
导读:Interspeech 是国际语音通信协会(ISCA)举办的年度会议,也是全球最大、最全面的专注于语音通信领域的学术盛会。2023 届 Interspeech 会议于 2023 年 8 月 20 日至 8 月 24 日于爱尔兰都柏林举办。网易易盾有 2 篇关于语音识别方向的学术论文成功被会议录用,网易智企技术+将就这两篇论文推出相关解读文章,本文为第二篇。
文 |网易易盾 AI 实验室
来源:网易智企技术
原文:https://mp.weixin.qq.com/s/eo6SMQoCiQDPD4yXKrmrRw
01 背景介绍
在易盾智能语音检测业务场景中,存在实时(流式)检测需求和离线(非流式)检测需求。流式\非流式一体化语音识别[1-3]是指一个模型可以同时满足流式场景和非流式场景的识别需求,它降低了模型开发,训练和部署的成本。一体化模型可以在流式模式下进行实时预测,实时返回识别结果,也可以在非流式模式下利用完整的音频上下文进行一句话识别,提供更高准确率的识别效果。在实际的使用过程中模型性能仍然是我们关注的重点,大多数场景下一体化模型往往存在两个性能差距,如图 1 所示。
- 一体化模型的非流式识别性能优于流式识别。
- 完全非流式模式训练出来的纯离线模型性能优于一体化模型中的离线解码模式。
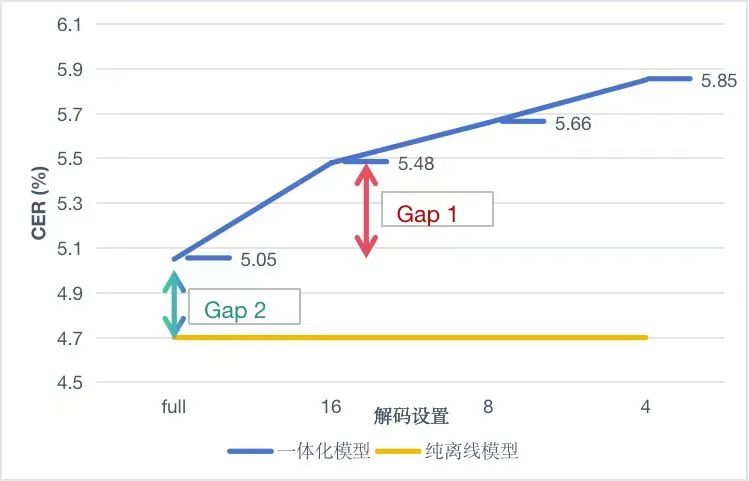

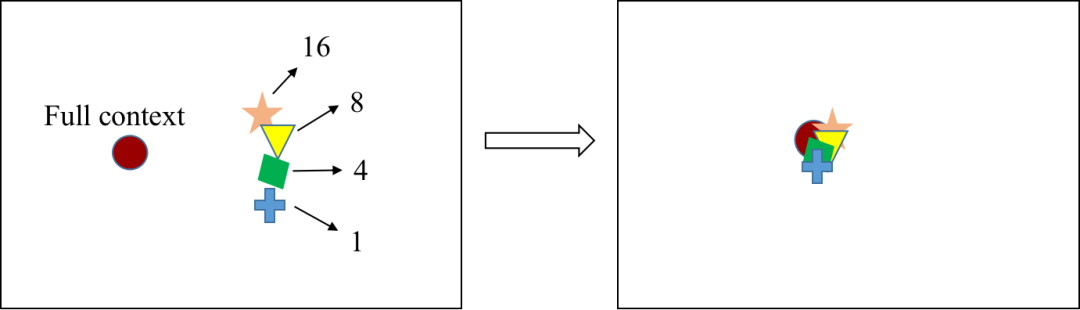
我们希望这两个性能差距越小越好。一方面,我们希望流式识别的效果能向非流式识别靠近,另一方面,我们希望一体化模型的非流式识别和纯离线模型相比没有性能损失。如何进一步提升一体化模型性能是一个具有挑战的问题。我们观察到一体化模型的流式和非流式表征之间存在着 gap,如图 2 左侧所示。从模型表征的角度出发,如果流式表征能够向非流式靠拢,那么流式识别内容也会与非流式识别更相似,也就意味着流式识别的效果能向非流式识别靠近,如图 2 右侧所示。基于这个动机,我们提出利用对比学习方法来缩小流式和非流式模式之间的内在表征差距,从而提升一体化模型的性能。
