
随着大模型技术的飞速发展,基于语言和视觉的3D场景编辑方法取得了十足进步,如Instruct-NeRF2NeRF在修改和场景控制方面展示了强大功能。但在内容生成方面依然面临困难,例如,在3D场景中直接生成一只3D蝴蝶。
为了解决这一难题,谷歌瑞士公司和苏黎世联邦理工学院联合开发了InseRF模型。用户通过InseRF只需输入文本描述和选择特定区域,就能在3D场景中直接生成物品。
例如,在一个3D桌子场景中,在桌面框选一个区域,然后在文本框中输入“生成一个茶杯”,就能快速生成一个3D茶杯模型。
论文地址:https://arxiv.org/abs/2401.05335
InseRF执行流程
InseRF的核心技术创新在于,通过在单个参考视角进行基于遮挡和文本指导的2D对象插入,再将其映射到3D场景,这样可以保证多视角下的一致性并且无需提供具体坐标数据。具体执行流程如下。
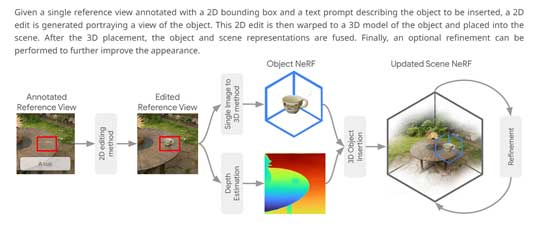

1) 在选择的场景参考视角中,基于文本提示和2D边界框生成目标对象;
2) 从参考视角中的2D图像重建目标对象的3D表征;3) 利用单眼深度估计方法,估计对象在3D场景中的位置;
4) 将对象和场景的3D表征融合为包含对象的新场景;5) 对融合的场景进行优化以进一步改进效果。
2D参考视角编辑
首先选择场景的一个渲染视角作为参考,然后在参考视角中插入目标对象的2D视图。文本提示和2D边界框用于3D空间约束,从而确保插入保持在指定的区域内。
为实现局部化的2D插入,InseRF选择了Imagen作为文本到图像生成模型,并通过再次重建的方法使其适应遮挡区域条件。

再从参考视角中提取生成对象对应的图像区域,并使用单视图重建方法SyncDreamer将其映射到3D对象。该重建方法包含有效的3D物体几何和外观先验,有助于生成高质量的3D对象。
3D放置评估
研究人员通过单目深度估计方法,评估对象在参考视角中的深度,从而确定其在3D场景中对应的位置。
然后进行比例和距离优化,确保插入的3D对象视图与2D参考编辑匹配。最后计算出对象的旋转和平移,完成3D放置。
此外,在得到对象在场景中的位置后,将两者的NeRF表示进行融合,使其可以从不同视点渲染包含对象的新场景,以优化两个坐标系统位置不一致带来的影响。
最后,通过Instruct-NeRF2NeRF的迭代优化方法,来进一步改善3D物品插入的效果,可利用从插入对象中获得的多视角遮挡来限制优化区域。
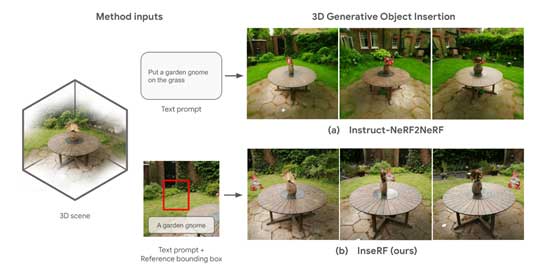
为了测试InseRF的性能,研究人员与当前领先的三维场景编辑产品Instruct-NeRF2NeRF和Multi-View Inpainting进行了评估。InseRF可成功生成各种对象并插入到3D场景中的指定位置,并明显优于这两款产品。
值得一提的是,InseRF只需要一个粗略的视角框,就可实现精确的对象定位,这对于用户来说非常便捷。
本文素材来源InseRF论文,如有侵权请联系删除
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。