
Google DeepMind 刚刚发布了Gemma 4 12B,这是一个完全摒弃传统编码器的密集型多模态模型。视觉和音频数据直接输入到 LLM 主干网。最终生成的模型可以在配备 16 GB 内存的消费级笔记本电脑上运行智能体工作流程。该模型采用 Apache 2.0 许可证发布。
模型概览及访问
Gemma 4 12B 是一个拥有 120 亿参数的纯解码器 Transformer 模型。它原生支持文本、图像、音频和视频处理,没有单独的视觉或音频编码器。该解码器采用与 Gemma 4 31B Dense 模型相同的结构,弥合了边缘计算友好的 E4B 模型和规模更大的 26B Mixture of Experts 变体之间的差距。
- 架构:统一的、无编码器的纯解码器转换器。
- 支持文本、图像、视频和原生音频输入——首款支持音频的中型 Gemma。
- 硬件要求: 16 GB 显存或统一内存。可在消费级 GPU 笔记本电脑和 Apple Silicon Mac 上运行。
- 许可证: Apache 2.0。权重数据是开放的,可以公开下载。
- 推理栈:兼容 llama.cpp、MLX、vLLM、Ollama、SGLang、Unsloth 和 LM Studio。
- 下载: Hugging Face和Kaggle。指导变体是
google/gemma-4-12B-it。 - 集成: Hugging Face Transformers、LiteRT-LM CLI 和 OpenAI 兼容的本地 API 服务器。
同时还发布了一个专用的多标记预测(MTP)草稿模型。它可以降低本地硬件上的推理延迟。
架构:无编码器设计
之前所有中型 Gemma 机型都使用独立的 Transformer 编码器分别处理视频和音频。这些编码器增加了延迟和参数开销。中型 Gemma 4 机型配备了 5.5 亿参数的视频编码器。E2B 和 E4B 机型则配备了 3 亿参数的音频编码器。所有这些在 12B 机型中都被取消了。
视觉嵌入器(3500万参数):原始图像被分割成48×48像素的图像块。每个图像块通过一次矩阵乘法投影到LLM的隐藏维度。该模型没有注意力层,每个图像块独立处理。空间位置信息通过分解坐标查找表注入:一个学习到的X矩阵和一个学习到的Y矩阵。对于坐标为(x, y)的图像块,模型查找两个学习到的嵌入向量并将它们相加形成一个位置向量。该位置向量与图像块的嵌入向量相加,然后进行归一化。这就是整个视觉流程。
音频波形投影:原始 16 kHz 音频被分割成 40 毫秒的帧。每帧包含 640 个值。这些值被线性投影到与文本标记相同的嵌入空间中。没有特征提取,也没有贴图层。LLM 现有的旋转位置嵌入 (RoPE) 处理一维时间序列。E2B 和 E4B 中的音频编码器使用了 12 个贴图层。所有这些都被移除。
