
尽管视觉语言建模取得了快速发展,但该领域的大部分进展都源于基于专有数据集训练的模型,这些模型通常依赖于闭源系统的提炼。这种依赖阻碍了科学的透明度和可重复性,尤其是在涉及细粒度图像和视频理解的任务中。基准性能可能更多地反映训练数据和黑盒模型的能力,而非架构或方法上的改进,这使得评估真正的研究进展变得困难。
为了突破这些限制,Meta AI 推出了感知语言模型 (Perception Language Model,PLM),这是一个完全开放且可复现的视觉语言建模框架。PLM 旨在支持图像和视频输入,并且无需使用专有模型输出即可进行训练。相反,它从大规模合成数据和新收集的人工标记数据集中提取数据,从而能够在透明条件下对模型行为和训练动态进行详细评估。
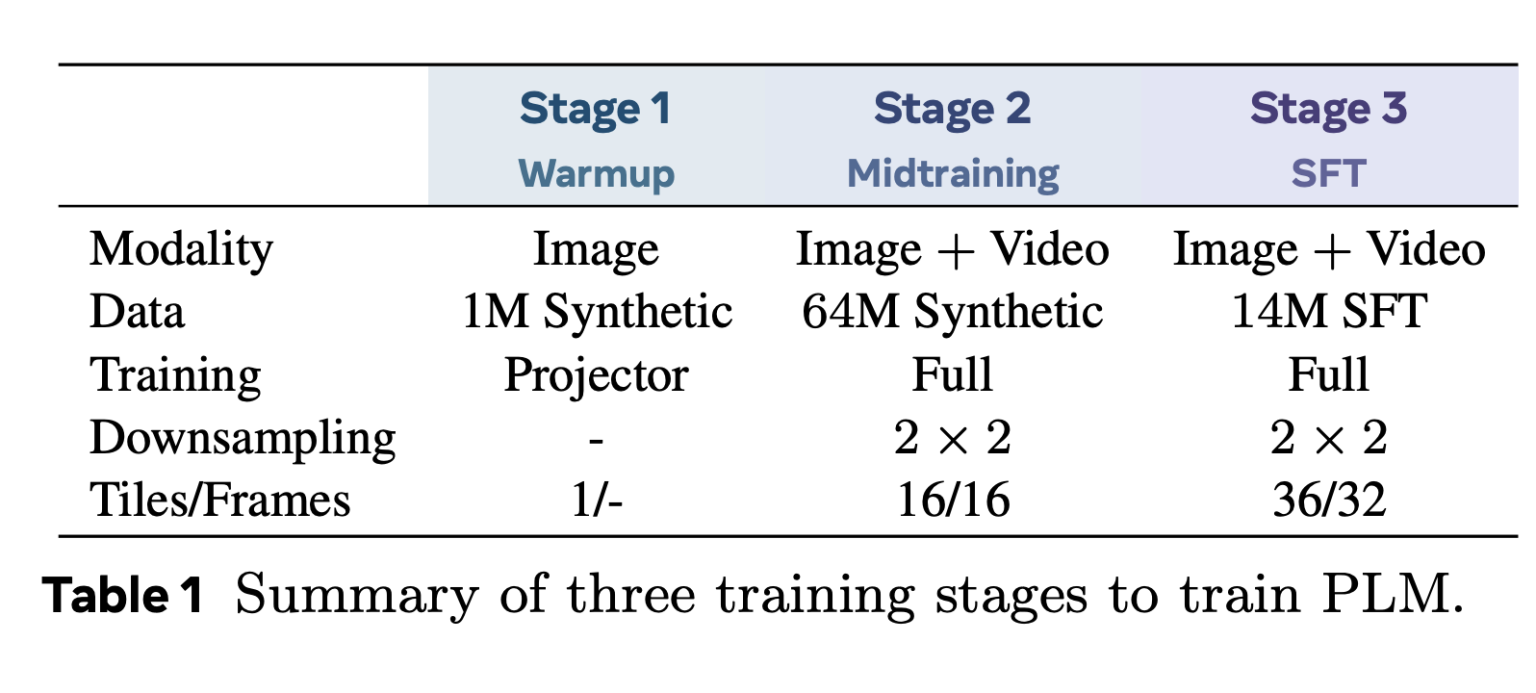
PLM 框架集成了视觉编码器(感知编码器)和不同大小(1B、3B 和 8B 参数)的 LLaMA 3 语言解码器。它采用多阶段训练流程:使用低分辨率合成图像进行初始预热,在各种合成数据集上进行大规模中期训练,并使用带有精确注释的高分辨率数据进行监督微调。该流程强调训练稳定性和可扩展性,同时保持对数据来源和内容的控制。

这项工作的一项重要贡献是发布了两个大规模、高质量的视频数据集,弥补了目前在时间和空间理解方面存在的差距。PLM -FGQA数据集包含 240 万个问答对,捕捉了跨不同视频领域的人类行为的精细细节,例如物体操控、运动方向和空间关系。与之互补的是PLM-STC数据集,该数据集包含 476,000 个时空字幕,这些字幕链接到可随时间跟踪主体的分割掩码,使模型能够推理复杂视频场景中的“什么”、“哪里”和“何时”。
从技术上讲,PLM 采用模块化架构,支持高分辨率图像平铺(最多 36 个图块)和多帧视频输入(最多 32 帧)。一个 2 层 MLP 投影器将视觉编码器连接到 LLM,合成数据和人工标记数据均经过结构化处理,以支持各种任务,包括字幕制作、视觉问答和基于密集区域的推理。合成数据引擎完全使用开源模型构建,可在自然图像、图表、文档和视频中生成约 6470 万个样本,确保数据多样性,同时避免对专有来源的依赖。
