
利用统一通信服务(UCaaS)提供商提供的大型语言模型(LLM),对于最大限度地提高企业使用的 UCaaS 解决方案的价值和生产率非常必要。本文探讨了在几个 UCaaS 生态系统(包括 Zoom、Cisco Webex、Google Meet 和 Microsoft Teams)中使用 LLM 的情况。
我们编写这篇概述的目的并不是要对这些解决方案进行比较;相反,我们希望重点介绍它们提供的一些有趣功能,并讨论每个解决方案在哪些方面表现出色并给我们留下深刻印象。
本文内容基于作者在 Enterprise Connect 2024 大会上的演讲,分为三篇文章:
- 第 1 部分:生成式人工智能的工作原理和 LLM 的训练方法。
- 第 2 部分:概述 UCaaS 平台的功能,并深入探讨两个关键用例:会议摘要和文本提炼。
- 第 3 部分:讨论在这些 UCaaS 平台中使用 Gen AI 的相关风险。
人工智能无处不在
每个人都在谈论人工智能(AI),所有供应商都在为自己的解决方案添加某种人工智能功能。在这种大肆炒作的情况下,如果一些有进取心的供应商将人工智能添加到我们的 “Smartie-O’s “或卫生纸中,我们也不会感到惊讶。


在 Enterprise Connect 2024 大会的 173 场会议中,有 71 场在会议描述中至少提到过一次人工智能。这是一个适时的话题,也是时候就似乎最重要的问题(至少对我们来说)进行一些直言不讳的讨论了。
人工智能和大型语言模型
在讨论具体的 LLM 及其在 UCaaS 解决方案中的使用方法之前,先简单讨论一下生成式人工智能(Gen AI)的工作原理和 LLM 的训练方法,这样可能会对您有所帮助,您可以了解它们的威力和局限性。为简单起见,我们在下文中交替使用 Gen AI 和 LLM。
首先,Gen AI 及其背后的 LLM 在很大程度上依赖于机器学习(ML)的概念。机器学习可以包括许多子学科,如分类、预测分析、监督和非监督学习以及深度学习。生成式人工智能利用了这些能力,还可能结合其他人工智能技术,包括自然语言处理、视觉、语音转文本、文本转语音等。
神经网络的概念对于训练 LLM 和将其用于 Gen AI 非常重要。将神经网络视为一种试图模仿大脑的计算模型。大脑是一个高度互联的神经元网络。当受到刺激或输入时,这些神经元会发射信号并刺激其他神经元,直到引起某种反应。
计算神经网络模仿大脑,它们接受输入,然后通过数学函数刺激其他层的计算神经元,直到计算出输出。
生成式人工智能模型经过训练,可以识别数据中的模式,然后利用这些模式生成新的但类似的数据模式。例如,如果一个生成式人工智能模型是以英语单词和句子为基础进行训练,那么它就会学习一个单词紧跟另一个单词的统计可能性,然后利用这些概率生成一个连贯的单词序列,我们称之为句子。
生成式人工智能应用于许多不同的学科,包括遗传学、新药开发、语言翻译和图像生成。在本文中,我们将从语言的角度讨论生成式人工智能,包括造句、修改文本、总结文本、根据输入创建基于文本的响应等。
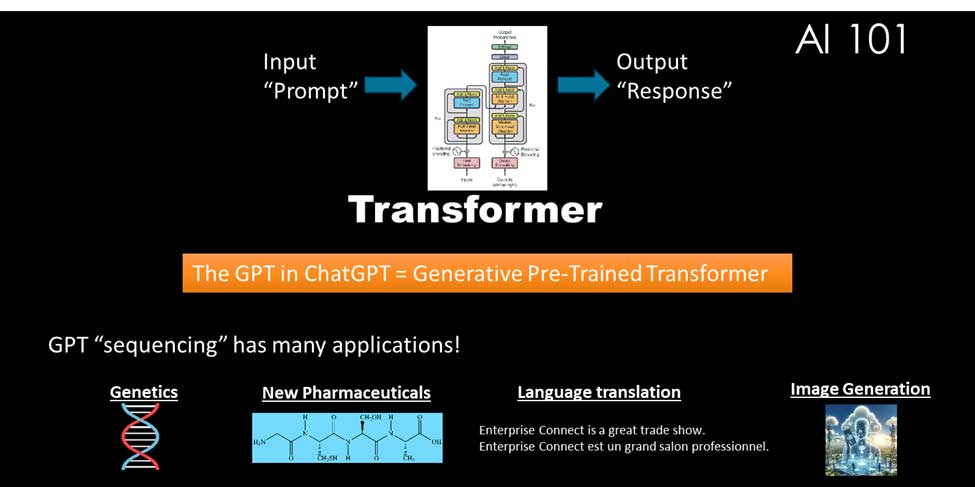
计算机不懂文字
虽然我们一直在讨论文字和语言,但计算机理解的是数字,而不是文字。在训练人工智能生成模型时,单词被编码为数字。单词和单词短语有三个关键方面可用于将单词编码为数字:
- 特定单词的语义。该单词在句子或短语中的上下文中的含义。
- 单词在句子或短语中的位置。这既包括该词与其他词的相对位置,也包括该词在句子中出现的绝对位置。
- 单词在特定句子或短语中的关注度。注意力主要是根据词语在特定句子或短语中与其他词语的相关程度来 “打分”。
标记化
在将单词编码成数字时,LLM 会使用一种称为标记化的概念来创建词汇,并减少训练 LLM 基础神经网络时使用的单个单词的数量。在标记化过程中,不应该将常用词拆分成更小的子词;但是,应该将罕见词分解成有意义的子词。此外,单词的前缀、后缀和常用部分也可以标记化,因为这将减少特定单词的形式数量。
