
我们已经知道应该如何从不同类型的机器学习方法中学习,如监督学习、对比学习等。因此在本讲座中将尝试回答一个问题,即我们应该如何将模型转换为更通用、更灵活、更实时的模型,换句话说,我们应该如何在基础模型之上构建一个通用的解决方案系统。
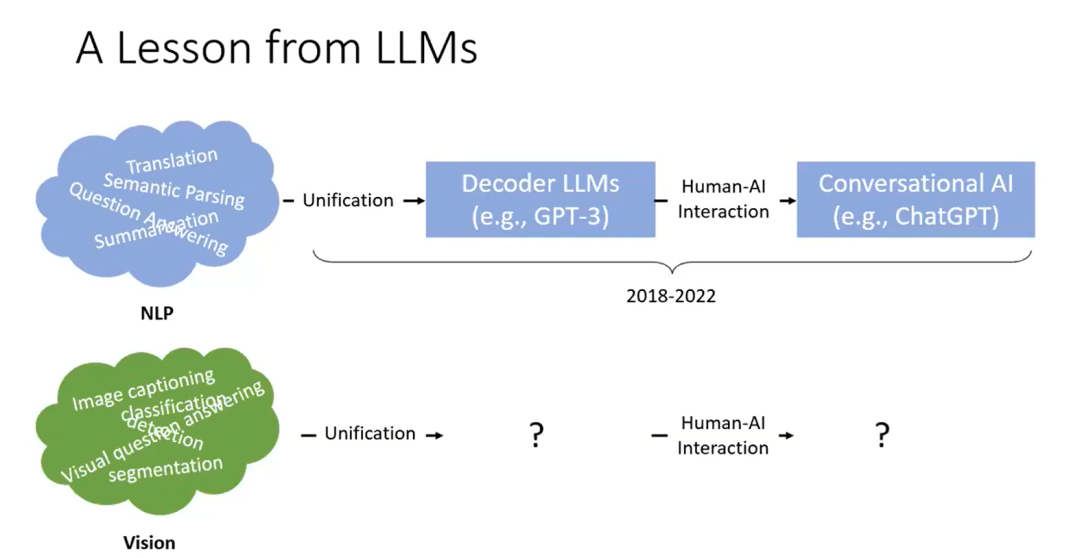
因此,我们自然要了解语言模型在过去几年中是如何发展的。在最开始的时候,不同的任务实际上是由不同的模型完成的,也许是 LSTM,也许是 CNN。更进一步地,支持用户交互的 GPT 模型出现了,这不仅从根本上改变了研究领域,也改变了社会。
如果我们对计算机视觉模型进行类似的预测,现在我们正在应对不同类型的图像级任务,如图像分类、图像描述,以及像素级任务图像分割等。实际上我们感兴趣的是,如何遵循类似语言模型的发展路径,进行统一,并增进计算机视觉模型的人类-AI 交互。

统一框架的难点与挑战
然而,我们难以轻易地将 NLP 的方法复制到计算机视觉领域,因为计算机视觉任务实际上是非常多样化和碎片化的,这给构建统一的模型框架带来了一些挑战。
