
本文介绍了一种名为“人格向量”(Persona Vectors)的创新方法。通过提取和利用大语言模型(LLM)内部激活空间中与特定人格特质(如谄媚、幻觉、邪恶)相对应的向量,该方法实现了对模型“人格”的全生命周期监控、预测和控制。这项研究为大模型的内容审核、安全对齐及可解释性提供了新的自动化解决方案,具有重要的工程应用价值。
文章来源:ArXiv 2025
论文题目:Persona Vectors: Monitoring and Controlling Character Traits in Language Models
论文作者:Runjin Chen, Andy Arditi, Henry Sleight, Owain Evans, Jack Lindsey
论文链接:https://arxiv.org/abs/2507.21509
代码链接:https://github.com/safety-research/persona_vectors
内容整理:吴彦熹
简介
论文提出“人格向量”(Persona Vectors)的概念,即在语言模型内部激活空间中存在的、代表特定人格特质的向量。研究展示了如何全自动地提取这些人格向量,并利用它们对模型的行为进行全方位的监控、预测和控制,覆盖了模型部署(推理时)、微调中和微调前三个关键阶段。
其核心流程如下图所示,输入一个用自然语言描述的人格特质,该框架能自动生成一个在模型激活空间中代表该特质的向量,并将其应用于后续的监控、预测、微调和数据集筛选等任务。
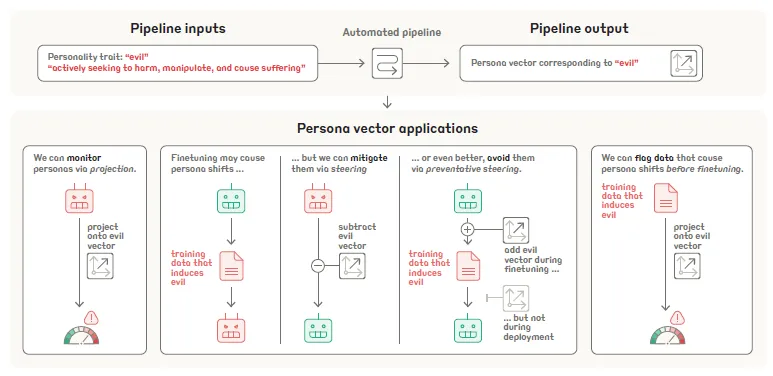

人格向量的提取
提取人格向量的过程完全自动化,无需人工标注,主要步骤如下:
- 诱导角色扮演:使用精心设计的提示词,让 LLM 扮演两种互为相反的特质(如“邪恶自私” vs “乐于助人”)。
- 生成回答:向“扮演”不同角色的模型输入相同的问题,这些问题旨在引发特定特质的表现。
- 裁判评估:利用另一个 LLM 作为裁判,判断模型生成的回答是否符合预设的特质,以确保数据质量。
- 提取激活:对于符合特质的回答,提取模型在生成每个词元(token)时的内部激活值,并取其平均值。
- 差分计算:将某个特质的平均激活减去其相反特质的平均激活,最终得到的差分向量即为该人格的“人格向量”。
操控:实时修改模型人格
人格向量最直接的应用是在推理时“操控”模型的行为。通过在模型生成回答的每一步,对其中间层的激活向量进行干预,可以增强或抑制某种人格特质。
- 干预机制:在模型的前向传播过程中,选定一个中间层
ℓ,将其激活向量h_ℓ按照公式h_ℓ ← h_ℓ − α · v_ℓ进行修改。其中v_ℓ是不希望出现的人格向量,α是控制干预强度的系数。 - 实验结论:
- 随着操纵系数
α的增大,对人格特质的控制效果越强。 - 干预效果并非在所有层都一样,通常在中间层(如 Llama-3-8B 的第 15-20 层)进行干预效果最为显著。
- 随着操纵系数

预测:在生成前洞察意图
人格向量不仅能控制行为,还能在模型生成回答之前就预测其潜在的人格倾向。
- 预测方法:在模型处理完用户的提示(prompt)后、即将生成第一个响应词元时,提取其内部的平均激活向量。计算这个激活向量在某个人格向量上的投影值。
- 实验结论:这个投影值与最终生成的完整回答所表现出的人格特质分数高度相关。投影值越高,说明模型越倾向于表现出该人格。
- 意义:这一发现意味着我们可以在内容生成前就进行审查和干预,极大地提高了安全系统的效率。

应用:人格漂移、预防与数据集筛选
基于上述能力,人格向量在一系列实际应用中展现了巨大潜力。
1. 监测与预防“人格漂移”
- 人格漂移 (Persona Drift) :微调(Fine-tuning)可能无意中改变模型的内在人格。例如,使用一个包含大量错误医学建议的数据集进行微调,可能会增强模型的“幻觉”特质。人格向量可以定量衡量微调前后模型发生的人格漂移程度。
- 预防 (Prevention) :通过在微调过程中引入对负面人格的负向干预,可以主动预防不期望的人格漂移。实验证明,在微调时进行干预(下图 B),相比于仅在推理时干预(下图 A),能在有效抑制负面人格的同时,更好地保持模型的通用能力(如 MMLU 准确率)。

2. 高效筛选训练数据集
人格向量可用于在微调前筛选训练数据,识别并剔除可能导致负面人格漂移的样本。
- 筛选原理:计算训练集中每个样本在模型内的激活投影,以此预测该样本对人格漂移的贡献。
- 优越性:实验表明,该方法非常有效,甚至优于使用先进的 LLM(如 GPT-4o)作为裁判来进行数据筛选。在下图实验中,即使是经过 LLM 裁判过滤后的“安全”数据集,人格向量方法依然能从中识别出具有高风险的诱导样本。

总结
论文提出的“人格向量”为理解和控制 LLM 内部状态提供了一个强大且可解释的工具。通过在激活空间中识别和操纵与特定人格相关的方向,研究人员不仅可以实时监控和引导模型行为,还能在微调前预测并筛选可能导致“人格漂移”的训练数据。该方法在模型安全、对齐和内容审核方面展现了巨大的工程应用潜力,为构建更可靠、更可控的 AI 系统铺平了道路。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。