重要性:统一的权重空间意味着您不再需要对独立的冻结编码器进行协同调优。下游的 LoRA 微调或完整调优只需一次即可更新视觉、音频和文本处理。Hugging Face Transformers 和 Unsloth 已经支持此功能。
这种无编码器设计降低了多模态延迟。LLM主干网立即开始处理,无需先完成编码器的处理。
功能与性能
Google DeepMind 团队在最初的发布材料中并未公布完整的基准测试结果。官方发布说明指出,12B 模型在标准基准测试中性能接近 26B MoE 模型,而内存占用量却不到后者的一半。
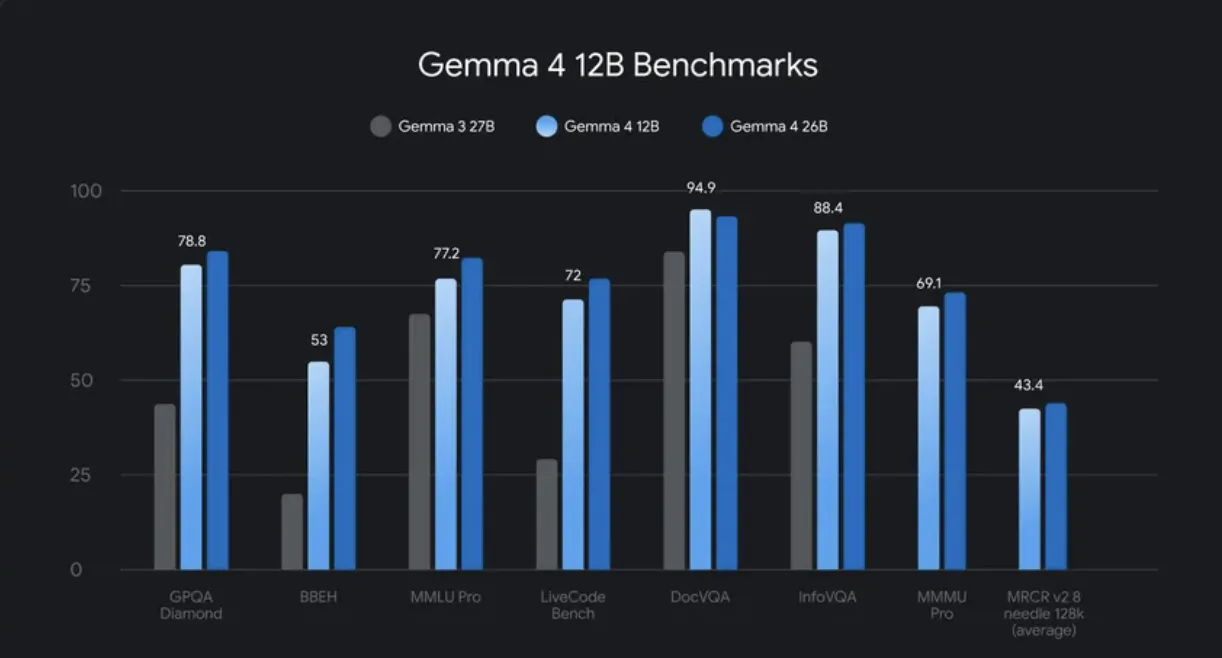

该模型展现出的功能包括:
- 自动语音识别。无需外部ASR流程即可直接转录音频。
- 智能推理。可在本地运行多步骤工作流程,性能接近 26B MoE 模型。
- 声音分割。区分音频输入中的说话人。
- 视频理解。能够同时处理视频帧和音频。演示程序使用 1 帧/秒的帧率和每帧 70 个视觉标记的预算,分析了一段 5 分钟的 Google I/O 主题演讲片段,共 313 帧。
- 编码。使用自己的代码生成器构建了一个 Gradio 图像处理应用程序,并使用 llama.cpp 在本地运行。
- 多模态代理工作流程。官方的 Gemma Skills 代码库(github.com/google-gemma/gemma-skills)提供了预构建的代理功能。
在谷歌自己的 Google AI Edge Eloquent 应用中,切换到 Gemma 4 12B 后,谷歌报告称整体质量提高了 60% 以上,指令遵循性和范围遵守性也得到了改善。
要点总结
- Google DeepMind 发布了 Gemma 4 12B,这是一个采用 Apache 2.0 许可的无编码器密集型多模态模型。
- 视觉和音频直接输入到 LLM 主干网,无需单独的视觉 (550M) 或音频 (300M) 编码器。
- 35M 视觉嵌入器使用单个矩阵乘法器加上因子分解的 X/Y 位置查找;音频直接投影原始 16 kHz 帧。
- 它是第一款支持原生音频的中型 Gemma,并且增加了视频功能,可在 16 GB 笔记本电脑上运行。
- 基准测试性能接近 26B MoE 模型,而内存占用量不到其一半。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/zixun/67212.html