02 方法介绍
我们使用了 hybrid CTC/Attention[4]架构,系统框架如图 3 所示。具体地,我们的方法基于joint training[3]的训练策略,即给定输入 X,分别计算流式分支的 loss,非流式分支的 loss,和对比学习 loss。
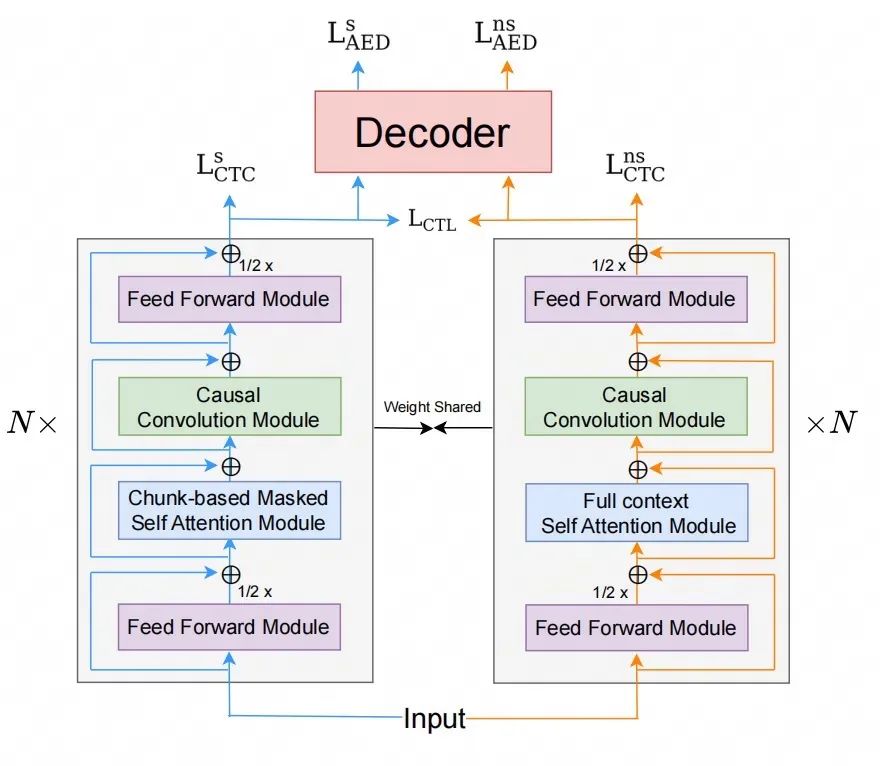
最终,模型的总 loss 是这三个 loss 之和。
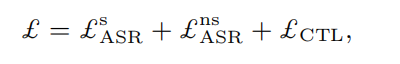
其中,流式分支和非流式分支的 ASR loss 分别是 CTC loss 和 CE loss 的加权和。
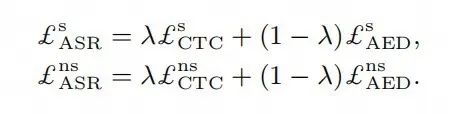
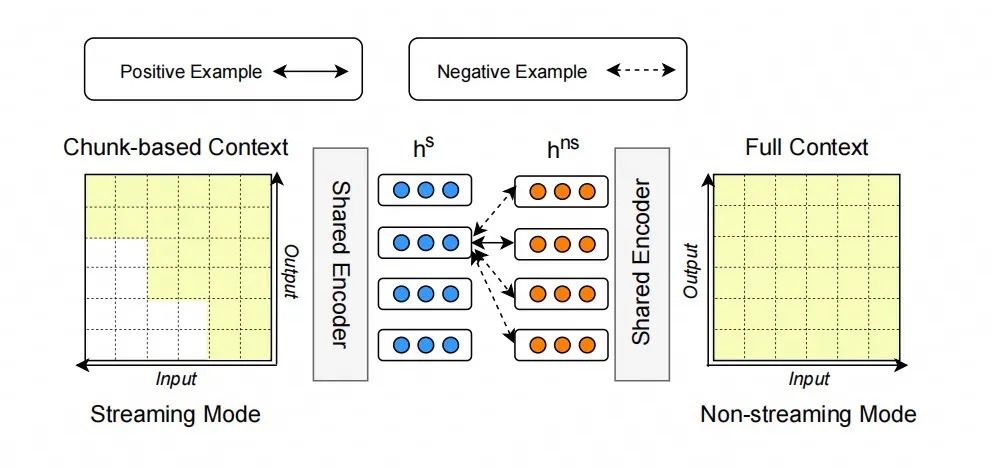
对比 loss 的计算如图 4 所示,我们把每一帧的流式表示和非流式表示作为正样本对,同时从非流式模式的其他帧随机采样多个负样本,利用对比学习拉近正样本之间的距离,同时加大负样本之间的差异化。通过让流式和非流式相互对比学习,同时完成两种模式的训练。
帧级别的对比 loss 计算如下:
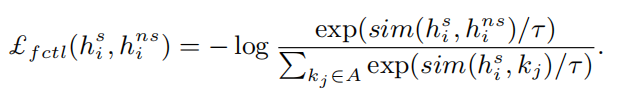
最后总的对比 loss 是所有帧的对比 loss 之和求平均。
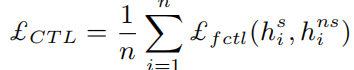
03 实验验证
我们在开源数据集 AISHELL-1[5]验证了我们的算法有效性。实验结果表明,在相同参数规模和训练设置下,相比 baseline 模型我们的一体化模型在流式模式和非流式模式取得了一致性的提升。除此之外,我们的方法不会带来额外的延时。

