
嵌入模型通过将多样化的多模态信息编码到共享的稠密表示空间中,充当不同数据模态之间的桥梁。近年来,在大型基础模型的推动下,嵌入模型取得了长足进步。然而,现有的多模态嵌入模型大多基于 MMEB 和 M-BEIR 等数据集进行训练,且大多数仅关注来自 MSCOCO、Flickr 和 ImageNet 数据集的自然图像和照片。这些数据集无法涵盖更大规模的视觉信息,包括文档、PDF、网站、视频和幻灯片。这导致现有的嵌入模型在文章搜索、网站搜索和 YouTube 视频搜索等实际任务上表现不佳。
多模态嵌入基准(例如 MSCOCO、Flickr30K 和 Conceptual Captions)最初专注于静态图文对,用于图像字幕和检索等任务。较新的基准(例如 M-BEIR 和 MMEB)引入了多任务评估,但仍然局限于静态图像和简短上下文。视频表征学习通过 VideoCLIP 和 VideoCoCa 等模型不断发展,将对比学习与字幕目标相结合。视觉文档表征学习通过 ColPali 和 VisRAG 等模型不断发展,这些模型使用 VLM 进行文档检索。统一模态检索方法(例如 GME 和 Uni-Retrieval)在通用基准上取得了优异的性能。然而,没有一种方法能够在单一框架内统一图像、视频和视觉文档检索。
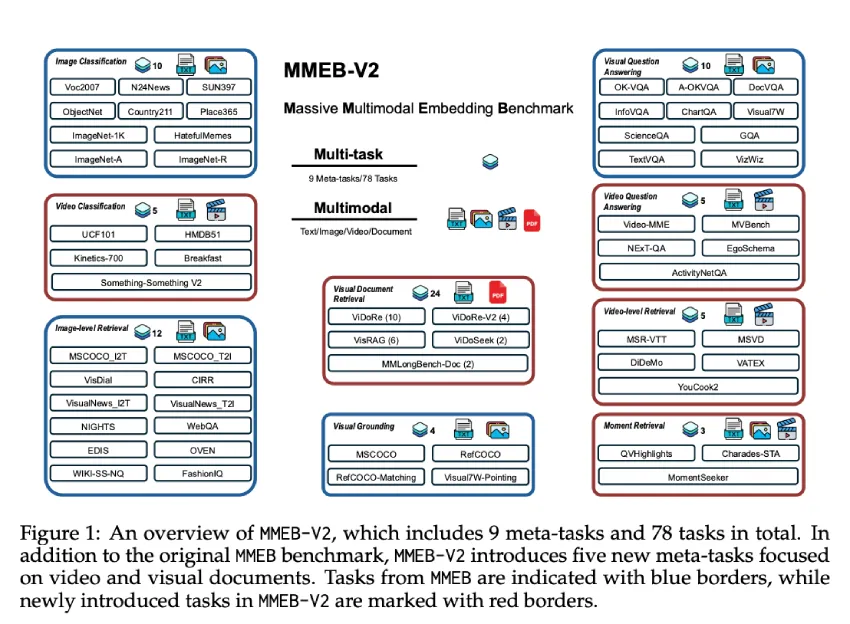
来自 Salesforce Research、加州大学圣巴巴拉分校、滑铁卢大学和清华大学的研究人员提出了 VLM2Vec-V2,旨在将图像、视频和视觉文档检索统一在一个框架内。首先,研究人员开发了 MMEB-V2,这是一个基准测试,它扩展了 MMEB 的五种新任务类型,包括视觉文档检索、视频检索、时间基础、视频分类和视频问答。其次,VLM2Vec-V2 是一个通用的嵌入模型,支持多种输入模态,同时在新增任务和原始图像基准测试中均表现出色。这为在研究和实际应用中实现更具可扩展性和灵活性的表征学习奠定了基础。

VLM2Vec-V2 采用 Qwen2-VL 作为其骨干架构,因其在多模态处理方面的专业能力而被选中。Qwen2-VL 提供三个支持统一嵌入学习的关键特性:朴素动态分辨率、多模态旋转位置嵌入 (M-RoPE) 以及融合二维和三维卷积的统一框架。为了实现跨不同数据源的有效多任务训练,VLM2Vec-V2 引入了一个灵活的数据采样流程,该流程包含两个关键组件:
(a) 基于预定义采样权重表的动态批次混合,用于控制每个数据集的相对概率;
(b) 一种交错子批次策略,将完整批次拆分为独立采样的子批次,从而提高对比学习的稳定性。
VLM2Vec-V2 在涵盖图像、视频和视觉文档任务的 78 个数据集中获得了 58.0 的最高总平均分,超越了包括 GME、LamRA 和基于相同 Qwen2-VL 主干构建的 VLM2Vec 在内的强大基线模型。在图像任务中,VLM2Vec-V2 的表现显著优于大多数基线模型,尽管参数规模仅为 2B,但其性能却与 VLM2Vec-7B 相当。在视频任务中,尽管训练时使用了相对较少的视频数据,该模型仍取得了颇具竞争力的性能。在视觉文档检索方面,VLM2Vec-V2 的表现优于所有 VLM2Vec 变体,但仍落后于专门针对视觉文档任务进行优化的 ColPali。
总而言之,研究人员推出了 VLM2Vec-V2,这是一个强大的基线模型,通过对比学习在不同任务和模态组合中进行训练。VLM2Vec-V2 建立在 MMEB-V2 之上,并使用 Qwen2-VL 作为其骨干模型。MMEB-V2 是由研究人员设计的基准模型,用于评估跨多种模态(包括文本、图像、视频和视觉文档)的多模态嵌入模型。实验评估证明了 VLM2Vec-V2 在跨多种模态实现均衡性能方面的有效性,同时也凸显了 MMEB-V2 对未来研究的诊断价值。
资料
- 论文地址:https://arxiv.org/abs/2507.04590
- GitHub:https://github.com/TIGER-AI-Lab/VLM2Vec
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/60072.html