视觉模型
-
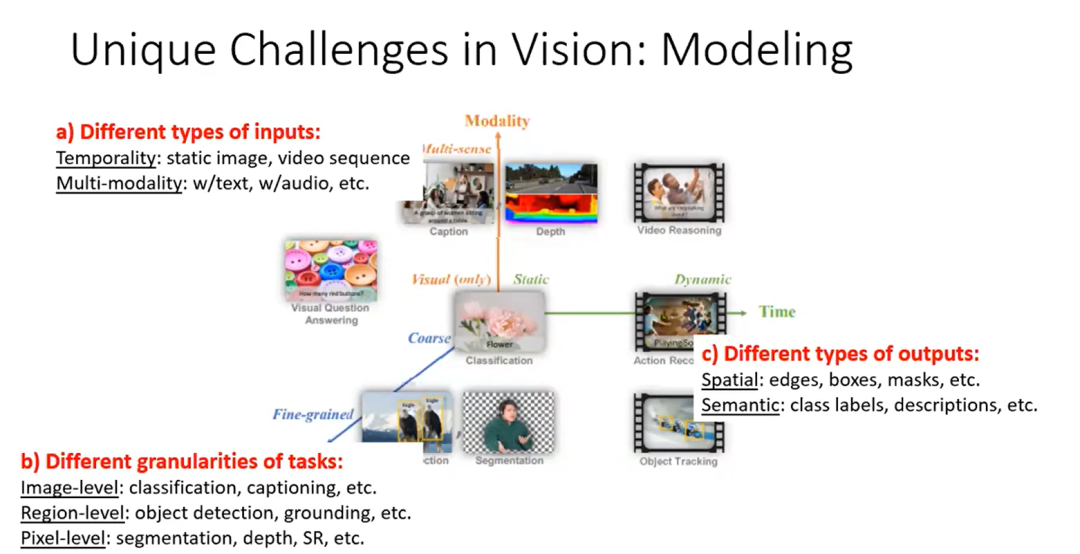
视觉任务实际上需要处理不同类型的输入。输入可以是静态图像,也可以是视频序列;可以是单一的 RGB 图像,或者是多模态的组合。 -
任务的粒度不同。计算机视觉中有图像级的任务,如图像分类、图像描述,还有区域级和像素级的任务。 -
视觉任务的输出也具有不同的格式。输出可能是空间信息,如边缘、框、mask等,也可能是语义信息,如分类标签、描述等。
数据
除了模型上的挑战,还有数据上的挑战。
-
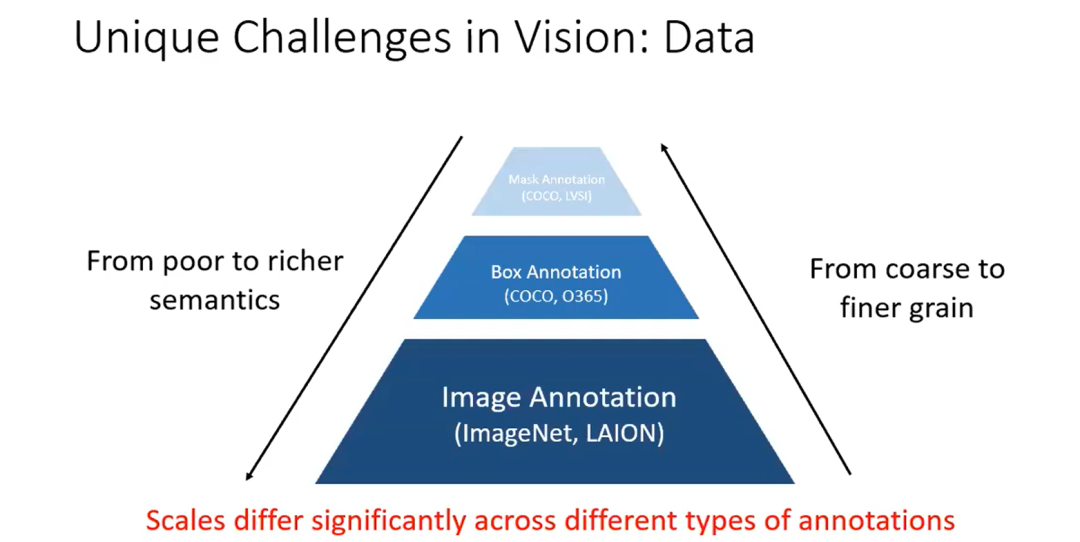
由于不同任务所需的数据不同,如图的金字塔从下到上有图像注释、框注释和掩码注释,语义信息从丰富到贫乏,而任务粒度从粗到细。 -
与语言数据相比,图像数据的收集困难得多。因此视觉数据的规模要比语言数据小得多。
为实现统一的尝试
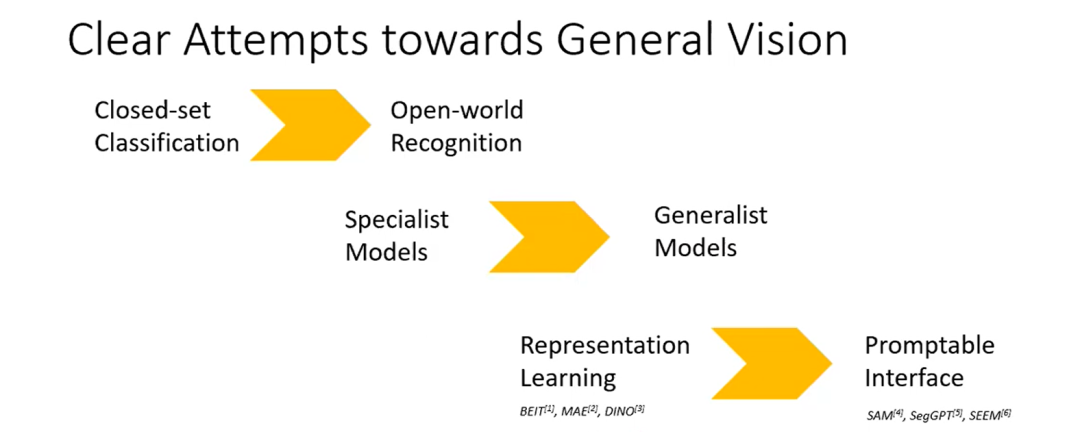
