38 MB,而我们的解决方案仅增加了约 5 MB,减少了 87%。
接下来,我们将探讨这种双栈架构带来的障碍以及我们是如何解决这些障碍的。
接下来,我们将探讨这种双栈架构带来的难题,以及我们是如何解决这些问题的。
解决符号冲突
将两个 WebRTC 库静态链接到同一个二进制文件中,会产生数千个符号重复错误。

为了确保每个版本中的每个符号都是唯一的,我们采用了自动重命名空间的方法:我们编写了脚本,系统地重写给定 WebRTC 版本中的每个 C++ 命名空间,因此最新上游版本中的 webrtc:: 命名空间变成了 webrtc_latest::,而旧版本则变成了 webrtc_legacy::。这一重命名操作被应用于库中的每个外部命名空间。
但并非 WebRTC 中的所有内容都位于命名空间内,全局 C 函数、自由变量,以及那些有意或无意被置于命名空间之外的类,也会发生冲突。
针对这些情况,我们尽可能将相关内容移入命名空间,并对其余部分(如全局 C 函数)的符号使用特定于版本的标识符进行处理。
宏和预处理器标志则带来了一个更微妙的问题。诸如 RTC_CHECK 和 RTC_LOG 之类的宏可能在 WebRTC 外部的封装库中被使用,因此若在同一个翻译单元中包含两个版本的头文件,就会触发重新定义错误。
我们通过多种策略相结合的方式解决了这个问题:
- 删除不必要的包含项。
- 重命名不常用的宏。
- 尽可能在不同版本之间共享内部 WebRTC 模块,例如rtc_base。这种方法还有一个额外的好处,那就是既减小了二进制文件的大小,又减少了需要进行适配的代码量。

向后兼容性
如果将 WebRTC 中的每个符号都进行命名空间重命名,将会导致所有外部调用点失效。我们的重点是确保现有代码能够正常运行,且不造成中断。有些调用点是基于固定的 WebRTC 版本构建的,而非双栈架构。
我们的初始方案是预先声明新命名空间中所有已使用的符号,并将其与旧命名空间关联起来。虽然这种方法可行,但生成了一个庞大且脆弱的头文件,需要大量维护工作。
经过多次迭代,我们找到了更好的解决方案:利用 C++ 的 using 声明进行批量命名空间导入。通过将整个 flavor 命名空间导入到熟悉的webrtc::命名空间中,我们生成了一份简洁的声明头文件,其中新符号会被自动处理,且由于这些仅是纯编译器指令,因此不会影响二进制文件大小。外部工程师可以完全像以前一样编写代码,关联工作在后台并行进行,仅迁移那些我们关心的外部调用点。
功能亮点:运行时版本调度
由于 shim 层封装了两个 WebRTC 版本,接下来的问题是:如何在运行时调度到正确的版本?每个适配器和转换器都需要根据全局配置标志,实例化正确的底层对象——webrtc_legacy:: 或 webrtc_latest::。
我们通过基于模板的辅助库解决了这一问题。共享逻辑(占适配器代码的大部分)只需编写一次。版本特有的行为则通过 C++ 模板特化来实现。这既保持了代码的 DRY 原则,又在过渡期间支持了与单版本构建的向后兼容性。一个全局的 flavor 枚举在每个应用程序启动序列的早期阶段设置,用于确定要激活的 flavor。
我们使用“directional adapters”作为中间对象,它们实现统一的 API 并分发给底层 WebRTC 对象,反之亦然。使用“directional converters”作为实用函数,在 shim 和 WebRTC 类型系统之间转换结构体和枚举。

