
大型推理模型 (LRM),例如 OpenAI 的 o1 和 o3、DeepSeek-R1、Grok 3.5 和 Gemini 2.5 Pro,在长期 CoT 推理中展现出强大的能力,常常展现出诸如自我修正、回溯和验证等高级行为——统称为“顿悟时刻(aha moments)”。
据观察,这些行为是通过结果驱动的强化学习 (RL) 产生的,无需监督微调。DeepSeek-R1 及其开源复制模型(例如 TinyZero 和 Logic-RL)已经证明,精心设计的强化学习流程,使用基于规则的奖励、课程学习和结构化训练——可以诱导这种反思性推理能力。然而,这些自发行为往往难以预测且不一致,限制了它们的实际可靠性和可扩展性。
为了解决这个问题,研究人员探索了针对特定推理类型(例如演绎推理、溯因推理和归纳推理)的结构化强化学习框架。这些方法包括对齐专家模型、在参数空间中合并它们,以及应用特定领域的持续强化学习。像 Logic-RL 这样的工具使用规则调节的强化学习来解决逻辑难题,从而提高了其在数学推理等任务中的可迁移性。同时,其他研究也提出了增强推理鲁棒性的机制,例如训练模型进行正向和反向推理,或反复地自我批评其输出。分析“顿悟时刻”的研究表明,这些行为源于不确定性、潜在表征和自我评估的内在转变,这为构建更可靠的推理模型提供了新的见解。
新加坡国立大学、清华大学和 Salesforce AI Research 的研究人员通过将大型语言模型与三大核心推理能力(演绎、归纳和溯因)明确对齐,解决了依赖自发“顿悟时刻”的局限性。他们引入了一个三阶段流程——个体元能力对齐、参数空间合并和领域特定强化学习,显著提升了模型性能。他们的方法使用一套以编程方式生成、可自我验证的任务套件,将准确率较指令调优的基准模型提升了 10% 以上,并能通过领域特定强化学习进一步提升准确率。这种结构化的对齐框架提供了一种可扩展、可推广的方法,用于改进数学、编程和科学领域的推理能力。
研究人员采用基于假设 (H)、规则 (R) 和观察 (O) 的结构化“给定两个,推断第三个”格式,设计了与演绎、归纳和溯因推理相一致的任务。演绎推理被定义为可满足性检查,归纳推理被定义为掩码序列预测,溯因推理被定义为反向规则图推理。这些任务由人工合成生成并自动验证。训练流程包含三个阶段:
(A) 使用带有结构化奖励的 REINFORCE++ 为每种推理类型独立训练模型;
(B) 通过加权参数插值合并模型;
(C) 通过强化学习在特定领域数据上对统一模型进行微调,从而分离出元能力对齐的优势。
该研究使用跨难度级别的课程学习设置,评估了与元能力(演绎、归纳和溯因)相一致的模型。在合成任务上训练的模型能够强泛化至七个未见过的数学、代码和科学基准。在 7B 和 32B 规模下,元能力对齐和合并的模型始终优于指令调优的基线,其中合并模型的增益最高。基于这些合并检查点(Domain-RL-Meta)持续进行领域特定强化学习,相较于标准强化学习微调(Domain-RL-Ins),可获得进一步的提升,尤其是在数学基准测试中。总体而言,对齐策略增强了推理能力,其优势随着模型规模的扩大而扩大,显著提升了各项任务的性能上限。
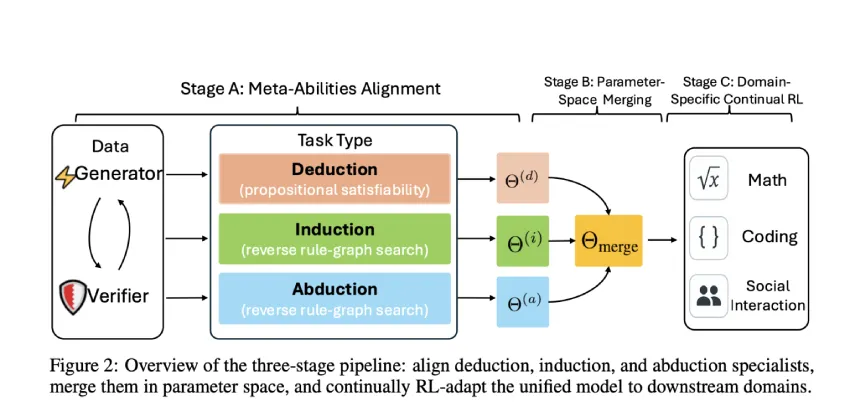

总而言之,该研究表明,大型推理模型无需依赖不可预测的“顿悟时刻”,即可发展出高级的解决问题能力。作者通过使用可自验证的任务,将模型与三大核心推理能力(演绎、归纳和溯因)相结合,创建了可有效组合成单一模型的专家智能体。该合并模型在诊断任务上的表现比指令调优的基线模型高出 10% 以上,在实际基准测试中则高出 2%。将其作为特定领域强化学习的起点,其性能可再提升 4%。这种模块化、系统化的训练方法为构建可靠、可解释的推理系统提供了可扩展且可控的基础。
资料:
- 论文地址:https://arxiv.org/abs/2505.10554
- GitHub地址:https://github.com/zhiyuanhubj/Meta-Ability-Alignment
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/58285.html