首先,一些研究人员正在努力将封闭式分类转变为开放式识别。像 CILP 这样的语言图像模型,为图像分类提供了可移植性。
其次,我们正在尝试将专用模型转换为综合模型。现在,越来越多的通用模型出现,它们都试图归纳并建立一些计算机视觉模型来统一过去的模型。
第三,学习视觉表示会带来更好的效果。我们更多地讨论是否可以共享某种基础模型,以实现在不进行任何微调的情况下支持端到端任务,这基本上是计算机社区的大趋势。
连接视觉与语言我们需要把视觉和语言联系起来。语言是许多人共享信息的共同媒介。这样做的好处是,我们可以从一个任务到另一个任务进行零样本转换。统一不同粒度的任务计算机视觉正在处理不同粒度的任务。因此我们期待能否建立一种统一的模型来统一不同的粒度,以实现跨任务的协同。多种形式输入对于人机交互方面,应该使系统能够支持并接受各种形式的输入。在视觉中,不仅仅文本作为提示,我们也可以画一个框、一个笔画,甚至一个手势。这样做的好处是可以减少表达的模糊性。
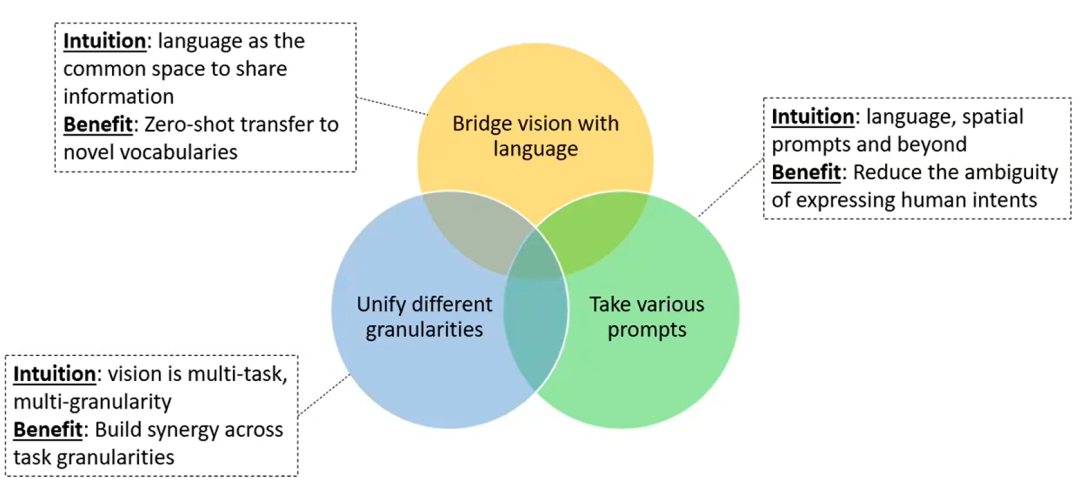
连接视觉与语言
因此,让我们首先深入研究一下我们应该如何将愿景和语言联系起来。在过去的几年里,许多作品试图将视觉和语言联系起来。
经典的图像分类模型为了对视觉内容进行分类,只对标签进行编码,因此不包含显式语义。但是在一些新的模型中,将标签嵌入替换为具有某种语义含义的一些概念名称,并使用文本编码器将单词编码为token。通过这种方式,可以将一个语义描述的视觉内容投影到一个共同共享的语义空间。
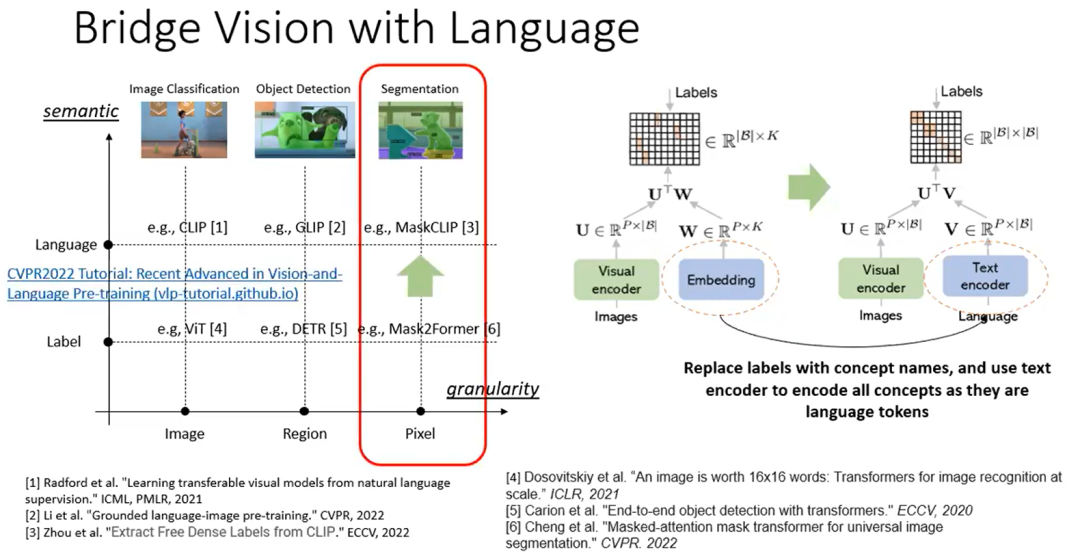
图像分割
图像分割任务需要模型对具有相似语义的像素进行分组。
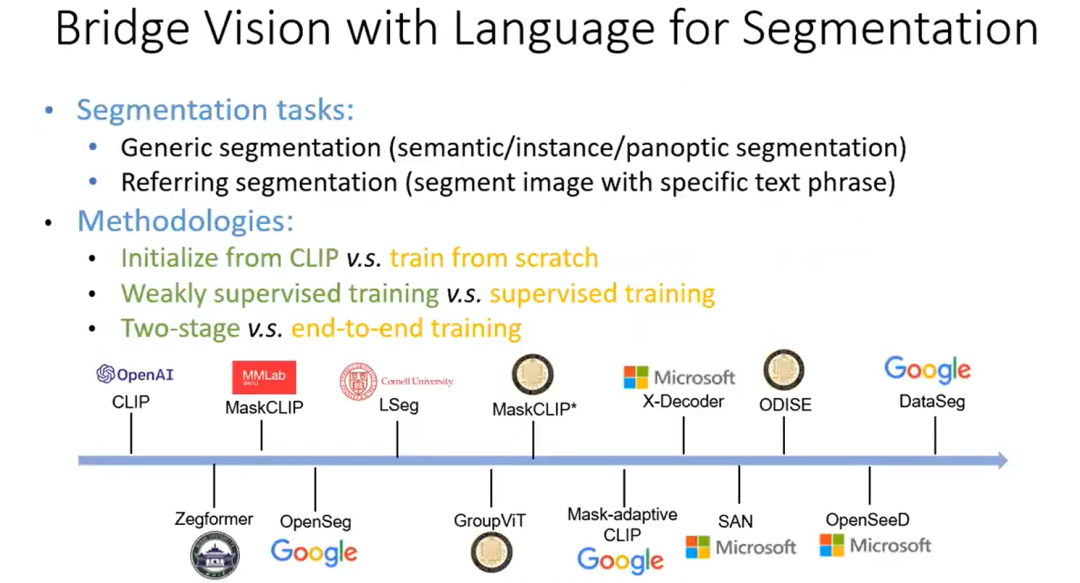
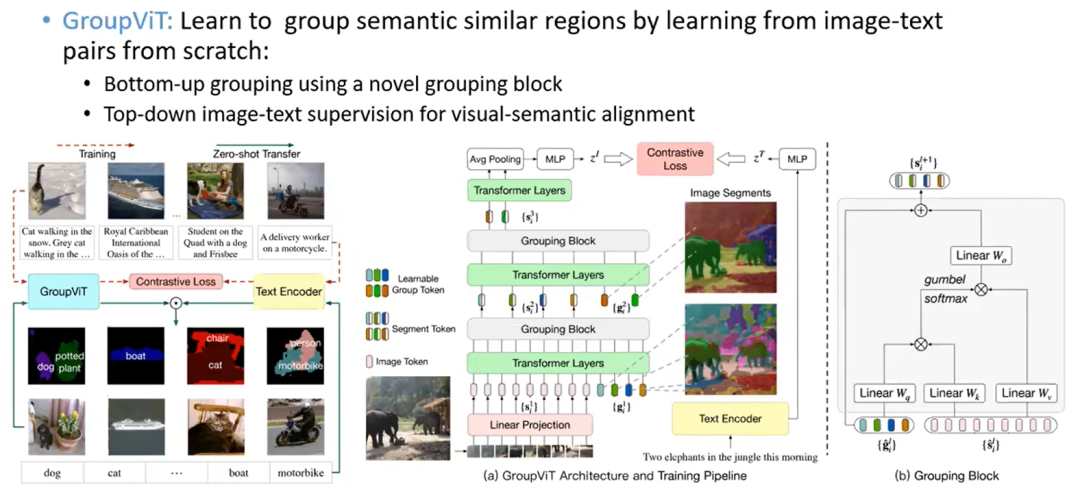
GroupViT
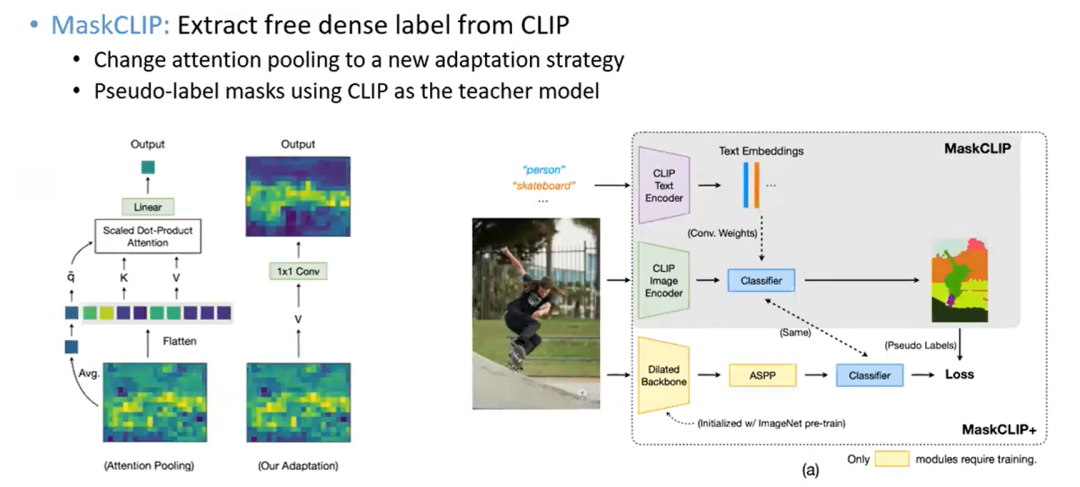
MaskCLIP
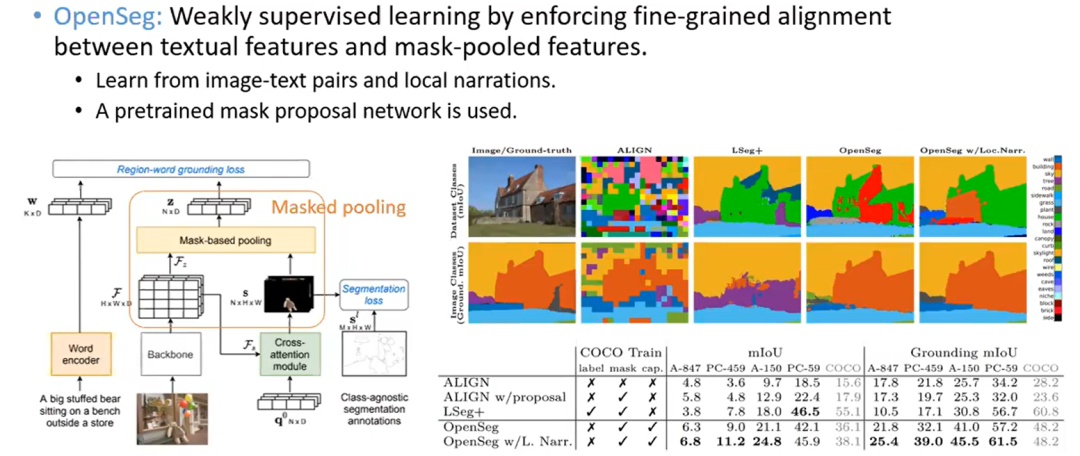