Shim 生成
Shim 本身需要适配器和转换器。由于需要为数十个 API 生成大量 Shim 对象,每个对象都需要抽象 API 定义、适配器和转换器的实现以及单元测试,预计人工工作量非常巨大!
我们转而采用自动化方案。利用抽象语法树 (AST) 解析,我们构建了一个代码生成系统,可以为类、结构体、枚举和常量生成基准 shim 代码。生成的代码经过了完整的单元测试,并且易于扩展。这使我们的 shim 生成速度从每天一个提高到每天三到四个,同时降低了人为错误的风险。对于 API 在不同版本之间完全相同的简单 shim,生成的代码几乎不需要任何人工干预。对于更复杂的情况,例如版本之间的 API 差异、工厂模式、静态方法、原始指针语义以及对象所有权转移,工程师们会对生成的基准代码进行优化。
双栈应用的连接和构建
在 shim 层就位后,我们开始了艰辛的重构工作,将所有应用程序引用从直接的 WebRTC 类型转换为对应的 shim 类型。例如,webrtc::Foo 变成了 webrtc_shim::Foo。这引入了对象所有权的复杂性,以及在空值处理和内存管理方面可能出现的隐蔽 bug。我们通过全面的单元测试来缓解这些问题,这些测试模拟了所有权转移和对象生命周期中可能出现的问题场景,并针对特别高风险的差异进行了端到端测试。
随后,我们通过迭代开发的方式,致力于构建双栈模式下的完整应用程序,从小型目标开始逐步推进。每次迭代都会暴露出新的问题:缺失的 shim 层、类型不匹配的对象,以及新的宏或符号冲突。
某些从外部注入到 WebRTC 中的内部组件带来了特殊的挑战,因为它们对 WebRTC 内部机制有着深层的依赖。由于对这些组件进行 shimming 操作意味着 WebRTC 需要代理自身,我们转而使用 C++ 宏和Buck构建机制来“复制”它们。在构建时动态更改命名空间,复制高级构建目标,并通过单个头文件公开两种版本的符号。
完成这些工作后,我们的内部应用以及部分外部应用均已能够以双栈模式构建并运行音视频通话,同时支持旧版和最新版本。
新增了超过 10,000 行的辅助代码,并修改了数千个文件中的数十万行代码。尽管改动范围很大,但由于经过仔细的测试和审查,最终没有出现重大问题。
通过这种方法,我们可以逐个应用地对旧版 WebRTC 和最新版本进行 A/B 测试,从而缓解回归问题,发布新版本并删除旧代码。如今,我们在某些应用中使用 shim 方法,以便能够持续地将内部 WebRTC 代码升级到最新的上游版本。
方案 2:功能分支
由于我们使用的是一个对分支支持有限的单一仓库(monorepo),因此我们寻求一种方法,能够随时间推移追踪补丁,并使其持续基于上游代码进行重置(rebase)。我们的明确要求是,每个补丁都应有明确的用途和负责团队。
对此我们有两种选择:一是追踪提交到源代码控制中的补丁文件,并按正确顺序逐一重新应用;二是将补丁追踪在支持分支功能的独立仓库中。
最终,我们选择在单独的 Git 仓库中跟踪功能分支。其中一个原因是,为了建立一个良好的流程,以便能够非常轻松地向上游提交功能分支和修复程序。
通过基于 libwebrtc Git 仓库,我们可以轻松地重用现有的上游 Chromium 工具进行构建、测试和提交(`gn`、`gclient`、`git cl` 等)。
对于每个上游 Chromium 版本(例如 Git 中标签为 7499 的 M143),我们都会创建一个名为“base/7499”的分支。然后,对于我们提交的每个补丁(例如“debug-tools”),我们会基于 base/7499 的提交创建一个名为“debug-tools/7499”的分支。在版本升级期间,我们会将所有特性分支向前合并,例如将 debug-tools/7499 合并到 debug-tools/7559,将 hw-av1-fixes/7499 合并到 hw-av1-fixes/7599,依此类推。
一旦所有功能都合并到一起,冲突得到解决,并且构建和测试都正常运行,我们就将所有功能分支按顺序合并在一起,以创建发布候选分支 r7559。

这种方法的一些优点包括:分支众多时,它具有高度并行化能力;它能自动保留所有 Git 历史记录/上下文;并且非常适合未来改进基于 LLM 的合并冲突自动解决机制。此外,特性分支使得将整个分支作为上游贡献提交到开源软件项目 (OSS) 变得更加容易。
结果:持续升级
这种架构使我们能够发布包含新旧 WebRTC 协议栈的二进制文件。我们在 M120 版本上发布了 webrtc/latest,之后又升级到了 M145。现在,我们不再落后数年,而是始终与最新的稳定版 Chromium 保持同步,并立即吸收上游的升级。
关键工程项目
- 性能:我们发现 CPU 使用率下降了 10%,主要应用程序的崩溃率降低了 3%。
- 二进制文件大小:新的上游版本效率更高,根据应用程序的不同,可减少 100-200 KB(压缩)的大小。
- 安全性:我们淘汰了已弃用的库(如 usrsctp),并修复了旧版堆栈中存在的安全漏洞。
- 以上所有措施在现代技术栈上运行的同时,都显著提高了用户参与度。
该项目证明,即使在具有各种限制的复杂单体仓库环境中,也可以在不完全重写代码的情况下实现技术债务的现代化。采用双栈方法的 shim 层为任何希望摆脱 fork 陷阱的组织提供了一个蓝图。
未来工作:AI 驱动的维护
随着迁移完成,我们进入了维护的新时代。虽然现在“紧跟最新代码”,但我们仍然会在上游代码的基础上应用内部补丁。为了高效地管理这些补丁,我们正在利用各种工具来实现工作流程的自动化:
- 构建健康:我们正在开发代理程序来自动修复 Git 分支中的构建错误。
- 冲突解决:当我们将补丁重新基于新的 WebRTC 版本时,会遇到合并冲突。我们正在训练 AI 代理来自动解决大部分冲突,只将最复杂的架构变更留给人类工程师处理。
致谢
这项工作是由一支小型工程师团队完成的,他们认识到这个战略项目的价值。尽管项目复杂,他们仍然义无反顾地投入其中。他们提出了许多富有创意的想法和解决方案,承担了繁重的工作,并最终克服了过程中意想不到的障碍和独特的挑战,推动项目顺利完成:Dor Hen、Guy Hershenbaum、Jared Siskin、Liad Rubin、Tal Benesh 和 Yosef Twaik。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/webrtc/66095.html