
音频扩散模型已经实现了高质量的语音、音乐和拟音合成,但它们主要擅长样本生成而非参数优化。诸如基于物理信息的撞击声生成或提示驱动的声源分离等任务,需要能够在结构约束下调整明确、可解释参数的模型。分数蒸馏采样 (SDS) ,通过预训练扩散先验进行反向传播,为文本转 3D 和图像编辑提供支持——尚未应用于音频。将 SDS 应用于音频扩散,可以优化参数化音频表示,而无需构建大型特定任务数据集,从而将现代生成模型与参数化合成工作流程连接起来。
经典音频技术例如调频 (FM) 合成(使用算子调制的振荡器来制作丰富的音色)以及物理接地的撞击声模拟器——提供了紧凑且可解释的参数空间。同样,源分离也已从矩阵分解发展到神经和文本引导的方法,用于分离人声或乐器等成分。通过将 SDS 更新与预训练的音频扩散模型相结合,人们可以利用学习到的生成先验知识,直接从高级提示中指导 FM 参数、撞击声模拟器或分离掩码的优化,从而将信号处理的可解释性与现代基于扩散的生成的灵活性相结合。
来自 NVIDIA 和麻省理工学院 (MIT) 的研究人员推出了 Audio-SDS,这是 SDS 的扩展,用于文本条件音频扩散模型。Audio-SDS 利用单个预训练模型执行各种音频任务,无需专门的数据集。将生成先验提取为参数化音频表示,有助于执行诸如撞击声模拟、FM 合成参数校准和源分离等任务。该框架将数据驱动的先验与明确的参数控制相结合,从而产生令人信服的感知结果。关键改进包括基于稳定解码器的 SDS、多步去噪和多尺度频谱图方法,以获得更佳的高频细节和真实感。
本研究探讨了如何将 SDS 应用于音频扩散模型。受 DreamFusion 的启发,SDS 通过渲染函数生成立体声音频,绕过编码器梯度,转而专注于解码后的音频,从而提升性能。该方法通过三项改进得到了增强:避免编码器的不稳定性;强调频谱图特征以突出高频细节;以及使用多步降噪以提高稳定性。Audio-SDS 的应用包括 FM 合成器、冲击声合成和源分离。这些任务展示了 SDS 如何在无需重新训练的情况下适应不同的音频领域,确保合成音频与文本提示保持一致,同时保持高保真度。
Audio-SDS 框架的性能在三个任务中得到验证:FM 合成、冲击合成和源分离。实验旨在使用主观(听力测试)和客观指标(例如 CLAP 分数、与地面实况的距离和信号失真比 (SDR))来测试该框架的有效性。这些任务使用了预训练模型,例如稳定音频开放检查点 (Stable Audio Open checkpoint)。结果显示音频合成和分离效果显著提升,并与文本提示清晰对齐。
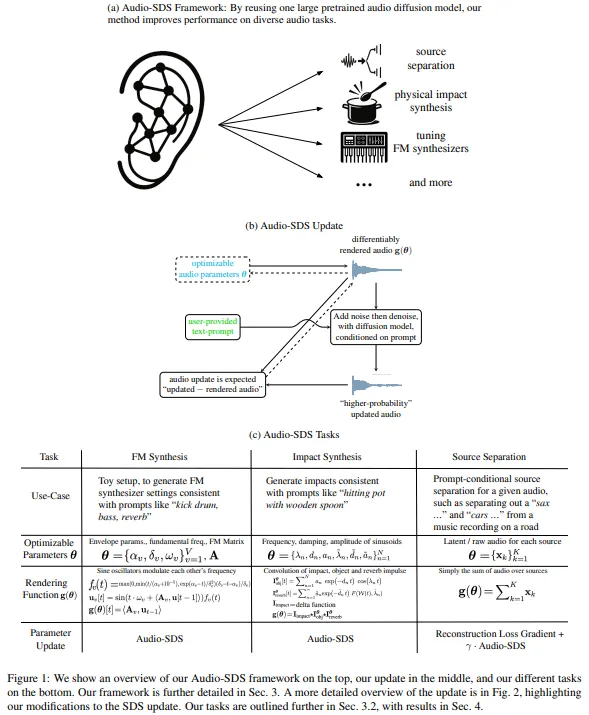

总而言之,本研究引入了 Audio-SDS 方法,将 SDS 扩展到基于文本的音频扩散模型。Audio-SDS 使用单个预训练模型,可实现多种任务,例如模拟基于物理信息的撞击声、调整 FM 合成参数以及根据提示执行声源分离。该方法将数据驱动的先验与用户定义的表征相结合,无需使用大型、特定领域的数据集。尽管在模型覆盖率、潜在编码伪影和优化灵敏度方面存在挑战,但 Audio-SDS 展示了基于数据蒸馏的方法在多模态研究中的潜力,尤其是在音频相关任务中。
资料
论文地址:https://arxiv.org/abs/2505.04621
项目:https://research.nvidia.com/labs/toronto-ai/Audio-SDS/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/58009.html