OpenSeg
统一不同粒度的任务
对于所有这类核心视觉任务,如图像级任务、区域级任务和像素级任务,模型已经取得了很大的成功,并且已经在经典计算分类识别模型与语言交互之间建立了联系。
虽然这与识别开放世界的概念一致,但仍然主要是面向处理特定任务的。我们无法通过仅仅一个模型来跨不同的粒度同时执行这些视觉任务。因此,要建立通用的理解模型,我们需要跨越不同的粒度来看待任务,并将它们连接起来。
理想情况下,我们希望构建跨粒度任务的协同。例如,粗粒度数据应该有助于其他具有丰富细节的细粒度数据或任务。另一方面,如果能够使模型从细粒度到粗粒度共享信息,以实现数据基础,也是非常重要的。因此,我们希望构建多粒度协同作用的模型。

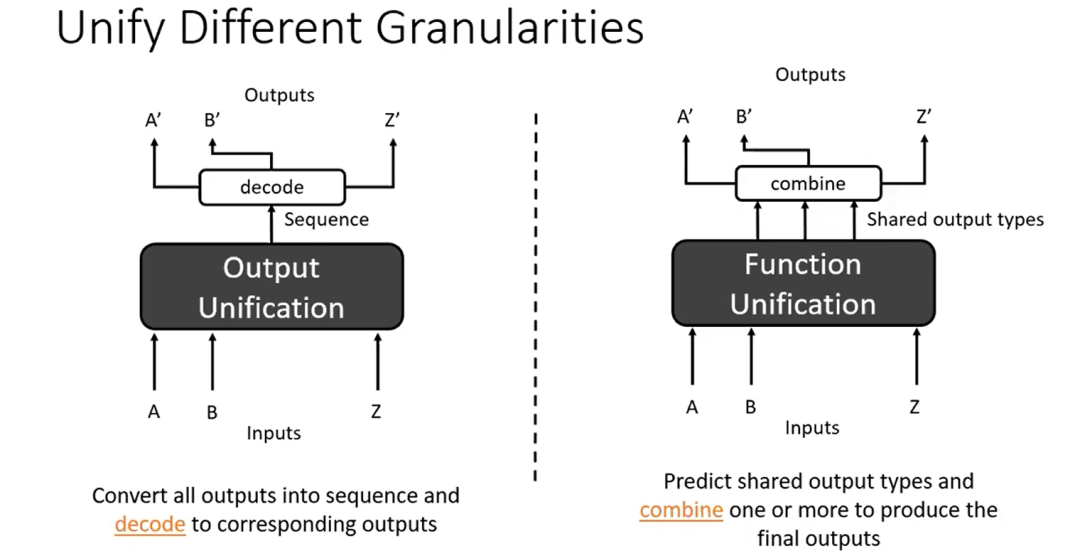
左侧模型输出试图解码所有任务 A 到 Z 的所有解码器序列,并使用某种解码器将此序列解码出来,最终产生每个任务的预测。但是对于功能统一的模型,输入可能没有多大不同,但它将产生不同类型的输出,这些输出在不同的任务中共享,模型将不同的输出组合在一起,产生最终的输出。
