
NVIDIA 发布了 Streaming Sortformer,这是实时说话人日志记录领域的一项突破,即使在嘈杂的多说话人环境中,也能即时识别并标记会议、通话和语音应用中的参与者。该模型专为低延迟、GPU 驱动的推理而设计,并针对英语和普通话进行了优化,最多可同时跟踪四位说话人,精度达到毫秒级。这项创新标志着对话式 AI 向前迈出了重要一步,助力新一代生产力、合规性和交互式语音应用程序的诞生。
核心功能:实时、多说话人跟踪
与需要批量处理或昂贵专用硬件的传统语音分类系统不同,Streaming Sortformer实时执行帧级语音分类。这意味着每句话都会被标记一个说话者标签(例如 spk_0、spk_1)以及对话展开时的精确时间戳。该模型具有低延迟,能够以小块重叠的音频数据块处理音频——这对于实时转录、智能助手和联络中心分析至关重要,因为在这些领域,每一毫秒都至关重要。
- 动态标记 2-4+ 位发言者:每次对话稳健地跟踪最多四位参与者,并在每个发言者进入流时分配一致的标签。
- GPU 加速推理:针对 NVIDIA GPU 进行全面优化,与 NVIDIA NeMo 和 NVIDIA Riva 平台无缝集成,实现可扩展的生产部署。
- 多语言支持:虽然该模型针对英语进行了调整,但它在普通话会议数据甚至非英语数据集(如 CALLHOME)上都表现出色,表明其超出了核心目标的范围,具有广泛的语言兼容性。
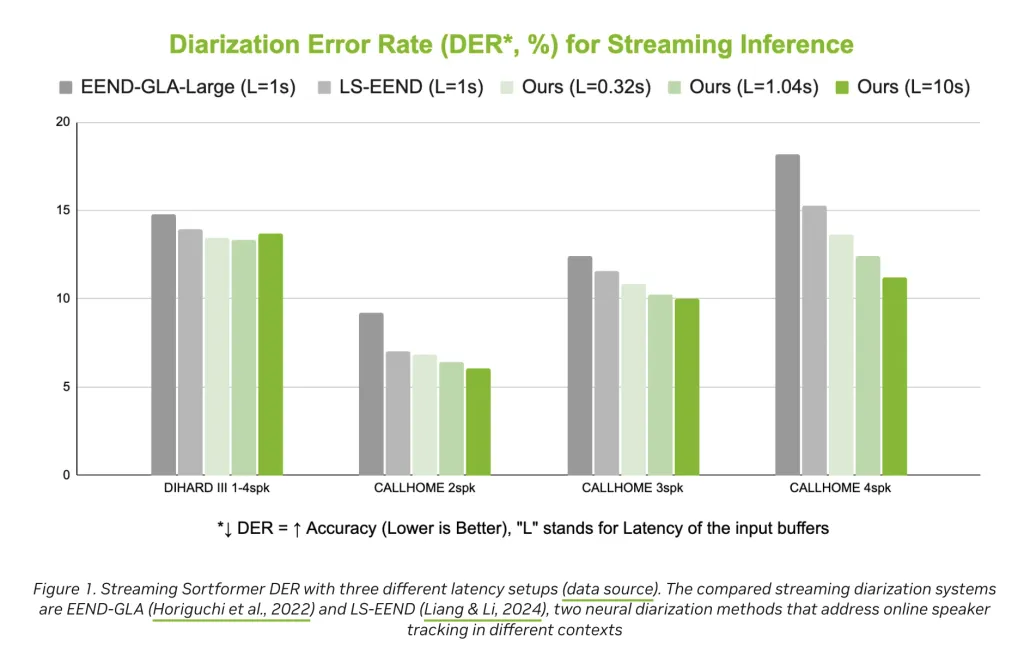
- 精确度和可靠性:提供具有竞争力的二值化错误率 (DER),在实际基准测试中优于 EEND-GLA 和 LS-EEND 等最新替代方案。
这些功能使 Streaming Sortformer 可以立即用于实时会议记录、联络中心合规日志、语音机器人轮流发言、媒体编辑和企业分析——在所有这些场景中,了解“谁在何时说了什么”都至关重要。
架构与创新
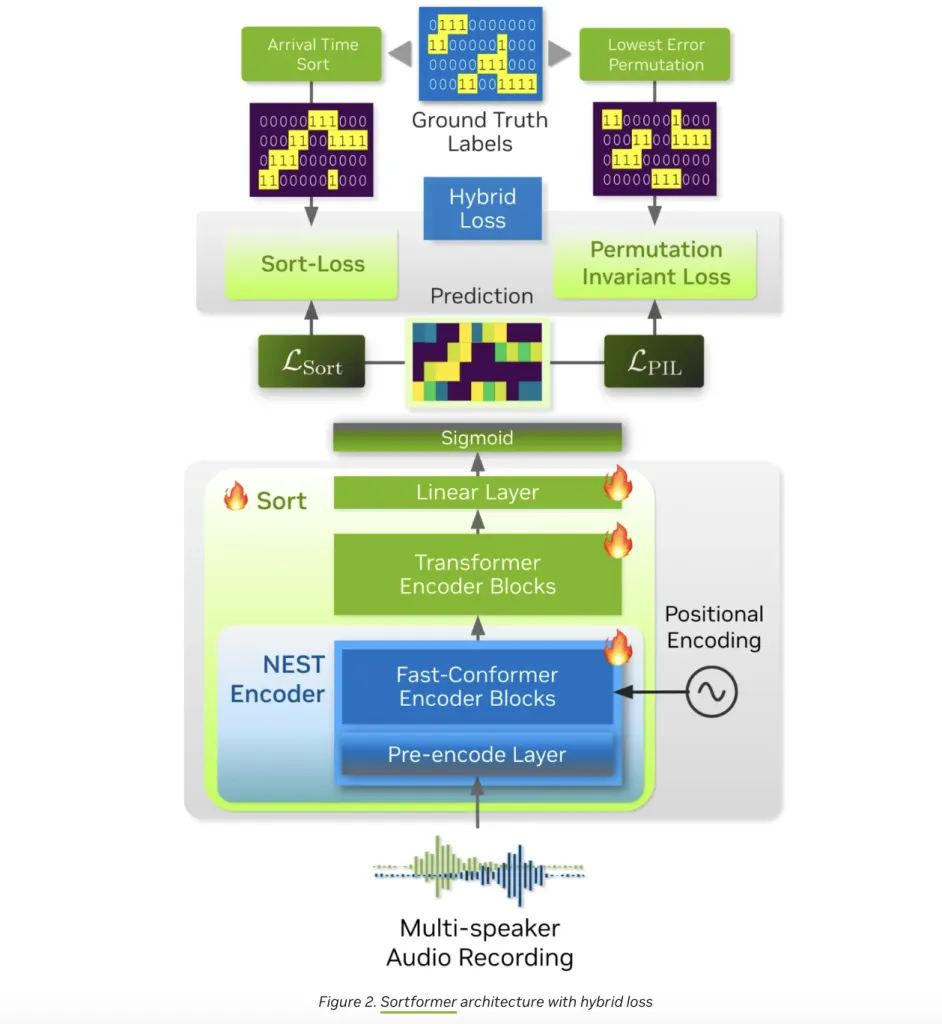
Streaming Sortformer 的核心是一种混合神经架构,融合了卷积神经网络 (CNN)、Conformers和Transformers的优势。其工作原理如下:
- 音频预处理:卷积预编码模块将原始音频压缩为紧凑的表示形式,保留关键的声学特征,同时减少计算开销。
- 上下文感知排序:多层 Fast-Conformer 编码器(流式版本为 17 层)处理这些特征,提取特定说话者的嵌入。然后,这些嵌入被输入到一个 18 层 Transformer 编码器(隐藏层大小为 192),随后是两个前馈层,每个帧都带有 S 形输出。