标记化可以有效减少训练模型所需的单词总数,并提高模型训练的计算效率。

训练 LML
构成单词、短语、句子和段落的标记根据语义、位置和注意力编码成一组复杂的数字矩阵,作为神经网络的输入。在训练网络时,输入节点、神经网络隐藏层和输出注释之间的参数会被计算出来。在训练模型时,这种从输入到输出的计算称为前向传播。
计算出输出后,将其与预期输出或目标输出进行比较。计算出的输出与期望输出之间的 “误差”,然后通过一个称为反向传播的过程来调整神经网络的参数。一旦神经网络参数调整完毕,输入将再次通过神经网络,测量误差,并再次调整参数。
前向传播和后向传播的过程一直持续到计算输出与期望输出之间的误差 “很小 “为止,这意味着神经网络能够合理地生成经过训练的结果。
神经网络可以包含不同数量的参数。举例来说,ChatGPT 3.5 中的可调参数数为 17.5 亿。ChatGPT 4 有 1.7 万亿个参数,ChatGPT 4 模型中使用或计算的参数数量增加了十倍。
一旦误差足够小,而且模型性能相当不错,这些计算出的参数就可以用来做一些有趣的事情,比如总结会议内容、确定会议中的行动项目、根据大纲生成文本等等。目前,Gen AI LLM 通常使用基于文本的输入;因此,文本的准确性非常重要,无论它是来自语音转文本、打字还是其他输入机制。
使用训练有素的模型
需要指出的是,Microsoft Copilot、Zoom AI Companion、Cisco AI Assistant for Webex 和 Google Gemini for Workspace 中的 LLM 并未使用贵公司的数据进行训练。当在这些 UCaaS 平台中使用时,这些 Gen AI 解决方案都会使用预训练模型,这些模型是使用构建 LLM 的公司所拥有的数据进行训练的;只有训练过的 LLM 中的参数才会在这些各自的 UCaaS 解决方案中使用。
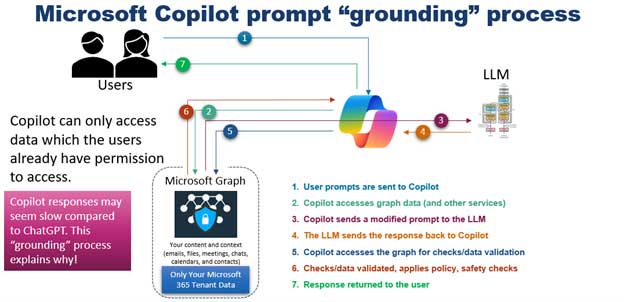
即使 LLM 经过了训练,它也可能无法针对您的特定领域或词汇进行训练。有一些程序可以用来生成更相关的响应,但不会修改经过训练的参数。例如,Microsoft Copilot 使用一种称为 “接地 “的程序来检查您的内容(文件、电子邮件、聊天信息、联系人、日历、会议等)。Copilot 利用这些信息(这些信息可在 Microsoft Graph 中找到)修改您可能向 LLM 发出的提示,从而为 LLM 提供更好的输入措辞和输出信息。
为什么 LLM 会对同一提示给出不同的答案
很多人都想知道,为什么 LLM 会对相同的输入提示给出不同的答案。LLM 有一个名为 “温度 “的可调参数,用于确定输出中可以存在多少随机性。就像人们在被问到完全相同的问题时可能不会给出完全相同的回答一样,LLM 的程序设计也会使它们给出的回答具有一定的随机性或可变性,所有这些都是基于它们所训练的句子和短语中单词之间的概率。
通过调整 LLM 中的 “temperature”参数,可以使回答更加严格和有条理,也可以使回答更加随机和多变。用户无法在上述 UCaaS 解决方案的 LLM 接口中调整temperature参数。
LLM 幻觉
由于 LLM 只是用数字表示的概率模型,因此 LLM 和 Gen AI 无法像人类那样理解单词和短语。因此,当某些单词和短语一起出现,或以有规律的重复序列出现时,LLM 可能会表现出一种叫做幻觉的现象。幻觉是指大语言模型生成的回复与事实不符或与用户的提示无关。
大型语言模型可能会产生幻觉,也可能会犯错误。因此,审查 LLM 的输出非常重要,因为您和您的组织最终要对其内容负责。
作者:Brent Kelly 和 Kevin Kieller
译自:https://www.nojitter.com/ai-automation/learning-live-your-ucaas-llm-part-1
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/zixun/48308.html