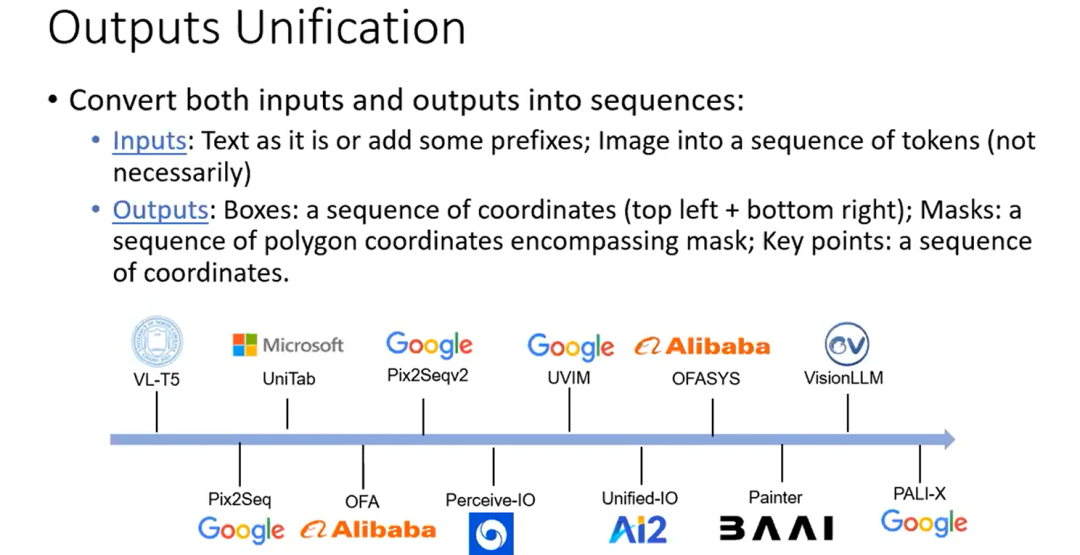
输出统一
这些方法中的大多数实际上将其输出转换为特殊形式的或某种语义序列。对于语义序列来说,语言模型已经可以做到这一点。但对于特殊输出,如 box, mask, key point,一些方法已经探索了一种简单和启发式的方法,以将其转换为序列。
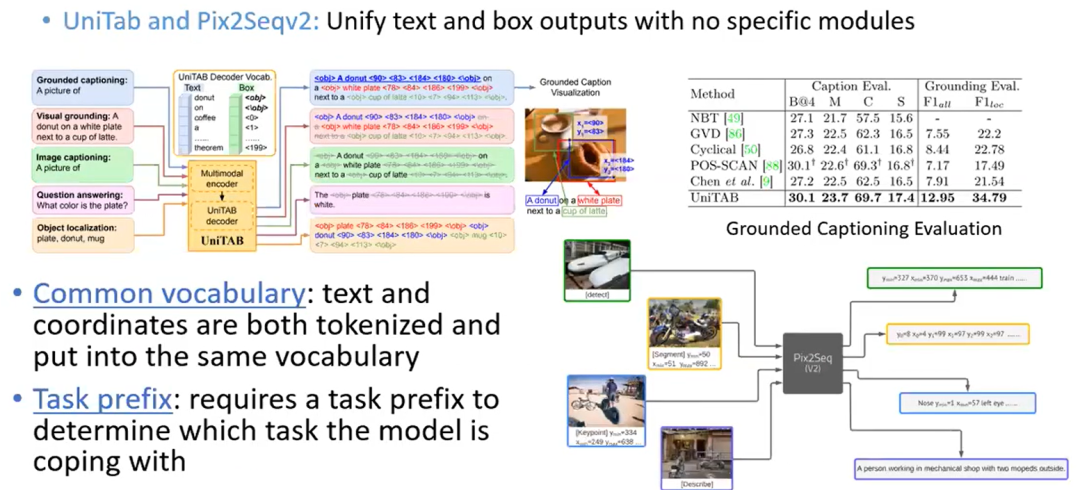
UniTab and Pix2Seqv2
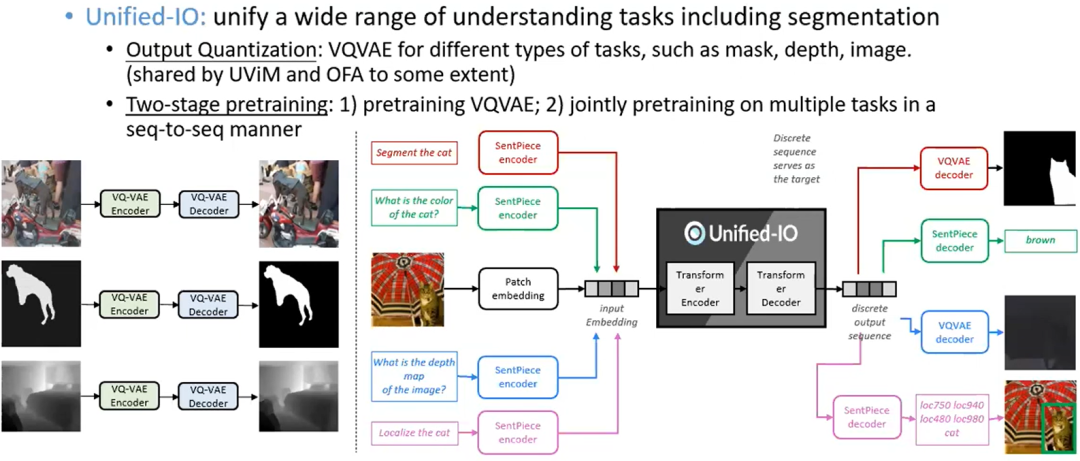
Unified-IO
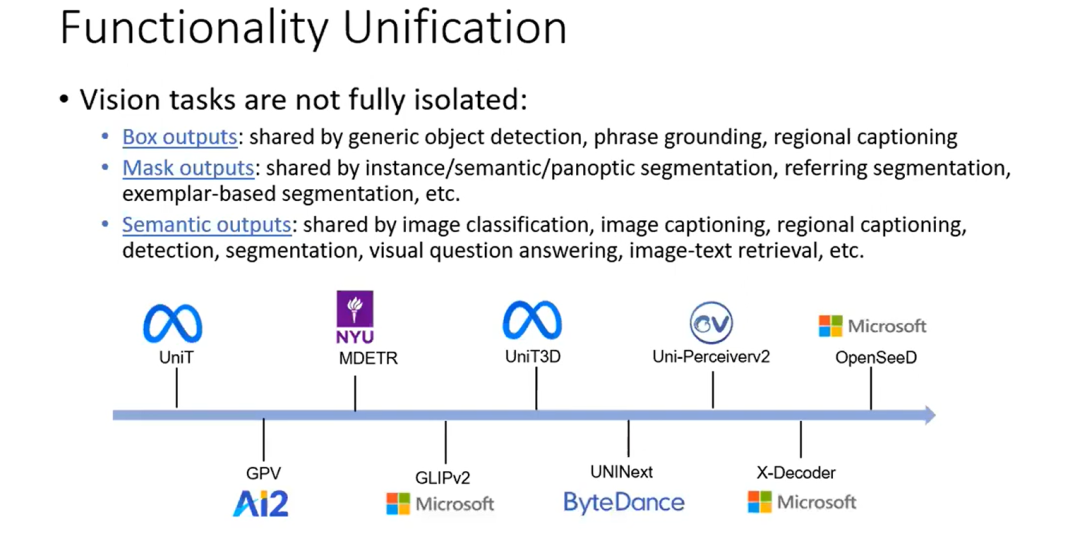
功能统一
视觉任务不是完全孤立的。Box 输出可以用于通用的目标检测、区域标注。Mask 输出也可以用于实例分割、语义分割、全景分割、基于样本的分割等,所有这些类型的分割任务实际上都可以使用掩码解码器来解码。对于语义输出,也可以在不同的任务中共享,如图像分类、图像描述、检测和分割等任务。
