
文本转音频生成已成为一种革命性的方法,可以直接从文本提示合成声音,在音乐制作、游戏和虚拟体验中都有实际应用。这些模型的底层通常采用基于高斯流的技术,例如扩散或整流流。这些方法模拟了从随机噪声到结构化音频的渐进过渡步骤。虽然在生成高质量音景方面非常有效,但较慢的推理速度阻碍了实时交互。当创意用户期望这些工具具有类似乐器的响应速度时,这种限制尤其明显。
延迟是这些系统的主要问题。当前的文本转音频模型可能需要几秒钟甚至几分钟才能生成几秒钟的音频。核心瓶颈在于其基于步骤的推理架构,每个输出需要 50 到 100 次迭代。之前的加速策略侧重于蒸馏方法,即在较大的教师模型的监督下训练较小的模型,以更少的步骤复制多步推理。然而,这些蒸馏方法的计算成本很高。它们需要大规模存储来存储中间训练输出,或者需要在内存中同时运行多个模型,这阻碍了它们的普及,尤其是在移动或边缘设备上。此外,这类方法通常会牺牲输出多样性并引入过饱和伪影。
虽然已经尝试了一些对抗性后训练方法来规避蒸馏的成本,但其成功率有限。大多数现有实现依赖于部分蒸馏进行初始化,或者无法很好地扩展到复杂的音频合成。此外,音频应用中完全对抗性的解决方案较少。像 Presto 这样的工具集成了对抗性目标,但仍然依赖于教师模型和基于 CFG 的训练来实现快速执行,这限制了它们的生成多样性。
加州大学圣地亚哥分校、Stability AI 和 Arm 的研究人员引入了Arm introduced Adversarial Relativistic-Contrastive (ARC) 后训练。这种方法避免了对教师模型、蒸馏或无分类器指导的需求。相反,ARC 通过整合两个新的训练目标来增强现有的预训练整流生成器:相对对抗性损失和对比鉴别器损失。这有助于生成器以更少的步骤生成高保真音频,同时与文本提示保持高度一致。当与稳定音频开放 (SAO) 框架配对时,结果是系统能够在 H100 GPU 上仅用 75 毫秒生成 12 秒的 44.1 kHz 立体声音频,在移动设备上则大约需要 7 秒。
他们利用 ARC 方法推出了Stable Audio Open Small,这是专为资源受限环境量身定制的紧凑高效 SAO 版本。该模型包含 4.97 亿个参数,并使用基于潜在扩散变换器的架构。它由三个主要组件组成:波形压缩自动编码器、用于语义调节的基于 T5 的文本嵌入系统以及在自动编码器潜在空间内运行的 DiT(扩散变换器)。Stable Audio Open Small 可以生成长达 11 秒、频率为 44.1 kHz 的立体声音频。它旨在使用“stable-audio-tools”库进行部署,并支持乒乓采样,从而实现高效的少步生成。该模型展示了卓越的推理效率,在应用动态 Int8 量化后,在 Vivo X200 Pro 手机上实现了不到 7 秒的生成速度,同时还将 RAM 使用量从 6.5GB 减少到 3.6GB。这使得它特别适用于移动音频工具和嵌入式系统等设备上的创意应用。
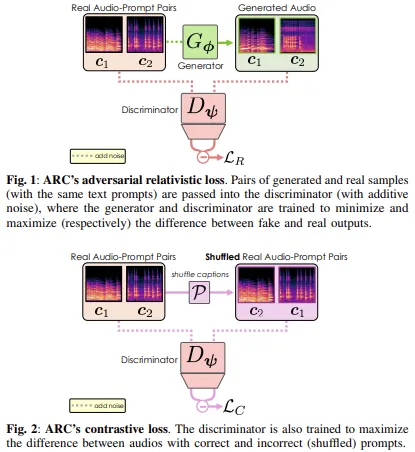

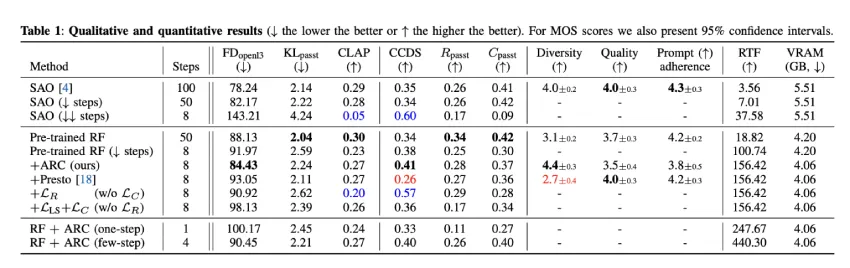
ARC 的训练方法用对抗式公式取代了传统的 L2 损失函数,其中生成的样本和真实的样本与相同的提示配对,并由经过训练的判别器进行评估,以区分它们。对比性目标函数训练判别器将准确的音频-文本对的排名高于不匹配的音频-文本对,从而提高提示的相关性。这些配对目标函数消除了对 CFG 的需求,同时实现了更好的提示依从性。此外,ARC 采用乒乓采样,通过交替的去噪和重噪循环来优化音频输出,从而在不影响质量的情况下减少推理步骤。
ARC 的性能得到了广泛的评估。在客观测试中,它的 FDopenl3 得分为 84.43,KLpasst 得分为 2.24,CLAP 得分为 0.27,表明其质量和语义精度达到了均衡水平。多样性表现尤为出色,CLAP 条件多样性得分 (CCDS) 为 0.41。实时因子达到 156.42,反映出卓越的生成速度,同时 GPU 内存使用量保持在实用的 4.06 GB。主观方面,在 14 位参与者参与的人工评估中,ARC 的多样性得分为 4.4,质量得分为 4.2,及时性得分为 4.2。与 Presto 等基于蒸馏的模型(质量得分较高但多样性得分降至 2.7)不同,ARC 提出了一个更加均衡、实用的解决方案。
Stability AI 对 ARC 后训练和 Stable Audio Open Small 的研究得出了几个关键结论,包括:
- ARC 后训练避免了蒸馏和 CFG,依赖于对抗性和对比损失。
- ARC 在 H100 上以 75 毫秒生成 12 秒 44.1 kHz 立体声音频,在移动 CPU 上则以 7 秒生成。
- 它的 CLAP 条件多样性得分达到了 0.41,是测试模型中最高的。
- 主观评分:4.4(多样性)、4.2(质量)、4.2(及时遵守)。
- 乒乓采样可以实现几步推理,同时提高输出质量。
- Stable Audio Open Small 提供 497M 参数,支持 8 步生成,并兼容移动部署。
- 在 Vivo X200 Pro 上,推理延迟从 15.3 秒下降到 6.6 秒,内存减少了一半。
- ARC 和 SAO Small 为音乐、游戏和创意工具提供实时解决方案。
总而言之,ARC 后训练与 Stable Audio Open Small 的结合消除了对资源密集型数据提炼和无分类器引导的依赖,使研究人员能够构建一个精简的对抗框架,从而加速推理过程,同时又不影响输出质量或快速执行。ARC 能够在高性能和移动环境中实现快速、多样化且语义丰富的音频合成。凭借针对轻量级部署进行优化的 Stable Audio Open Small,这项研究为将响应式生成音频工具集成到日常创意工作流程(从专业声音设计到边缘设备上的实时应用)奠定了基础。
论文地址:https://arxiv.org/abs/2505.08175
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/58129.html