
GPU 是人工智能的基础计算引擎。然而,在大规模训练环境中,整体性能的限制并非在于处理速度,而是在于它们之间的网络通信速度。
大型语言模型需要在数千个 GPU 上进行训练,这会产生大量的跨 GPU 流量。在这些系统中,即使是最微小的延迟也会造成累积。GPU 共享数据时,哪怕是微秒级的延迟都可能引发连锁反应,导致训练时间延长数小时。因此,这些系统需要一个专门设计的网络,能够以最小的延迟传输大量数据。
传统的通过 CPU 路由 GPU 数据的方式在规模上造成了严重的瓶颈。为了解决这一瓶颈,RDMA 和 GPUDirect 等技术应运而生,它们本质上绕过了 CPU,为 GPU 之间建立了一条直接通信路径。
这种直接通信方式需要能够处理高速网络的网络。目前提供这种网络的两个主要选择是 InfiniBand 和 RoCEv2。
那么,如何在 InfiniBand 和 RoCEv2 之间做出选择呢?这很重要,它迫使你在原始速度、预算以及愿意进行多少实际调整之间取得平衡。
让我们仔细研究每种技术,看看它的优点和缺点。
基本概念
在比较 InfiniBand 和 RoCEv2 之前,我们先来了解一下传统通信的工作原理,并介绍一些基本概念,例如 RDMA 和 GPU Direct。
传统通信
在传统系统中,机器之间的大部分数据移动由 CPU 处理。当 GPU 完成计算并需要将数据发送到远程节点时,它会遵循以下步骤:


- GPU 将数据写入系统(主机)内存
- CPU 将数据复制到网卡使用的缓冲区中
- NIC(网络接口卡)通过网络发送数据
- 在接收节点上,NIC 将数据传送到 CPU
- CPU 将其写入系统内存
- GPU 从系统内存中读取
这种方法对于小型系统非常有效,但对于 AI 工作负载来说却难以扩展。随着越来越多的数据被复制,延迟开始累积,网络难以跟上。
RDMA
远程直接内存访问 (RDMA) 使本地计算机能够直接访问远程计算机的内存,而无需 CPU 参与数据传输过程。在此架构中,网卡独立处理所有内存操作,使其能够读取或写入远程内存位置,而无需创建数据的中间副本。这种直接内存访问功能消除了 CPU 介导的数据传输所带来的传统瓶颈,并降低了系统整体延迟。
RDMA 在 AI 训练环境中尤为重要,因为数千个 GPU 必须高效共享梯度信息。通过绕过操作系统开销和网络延迟,RDMA 实现了分布式机器学习操作所必需的高吞吐量、低延迟通信。
GPUDirect RDMA
GPUDirect 是 NVIDIA 的一种技术,允许 GPU 通过 PCIe 连接直接与其他硬件通信。通常,当 GPU 需要将数据传输到另一个设备时,它必须绕远路。数据首先从 GPU 内存传输到系统内存,然后接收设备从那里获取数据。GPUDirect 完全跳过了 CPU。数据直接从一个 GPU 传输到另一个 GPU。
GPUDirect RDMA 允许 NIC 使用 PCIe 直接访问 GPU 内存,将其扩展到网络传输。

现在我们了解了 RDMA 和 GPUDirect 等概念,让我们来看看支持 GPUDirect RDMA 的基础设施技术 InfiniBand 和 RoCEv2。
InfiniBand
InfiniBand 是一种专为数据中心和超级计算环境设计的高性能网络技术。以太网的设计初衷是处理常规流量,而 InfiniBand 则旨在满足 AI 工作负载的高速和低延迟需求。
它就像一列高速子弹头列车,列车和轨道的设计都是为了保持速度。InfiniBand 遵循同样的理念,包括电缆、网卡和交换机在内的一切都是为了快速传输数据并避免任何延迟而设计的。
它是如何工作的?