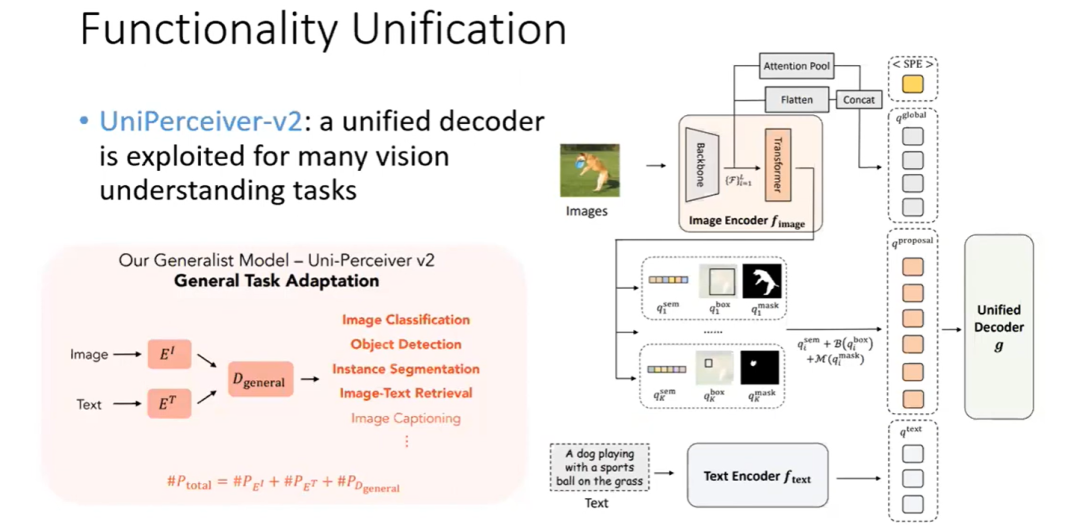
UniPerceiver-v2
X-Decoder
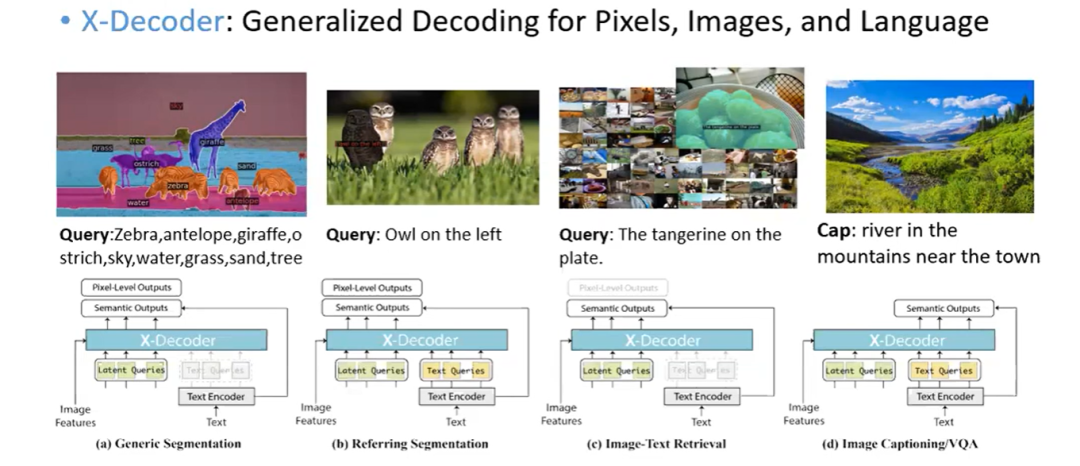
多种形式输入
如果我们只有 GPT,也许它不能直接用来完成我们的日常任务,例如编码、编写电子邮件等。但如果我们可以在人工反馈后进行某种指令,就可以建立某种类似 ChatGPT 的对话式人工智能。鉴于我们已经有了一个通用的视觉模型,那么我们可以做些什么来实现人与 AI 模型之间的交互呢?
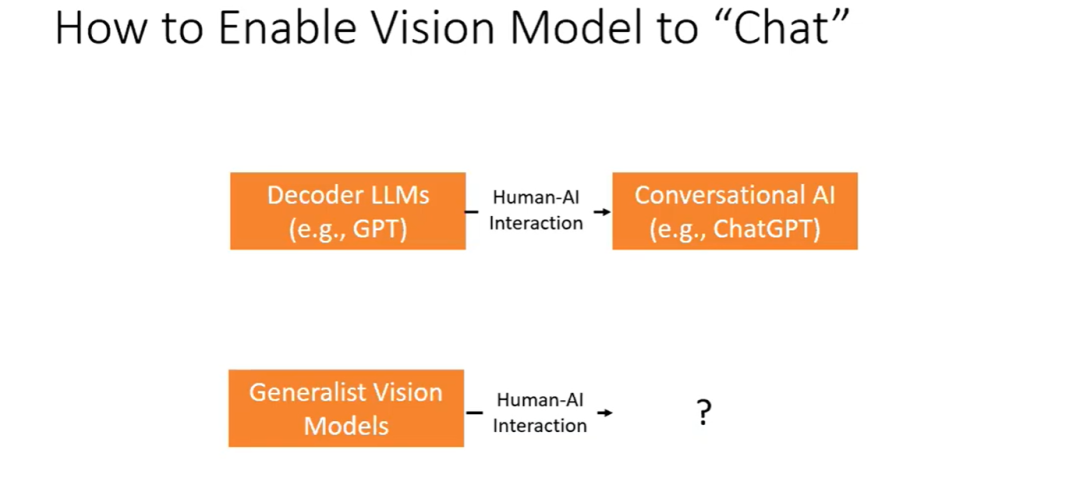
在这部分,有两种主要的研究方向。第一种是如何在上下文语言中开发一个可输入提示的接口。第二种是如何实现计算模型与人的交互,使其能够帮助人完成任务并返回预测结果。

上下文学习