引入一个 3-gram 的 LM 浅层融合后,我们的一体化模型取得了字错率 4.31% 的非流式识别性能(字错率:Character Error Rate,它是一种衡量语音识别系统性能的指标,计算方式是所识别的文本与真实文本之间不匹配的单词数量的百分比,字错率越低说明识别效果越好),以及 4.66% 的流式识别性能,超过近期发表的文献结果。
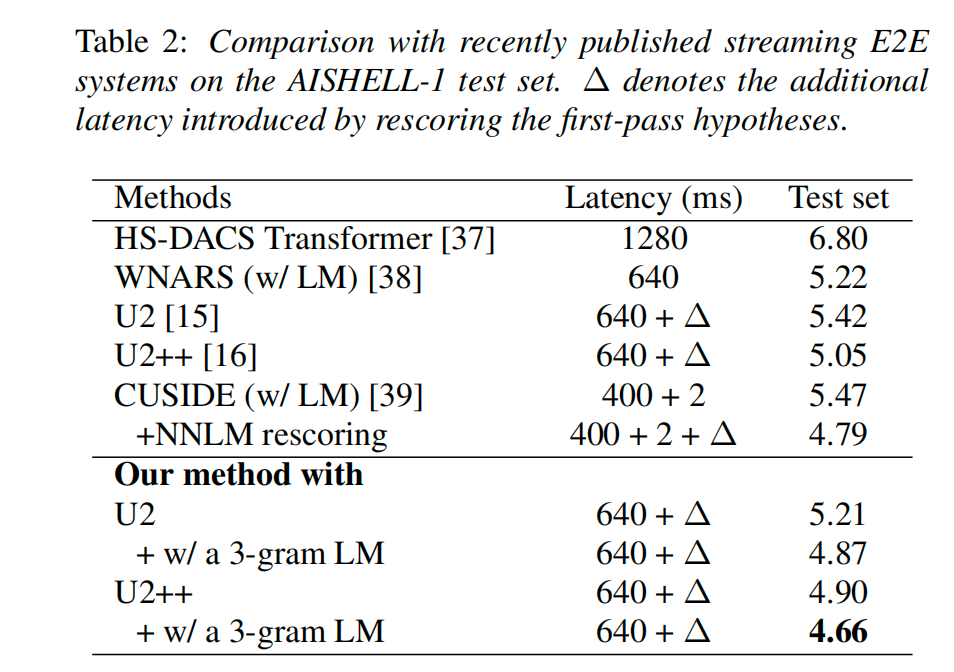
除了开源数据集,我们也在易盾业务场景验证了模型的有效性,结果显示基于对比学习的流式/非流式一体化模型在业务测试集上也取得了显著的提升。
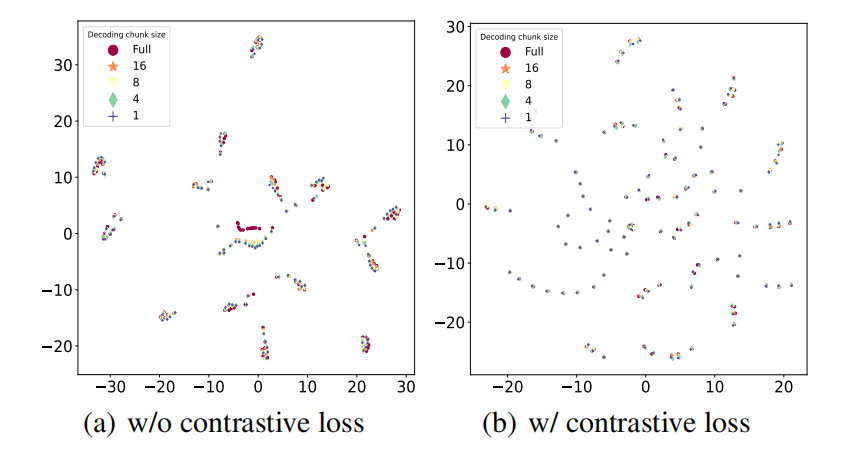
最后,我们可视化了两种模式表征,对比下图左图(没有对比学习)和右图(有对比学习)发现对比学习可以拉近两种表示的距离,使得流式表征和非流式表征的 gap 缩小,从而提升流式识别的性能。除此之外,对比学习可以使得特征在整个空间分布更为均匀,加强了特征的表达能力,从而提升一体化模型的性能。
04 总结
本文提出了一种基于对比学习的流式\非流式一体化语音识别模型训练方法,我们的方法旨在利用对比学习拉近流式表示和非流式表示距离,从而提升一体化模型性能。我们的贡献主要分为两方面:
- 我们引入了一个简单而有效的对比目标拉近一体化模型里流式表征和非流式表征的距离。
- 实验结果表明,我们的方法在广泛使用的 AISHELL-1 基准上达到了 SOTA 性能,进一步提升了一体化模型的识别效果。此外,通过特征可视化分析表明我们的方法可以拉近两种模式下表征的距离,与预期相符合。
参考文献
[1] B. Zhang, D. Wu, Z. Yao et al., “Unified streaming and non-streaming two-pass end-to-end model for speech recognition,” arXiv preprint arXiv:2012.05481, 2020.
[2] D. Wu, B. Zhang, C. Yang et al., “U2++: Unified two-pass bidirectional end-to-end model for speech recognition,” arXiv preprint arXiv:2106.05642, 2021.
[3] J. Yu, W. Han, A. Gulati et al., “Dual-mode asr: Unify and improve streaming asr with full-context modeling,” in ICLR, 2021.
[4] S. Watanabe, T. Hori, S. Kim et al., “Hybrid ctc/attention architecture for end-to-end speech recognition,” IEEE Journal of Selected Topics in Signal Processing, vol. 11, no. 8, pp. 1240–1253, 2017.
[5] H. Bu, J. Du, X. Na et al., “Aishell-1: An open-source mandarin speech corpus and a speech recognition baseline,” in 2017 20th conference of the oriental chapter of the international coordinating committee on speech databases and speech I/O systems and assessment (O-COCOSDA), 2017.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。