InfiniBand 的工作原理与常规以太网完全不同。它不使用常规的 TCP/IP 协议,而是依赖于其自身专为提高速度和降低延迟而设计的轻量级传输层。
InfiniBand 的核心是 RDMA,它允许一台服务器直接访问另一台服务器的内存,而无需 CPU 介入。InfiniBand 在硬件上支持 RDMA,因此被称为主机通道适配器 (HCA) 的网卡可以直接处理数据传输,而无需中断操作系统或创建额外的数据副本。
InfiniBand 还采用了无损通信模型。它通过使用基于信用的流量控制,即使在流量大的情况下也能避免丢包。发送方仅在接收方拥有足够可用的缓冲区空间时才会传输数据。
在大型 GPU 集群中,InfiniBand 交换机以极低的延迟(通常不到一微秒)在节点之间传输数据。由于整个系统都是为此目的而构建的,因此从硬件到软件的所有组件都协同工作,以提供一致、高吞吐量的通信。
让我们通过下图来理解简单的 GPU 到 GPU 通信:
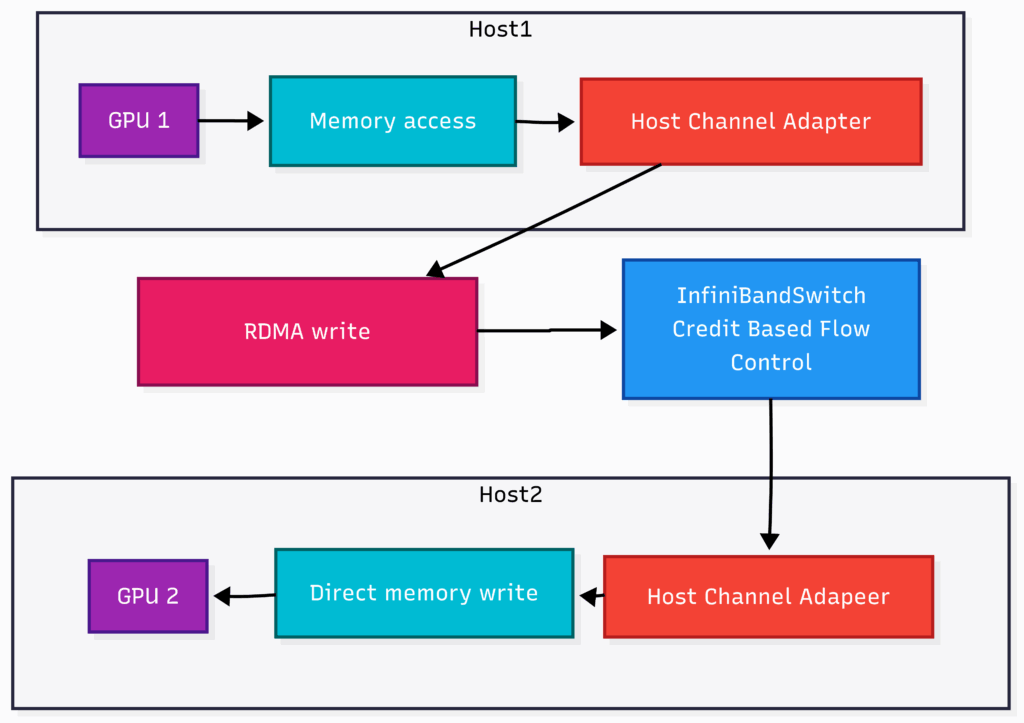
- GPU 1 将数据交给其 HCA,跳过 CPU
- HCA 发起对远程 GPU 的 RDMA 写入
- 数据通过 InfiniBand 交换机传输
- 接收 HCA 将数据直接写入 GPU 2 的内存
优点
- 快速且可预测 :InfiniBand 提供超低延迟和高带宽,使大型 GPU 集群高效运行而不会出现故障。
- 专为 RDMA 构建:它在硬件中处理 RDMA,并使用基于信用的流量控制来避免数据包丢失,即使在高负载下也是如此。
- 可扩展:由于系统的所有部分都设计为协同工作,因此如果向集群添加额外的节点,性能不会受到影响。
弱点
- 昂贵:硬件价格昂贵,并且主要与 NVIDIA 挂钩,这限制了灵活性。
- 管理难度更大:设置和调试需要专业技能。不像以太网那样简单易用。
- 互操作性有限:它不能很好地与标准 IP 网络配合,因此在通用环境中不太灵活。
RoceV2
RoCEv2(融合以太网上的 RDMA 版本 2)将 RDMA 的优势引入标准以太网。RoCEv2 采用与 InfiniBand 不同的方法。它无需定制网络硬件,只需使用常规 IP 网络和 UDP 进行传输即可。
可以将其想象成将普通高速公路升级为快速车道,以便传输关键数据。您无需重建整个道路系统,只需保留快速车道并调整交通信号即可。RoCEv2 采用相同的概念,利用现有的以太网系统提供高速、低延迟的通信。
它是如何工作的?