Visual prompting via Image Inpainting

SegGPT
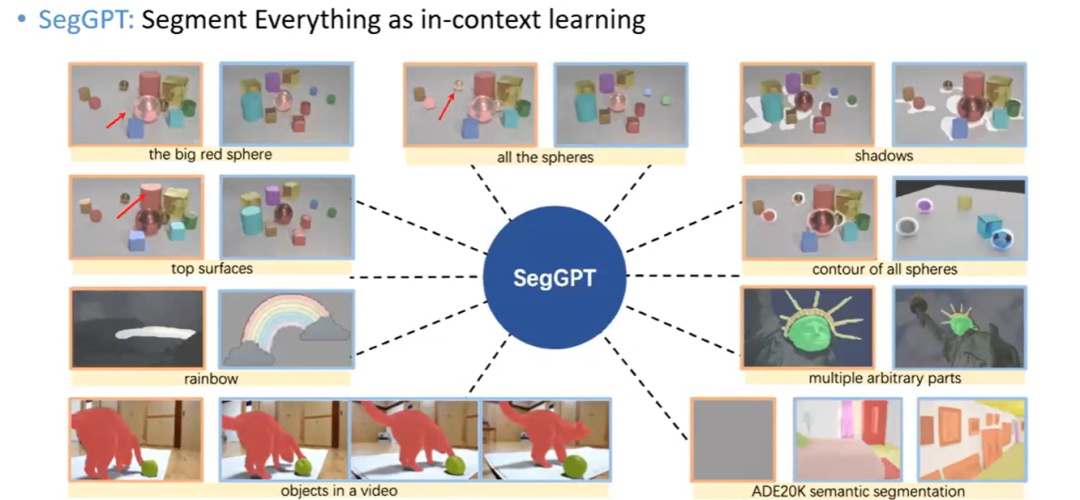
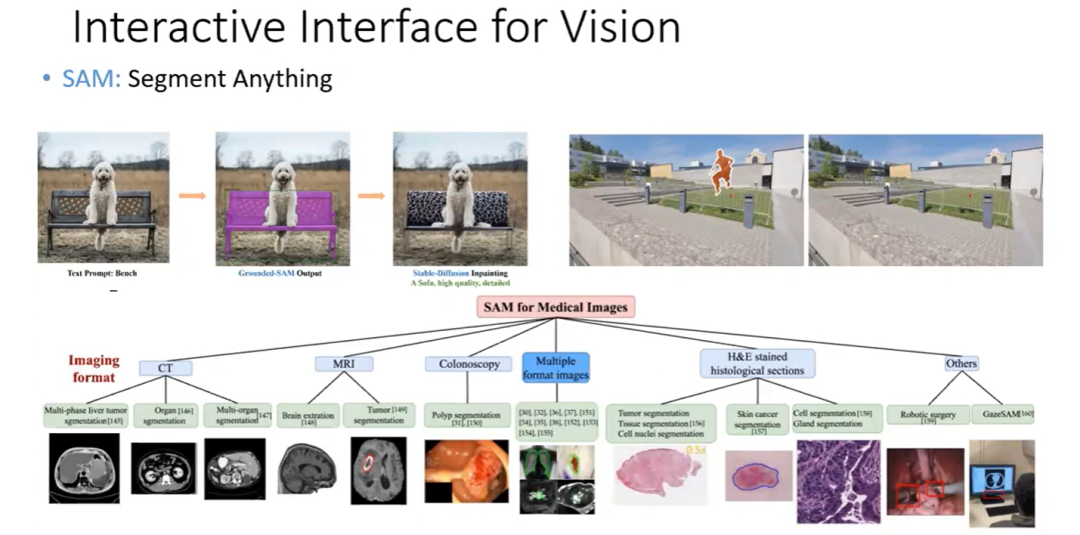
交互式界面
SAM
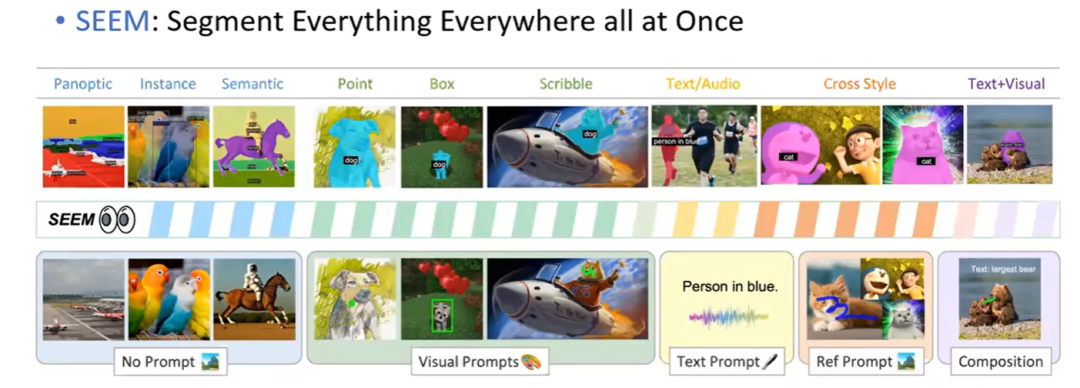
SEEM
题目:From Specialist to Generalist:Towards General Vision Understanding Interface
来源:CVPR 2023 Tutorial Talk
主讲人:Jianwei Yang
内容整理:汪奕文
视频地址:https://www.youtube.com/watch?v=wIcTyutOlDs&list=PLB1k029in3UhWaAsXP1DGq8qEpWxW0QyS&index=4
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。