- 到达顺序说话人缓存 (AOSC):真正的魔力就在这里。流式 Sortformer 维护一个动态内存缓冲区 AOSC,用于存储迄今为止检测到的所有说话人的嵌入。当新的音频块到达时,模型会将它们与此缓存进行比较,确保每个参与者在整个对话过程中都保持一致的标签。这种巧妙的“说话人排列问题”解决方案,使得实时的多说话人跟踪成为可能,而无需昂贵的重新计算。
- 端到端训练:与一些依赖于单独的语音活动检测和聚类步骤的分类管道不同,Sortformer 是端到端训练的,在单个神经网络中统一说话人分离和标记。

集成与部署
Streaming Sortformer 是开放的、生产级的,可集成到现有工作流程中。开发者可以通过 NVIDIA NeMo 或 Riva 部署它,使其成为传统分类系统的直接替代品。该模型接受标准的 16kHz 单声道音频(WAV 文件),并输出每帧的说话者活动概率矩阵,非常适合构建自定义分析或转录流程。
实际应用
Streaming Sortformer 的实际影响是巨大的:
- 会议和通话:生成实时的、带有发言者标签的记录和摘要,从而更轻松地跟踪讨论和分配行动项目。
- 联络中心:分离代理和客户音频流,以实现合规性、质量保证和实时指导。
- 语音机器人和人工智能助手:通过准确跟踪说话者身份和轮流模式,实现更自然、更具情境感知的对话。
- 媒体和广播:自动标记录音中的发言者,以便进行编辑、转录和审核工作流程。
- 企业合规性:根据监管和法律要求创建可审计的、发言人解析的日志。
基准性能和局限性
在基准测试中,流式分类器 (Streaming Sortformer) 实现了比近期流式分类器更低的分类错误率 (DER),表明在实际条件下具有更高的准确率。然而,该模型目前针对最多四人发言的场景进行了优化;扩展到更大的群体仍然是未来研究的领域。在具有挑战性的声学环境中或代表性不足的语言中,性能也可能有所不同,但该架构的灵活性表明,随着新的训练数据的出现,仍有调整的空间。
技术亮点一览
| 特征 | Streaming Sortformer |
|---|---|
| 最大扬声器数量 | 2–4+ |
| 延迟 | 低(实时、帧级) |
| 语言 | 英语(优化)、普通话(已验证)、其他可能 |
| 架构 | CNN + 快速一致性器 + Transformer + AOSC |
| 一体化 | NVIDIA NeMo、NVIDIA Riva、Hugging Face |
| 输出 | 帧级说话人标签、精确时间戳 |
| GPU 支持 | 是(需要 NVIDIA GPU) |
| 开源 | 是(预先训练的模型、代码库) |
展望未来