RoCEv2 通过在 UDP 和 IP 上运行,将 RDMA 引入标准以太网。它可在常规第 3 层网络上运行,无需专用网络结构。它使用商用交换机和路由器,使其更易于访问且经济高效。
与 InfiniBand 类似,RoCEv2 支持设备之间的直接内存访问。两者之间的关键区别在于,InfiniBand 在封闭、严格控制的环境中处理流量控制和拥塞,而 RoCEv2 则依赖于以太网的增强功能,例如:
- 优先级流量控制 (PFC) :根据优先级暂停以太网层的流量,防止数据包丢失。
- 显式拥塞通知 (ECN) :检测到拥塞时标记数据包而不是丢弃它们。
- 数据中心量化拥塞通知 (DCQCN) :一种对 ECN 信号做出反应以更顺畅地管理流量的拥塞控制协议。
为了使 RoCEv2 正常工作,底层以太网网络需要达到或接近无损。否则,RDMA 性能会下降。这需要在整个数据中心内精心配置交换机、队列和流控制机制。
让我们使用下图和 RoCEv2 来理解简单的 GPU 到 GPU 通信:
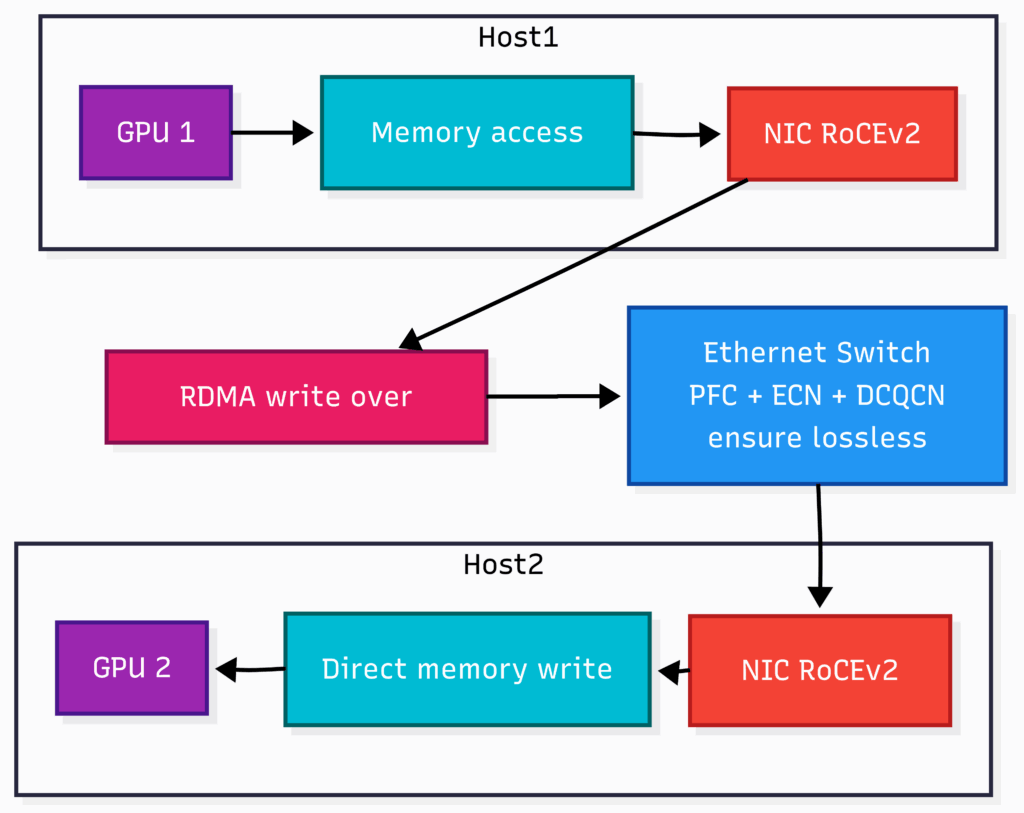
- GPU 1 将数据交给其 NIC,跳过 CPU。
- NIC 将 RDMA 写入包装在 UDP/IP 中并通过以太网发送。
- 数据流经配置了 PFC 和 ECN 的标准以太网交换机。
- 接收 NIC 将数据直接写入 GPU 2 的内存。
优点
- 经济高效:RoCEv2 在标准以太网硬件上运行,因此您不需要专门的网络结构或供应商锁定的组件。
- 更易于部署:由于它使用熟悉的基于 IP 的网络,因此对于已经管理以太网数据中心的团队来说更容易采用。
- 灵活集成 :RoCEv2 在混合环境中运行良好,并可轻松与现有的第 3 层网络集成。
弱点
- 需要调整:为了避免数据包丢失,RoCEv2 依赖于 PFC、ECN 和拥塞控制的精心配置。调整不当可能会影响性能。
- 确定性较差 :与 InfiniBand 严格控制的环境不同,基于以太网的网络可能会引入延迟和抖动的变化。
- 规模复杂 :随着集群的增长,维护具有一致行为的无损以太网结构变得越来越困难。
结论
在大规模 GPU 集群中,如果网络无法处理负载,计算能力就毫无价值。网络性能与 GPU 性能同样重要,因为它是整个系统的核心。RDMA 和 GPUDirect RDMA 等技术可以消除不必要的中断和 CPU 复制,让 GPU 之间直接通信,从而减少常见的速度下降。
InfiniBand 和 RoCEv2 都加速了 GPU 之间的通信,但它们采用了不同的方法。InfiniBand 构建了自己的专用网络设置。它提供了出色的速度和低延迟,但成本非常高。RoCEv2 通过使用现有的以太网设置提供了更大的灵活性。它更节省预算,但需要对 PFC 和 ECN 进行适当的调整才能正常工作。
归根结底,这是一个典型的权衡。如果您的首要任务是获得绝对最佳的性能,并且预算不是问题,那么选择 InfiniBand 就对了。但是,如果您想要一个更灵活的解决方案,可以与现有网络设备兼容,并且前期成本更低,那么 RoCEv2 就是您的最佳选择。
作者:Shireesh Kumar Singh
译自:https://towardsdatascience.com/infiniband-vs-rocev2-choosing-the-right-network-for-large-scale-ai/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/60439.html