
Mistral AI 发布了 Mistral Small 4,这是 Mistral Small 系列的新模型,旨在将之前多个独立的功能整合到一个单一的部署目标中。Mistral 团队将 Small 4 描述为首个融合了Mistral Small(指令执行)、Magistral(推理)、Pixtral(多模态理解)和Devstral(智能体编码)等功能的组合模型。最终成果是一个可以作为通用助手、推理模型和多模态系统运行的单一模型,无需在不同工作流程中切换模型。
架构:128 位专家,稀疏激活
从架构上看,Mistral Small 4 是一个混合专家 (MoE)模型,包含128 位专家,每个 token有4 位活跃专家。该模型总共有 1190 亿个参数,每个 token 有 60 亿个活跃参数,若包含嵌入层和输出层则为 80 亿。
长上下文和多模态支持
该模型支持256k 的上下文窗口,这对于实际工程应用场景而言意义重大。长上下文容量的重要性不在于其市场宣传指标,而在于其对运维的简化作用:它减少了在长文档分析、代码库探索、多文件推理和智能体工作流等任务中对数据分块、检索编排和上下文剪枝的需求。Mistral 将该模型定位为适用于通用聊天、编码、智能体任务和复杂推理,支持文本和图像输入以及文本输出。这使得 Small 4 跻身于日益重要的通用模型行列,这类模型有望通过单一 API 接口处理语言密集型和视觉化的企业级任务。
推理时可配置的推理强度
比原始参数数量更重要的产品决策是引入了可配置的推理强度。Small 4 引入了按请求设置的 reasoning_effort 参数,允许开发者通过牺牲延迟来换取更深入的测试时推理。在官方文档中,reasoning_effort=“none” 被描述为能产生快速响应,其聊天风格相当于 Mistral Small 3.2;而 reasoning_effort="high" 则旨在实现更周密、循序渐进的推理,其详细程度可与早期的 Magistral 模型相媲美。这改变了部署模式。开发团队无需在快速模型与推理模型之间进行路由切换,而是可以保持单一模型在线,并在请求时动态调整推理行为。从系统架构角度来看,这种方式更为简洁,且在仅需对部分查询进行高成本推理的产品中更易于管理。
性能声明和吞吐量定位
Mistral 团队也强调推理效率。在延迟优化配置下, Small 4 的端到端完成时间缩短了 40% ;在吞吐量优化配置下,每秒请求数提高了 3 倍,这两项指标均与 Mistral Small 3 相比。Mistral 并非仅仅将 Small 4 视为一个更大的推理模型,而是将其定位为一个旨在提升实际服务负载下部署经济性的系统。
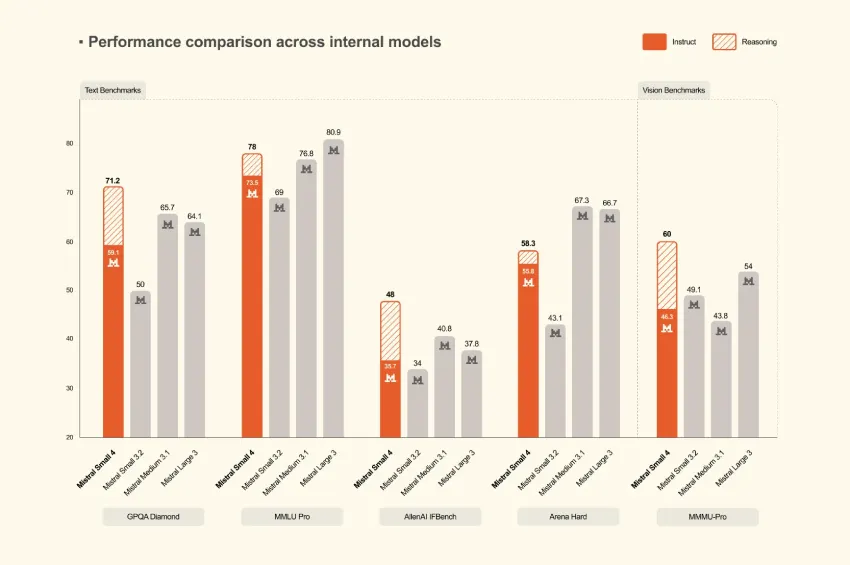
基准结果和产出效率
在推理基准测试方面,Mistral 的发布重点在于质量和输出效率。Mistral 研究团队报告称,Mistral Small 4在AA LCR、LiveCodeBench和AIME 2025测试中,其推理性能与GPT-OSS 120B持平或更优,同时输出更短。Mistral 公布的数据显示,Small 4 在AA LCR 测试中,使用 1.6K 个字符即可获得 0.72 的分数,而 Qwen 模型需要5.8K 到 6.1K 个字符才能达到类似的性能。Mistral 团队指出,在LiveCodeBench 测试中,Small 4 的性能优于 GPT-OSS 120B,同时输出量减少了 20%。这些是公司公布的结果,但它们强调了一个比单纯的基准测试分数更实用的指标:每个生成词元的性能。对于生产环境工作负载而言,更短的输出可以直接降低延迟、推理成本和下游解析开销。

部署详情
对于自托管,Mistral 提供了具体的架构指导。该公司建议的最低部署目标是4 块 NVIDIA HGX H100、2块NVIDIA HGX H200或1 块 NVIDIA DGX B200,并建议使用更大的配置以获得最佳性能。HuggingFace 上的显卡型号支持vLLM、llama.cpp、SGLang和Transformers,但部分功能仍在开发中,vLLM是推荐选项。Mistral 团队还提供了一个自定义 Docker 镜像,并指出与工具调用和推理解析相关的修复仍在向上游提交。这对工程团队来说是一个有用的细节,因为它明确表明虽然支持已经存在,但某些组件仍在更广泛的开源服务堆栈中稳定运行。
要点总结
- 一个统一的模型: Mistral Small 4 将指令、推理、多模态和智能编码功能结合在一个模型中。
- 稀疏 MoE 设计:它使用128 位专家,每个 token有4 位活跃专家,目标是比规模相近的密集模型具有更高的效率。
- 支持长上下文:该模型支持256k 上下文窗口,并接受文本和图像输入,输出文本。
- 推理是可配置的:开发人员可以在推理时调整
reasoning_effort,而无需在独立的快速模型和推理模型之间进行切换。 - 开放部署重点:它以Apache 2.0协议发布,支持通过vLLM等堆栈提供服务,并在 Hugging Face 上提供多个检查点变体。
参考资料:https://mistral.ai/news/mistral-small-4
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/zixun/65473.html