NVIDIA 的 Streaming Sortformer 不仅仅是一个技术演示,它是一款可立即投入生产的工具,正在改变企业、开发者和服务提供商处理多说话人音频的方式。凭借 GPU 加速、无缝集成以及跨语言的强大性能,它有望在 2025 年及以后成为实时说话人分类的事实上的标准。
对于专注于对话分析、云基础设施或语音应用的人工智能管理人员、内容创作者和数字营销人员来说,Streaming Sortformer 是一个不容错过的评估平台。它兼具速度、准确性和易于部署的特点,使其成为构建下一代语音产品的理想之选。
总结
NVIDIA 的 Streaming Sortformer 可为最多四位参与者提供即时的 GPU 加速说话人分类功能,并在英语和普通话方面均取得了显著成效。其新颖的架构和开放的可访问性使其成为实时语音分析的基础技术,为会议、联络中心、AI 助理等领域带来了飞跃。
常见问题解答:NVIDIA Streaming Sortformer
Streaming Sortformer 如何实时处理多个发言者?
流式 Sortformer 将音频处理成小块、重叠的片段,并在每位发言者加入对话时分配一致的标签(例如,spk_0–spk_3)。它会维护一个轻量级的已检测到发言者的内存,无需等待完整录音即可实现即时的帧级分类。这为实时转录、联络中心和语音助手提供了流畅、低延迟的体验。
为获得最佳性能,推荐使用什么硬件和设置?
它专为 NVIDIA GPU 设计,旨在实现低延迟推理。典型设置使用 16 kHz 单声道音频输入,并通过 NVIDIA 的语音 AI 堆栈(例如 NeMo/Riva)或可用的预训练模型进行集成。对于生产工作负载,请配置最新的 NVIDIA GPU,并确保音频缓冲有利于流式传输(例如,20-40 毫秒的帧,略有重叠)。
它是否支持英语以外的语言?可以追踪多少位说话者?
当前版本以英语为目标,并在普通话方面取得了验证,并可实时标记两到四位说话者。虽然它可以在一定程度上推广到其他语言,但准确率取决于声学条件和训练覆盖范围。对于同时说话者超过四人的场景,请考虑根据模型变体的演变对会话进行分段或评估管道调整。
参考资料:
https://huggingface.co/nvidia/diar_streaming_sortformer_4spk-v2
https://developer.nvidia.com/blog/identify-speakers-in-meetings-calls-and-voice-apps-in-real-time-with-nvidia-streaming-sortformer/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/60967.html