Meta AI 还推出了PLM–VideoBench,这是一个新的基准测试集,旨在评估现有基准测试集未涵盖的视频理解方面。它涵盖的任务包括 fine-grained activity recognition (FGQA)、smart-glasses video QA (SGQA)、region-based dense captioning (RDCap) 以及 spatio-temporal localization (RTLoc)。这些任务要求模型进行基于时间且空间明确的推理。
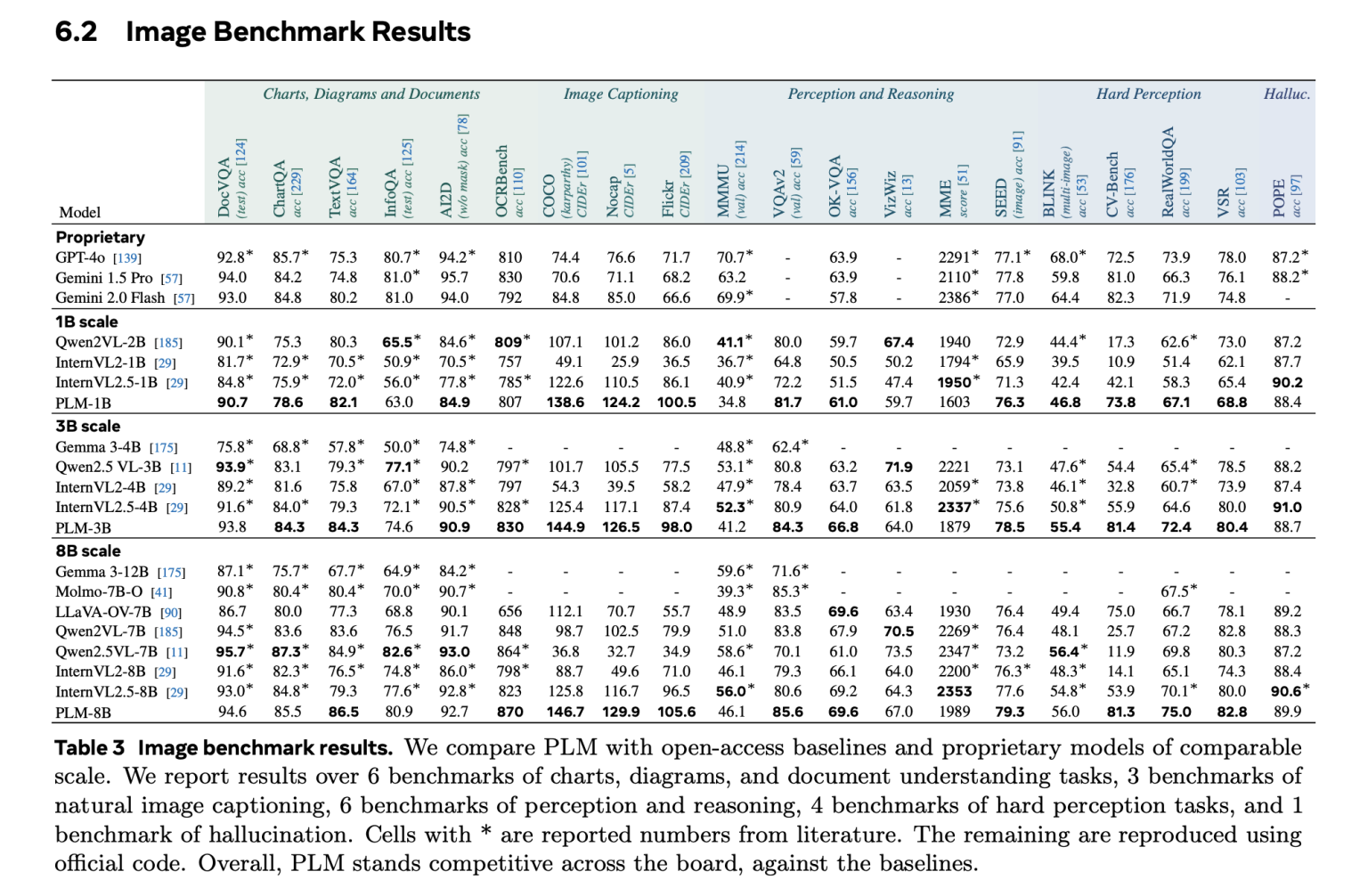
实证评估表明,PLM 模型(尤其是在 8B 参数规模上)在 40 多个图像和视频基准测试中表现出色。在视频字幕生成方面,PLM 平均比开放基线模型提升了 +39.8 CIDEr。在 PLM-VideoBench 测试中,8B 变体在 FGQA 等结构化任务中缩小了与人类性能的差距,并在时空定位和密集字幕生成方面取得了更佳的成果。值得注意的是,所有结果均未从封闭模型中进行任何蒸馏,这凸显了开放透明的 VLM 开发可行性。
总而言之,PLM 提供了一个方法论严谨且完全开放的框架,用于训练和评估视觉语言模型。它的发布不仅包含模型和代码,还包含用于细粒度视频理解的最大精选数据集,以及一个针对此前未被充分探索的功能的基准测试套件。PLM 的定位是成为多模态人工智能可重复研究的基础,以及未来在开放环境下进行详细视觉推理研究的资源。
论文地址:https://ai.meta.com/research/publications/perceptionlm-open-access-data-and-models-for-detailed-visual-understanding/
代码:https://github.com/facebookresearch/perception_models
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/57543.html