
语音增强 (SE) 领域的最新进展已经超越了传统的掩码或信号预测方法,转而采用预训练音频模型来获取更丰富、更可迁移的特征。这些模型(例如 WavLM)可以提取有意义的音频嵌入,从而提升 SE 的性能。一些方法使用这些嵌入来预测掩码,或将其与频谱数据相结合以提高准确性。另一些方法则探索生成技术,使用神经声码器直接从噪声嵌入中重建清晰的语音。虽然这些方法有效,但它们通常需要冻结预训练模型或进行大量的微调,这限制了其适应性并增加了计算成本,使得迁移到其他任务更加困难。
小米公司 MiLM Plus 的研究人员提出了一种轻量级且灵活的 SE 方法,该方法使用预训练模型。首先,使用冻结的音频编码器从带噪语音中提取音频嵌入。然后,使用小型降噪编码器对嵌入进行清理,并将其传递给声码器以生成干净的语音。与特定任务模型不同,音频编码器和声码器均经过单独预训练,使该系统能够适应去混响或分离等任务。实验表明,生成模型在语音质量和说话人保真度方面优于判别模型。尽管该系统简单易用,但效率极高,甚至在听力测试中超越了领先的 SE 模型。
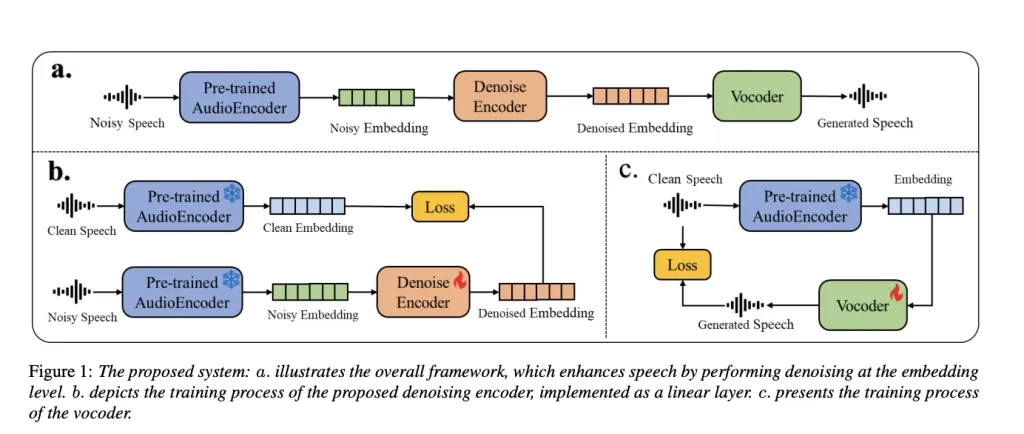
所提出的语音增强系统分为三个主要部分。首先,将带噪语音输入预训练的音频编码器,生成带噪音频嵌入。然后,降噪编码器对这些嵌入进行细化,生成更清晰的版本,最终由声码器转换回语音。虽然降噪编码器和声码器是分别训练的,但它们都依赖于同一个冻结的、预训练的音频编码器。在训练过程中,降噪编码器使用均方误差损失函数,最小化带噪嵌入和清晰嵌入之间的差异,这两个嵌入都是由成对的语音样本并行生成的。该编码器采用 ViT 架构构建,并带有标准激活层和归一化层。
对于声码器,训练采用自监督的方式,仅使用干净的语音数据。声码器通过预测傅里叶谱系数来学习从音频嵌入中重建语音波形,并通过逆短时傅里叶变换将傅里叶谱系数转换回音频。它采用了略微修改的 Vocos 框架,以适应各种音频编码器。采用生成对抗网络 (GAN) 设置,其中生成器基于 ConvNeXt,鉴别器包括多周期和多分辨率类型。训练还结合了对抗、重建和特征匹配损失。重要的是,在整个过程中,音频编码器保持不变,使用来自公开模型的权重。
评估结果表明,Dasheng 等生成式音频编码器的性能始终优于判别式编码器。在 DNS1 数据集上,Dasheng 的说话者相似度得分达到 0.881,而 WavLM 和 Whisper 的得分分别为 0.486 和 0.489。在语音质量方面,DNSMOS 和 NISQAv2 等非侵入式指标表明,即使使用较小的去噪编码器,语音质量也有明显改善。例如,ViT3 的 DNSMOS 为 4.03,NISQAv2 为 4.41。有 17 人参加的主观听力测试表明,Dasheng 的平均意见分(MOS)为 3.87,超过了 Demucs 的 3.11 和 LMS 的 2.98,突显了其强大的感知性能。

总而言之,本研究提出了一个实用且适应性强的语音增强系统,该系统依赖于预先训练的生成式音频编码器和声码器,无需进行全面的模型微调。通过使用轻量级编码器对音频嵌入进行去噪,并使用预先训练的声码器重建语音,该系统实现了计算效率和强大的性能。评估表明,生成式音频编码器在语音质量和说话人保真度方面显著优于判别式音频编码器。紧凑型去噪编码器即使使用较少的参数也能保持较高的感知质量。主观听力测试进一步证实,该方法比现有的最先进模型提供了更佳的感知清晰度,凸显了其有效性和多功能性。
参考资料:
- 论文地址:https://arxiv.org/abs/2506.11514v1
- GitHub:https://github.com/xiaomi-research/dasheng-denoiser
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/59815.html