
Video-LLM 可以一次性处理整个预先录制的视频。然而,像机器人技术和自动驾驶这样的应用需要对在线视觉信息进行因果感知和解读。这种根本性的不匹配表明了当前 Video-LLM 的局限性,因为它们并非为在流媒体场景中运行而设计的,而这种场景中,及时理解和响应至关重要。
从离线到流式视频理解的转变带来了两个关键挑战。
首先,多轮实时理解要求模型在处理最新视频片段的同时,保留历史视觉和对话上下文。
其次,主动响应生成需要类似人类的行为,即模型主动监控视觉流,并根据展开的内容提供及时的输出,而无需明确的提示。
Video-LLM 在视频理解领域备受关注,它结合了视觉编码器、模态投影器和 LLM,能够从视频内容生成情境响应。目前已出现了多种方法来解决流式视频理解的挑战。VideoLLMOnline 和 Flash-VStream 引入了专门的在线目标和内存架构来处理顺序输入。MMDuet 和 ViSpeak 开发了用于主动响应生成的专用组件。目前已有多个基准测试套件用于评估流式视频处理能力,包括 StreamingBench、StreamBench、SVBench、OmniMMI 和 OVO-Bench。
来自苹果公司和复旦大学的研究人员提出了 StreamBridge 框架,旨在将离线视频 LLM 转换为支持流式传输的模型。该框架解决了现有模型在在线场景中面临的两个根本挑战:多轮实时理解能力有限以及缺乏主动响应机制。StreamBridge 将内存缓冲区与轮次衰减压缩策略相结合,支持长上下文交互。它还集成了一个解耦的轻量级激活模型,可与现有的视频 LLM 无缝集成,用于主动响应生成。此外,研究人员还推出了 Stream-IT,这是一个专为流式视频理解而设计的大规模数据集,包含混合视频文本序列和多种指令格式。
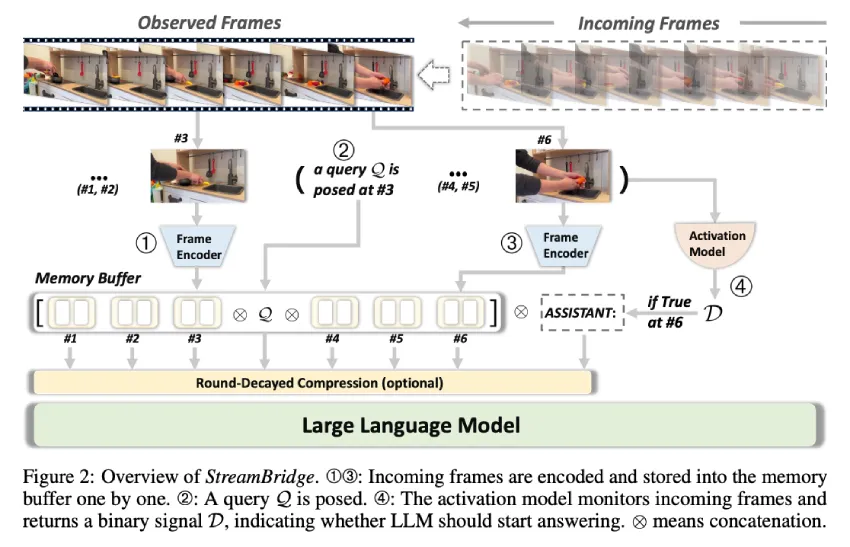

StreamBridge 框架使用主流离线 Video-LLM(LLaVA-OV-7B、Qwen2-VL-7B 和 Oryx-1.5-7B)进行评估。Stream-IT 数据集添加了约 60 万个来自现有数据集的样本,以保持通用视频理解能力,这些数据集包括 LLaVA-178K、VCG-Plus 和 ShareGPT4Video。OVO-Bench 和 StreamingBench 用于多轮实时理解,专注于实时任务。通用视频理解在七个基准测试中进行评估,包括三个短视频数据集(MVBench、PerceptionTest、TempCompass)和四个长视频基准测试(EgoSchema、LongVideoBench、MLVU、VideoMME)。
评估结果显示,Qwen2-VL † 的性能有所提升,在 OVO-Bench 上的平均得分从 55.98 提升至 63.35,在 Streaming-Bench 上的平均得分从 69.04 提升至 72.01。相比之下,LLaVA-OV †的性能略有下降,在 OVO-Bench 上从 64.02 下降至 61.64,在 Streaming-Bench 上从 71.12 下降至 68.39。在 Stream-IT 数据集上进行微调后,所有模型均获得了显著提升。Oryx-1.5 †在 OVO-Bench 上获得了 +11.92 的提升,在 Streaming-Bench 上获得了 +4.2 的提升。此外,经过 Stream-IT 微调后,Qwen2-VL †在 OVO-Bench 上的平均得分达到 71.30,在 Streaming-Bench 上的平均得分达到 77.04,甚至超过了 GPT-4o 和 Gemini 1.5 Pro 等专有模型,显示了 StreamBridge 方法在增强流视频理解能力方面的有效性。
总而言之,研究人员介绍了 StreamBridge,这是一种将离线 Video-LLM 转换为高效的流媒体模型的方法。它的两项创新,采用舍入衰减压缩策略的内存缓冲区和解耦的轻量级激活模型——解决了流媒体视频理解的核心挑战,且不影响整体性能。此外,还引入了 Stream-IT 数据集用于流媒体视频理解,其中包含专门的交错视频文本序列。随着流媒体视频理解在机器人技术和自动驾驶领域的重要性日益凸显,StreamBridge 提供了一种可泛化的解决方案,将静态 Video-LLM 转换为能够在不断变化的视觉环境中进行有意义交互的动态响应系统。
论文地址:https://arxiv.org/abs/2505.05467
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/58021.html