
Nous Research发布了Hermes 4,这是一个开放权重模型系列(基于 Llama 3.1 检查点,参数大小分别为 14B、70B 和 405B),通过纯粹的后训练技术实现了前沿级别的性能。Hermes 4 引入了混合推理——当复杂问题需要更深入的思考时,模型可通过 <think>...</think> 标签在标准响应与显式推理间切换。
Hermes 4的重大意义在于:它在保持完全透明度和中立对齐理念的同时,实现了开放权重模型领域的顶尖性能,证明了仅通过开源方法即可培育出复杂的推理能力。
DataForge:基于图形的合成数据生成
DataForge是 Hermes 4 核心结构背后的主要组件。那么,DataForge是什么呢?DataForge是一个革命性的基于图的合成数据生成系统,它彻底改变了训练数据的创建方式。与传统的数据管理方法不同,DataForge 通过有向无环图 (DAG)进行操作,其中每个节点都实现了一个PDDL(规划域定义语言)操作接口。
每个节点指定先决条件、后置条件和转换,从而促进复杂数据管道的自动创建。通过使用来自 DCLM 和 FineWeb 的预训练种子数据,系统可以将维基百科文章转换为说唱歌曲,然后基于该转换生成指令-答案对。
这种方法生成了大约500 万个样本,总计 190 亿个标记,其中推理样本有意包含大量标记,平均比非推理样本多 5 倍的标记,以适应长达 16,000 个标记的思考痕迹。


前所未有的拒绝采样规模
Hermes 4 使用Nous Research 的开源强化学习环境Atropos ,在大约1,000 个不同的特定任务验证器中实施拒绝采样。这个庞大的验证基础设施可以筛选出跨领域的高质量推理轨迹。
关键验证环境包括答案格式训练(奖励 150 多种输出格式的正确格式)、指令遵循(使用具有复杂约束的 RLVR-IFEval 任务)、模式遵守(使用 Pydantic 模型生成 JSON)以及代理行为的工具使用训练。
拒绝采样过程创建了一个庞大的已验证推理轨迹库,其中包含指向同一已验证结果的多条独特解决方案路径。这种方法确保模型学习到稳健的推理模式,而不是记忆特定的解决方案模板。
长度控制:解决过长的生成问题
Hermes 4 最具创新性的贡献之一是解决了过长推理问题——推理模型生成过长的思维链而无法终止。研究团队发现,在推理模式下,他们的 14B 模型在 LiveCodeBench 上60% 的时间达到了最大上下文长度。
他们超级有效的解决方案涉及第二个监督微调阶段教学模型,以便在恰好30,000 个标记时停止推理:
- 从当前策略生成推理轨迹
- 每次插入
</think>代币数量恰好为 30,000 个 - 仅针对终止决策进行训练,而不是推理链
- 仅对
</think>和<eos>标记应用梯度更新
该方法取得了显著成果:在 AIME’24 上,过长代码生成减少了 78.4% ,在 AIME’25 上减少了 65.3%,在 LiveCodeBench 上减少了79.8%,而相对准确率成本仅为 4.7% 至 12.7%。通过将学习信号完全集中在终止决策上,该方法避免了模型崩溃的风险,同时教会了有效的“计数行为”。
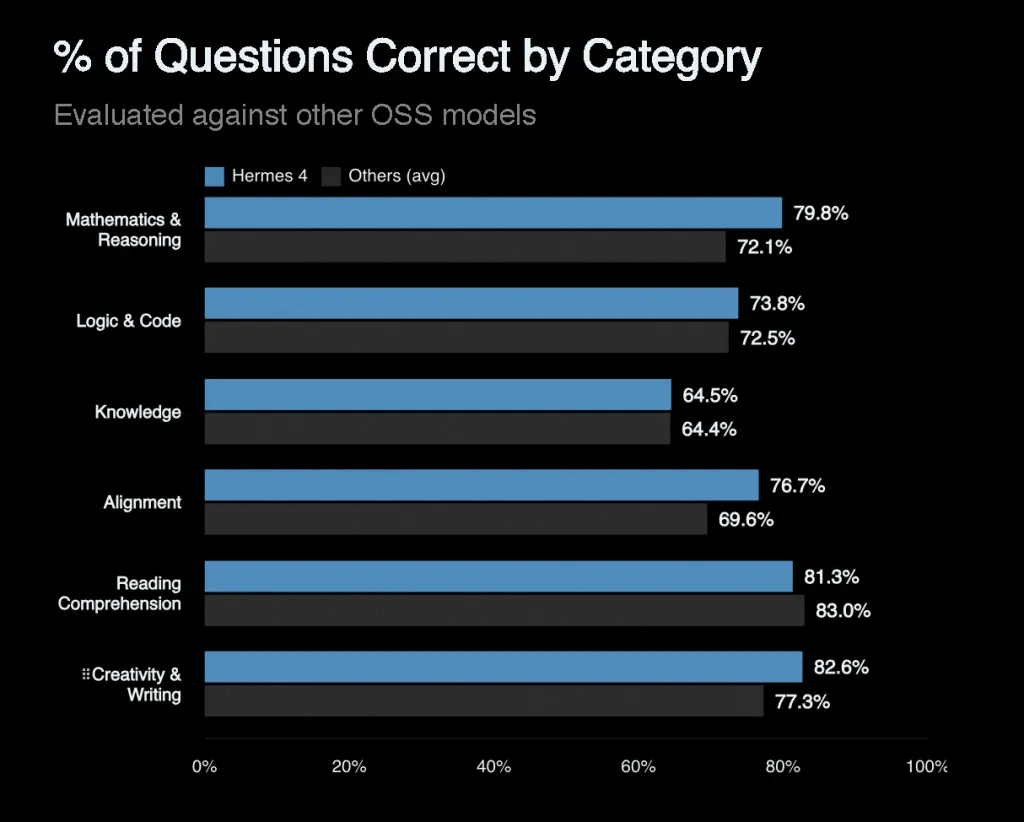
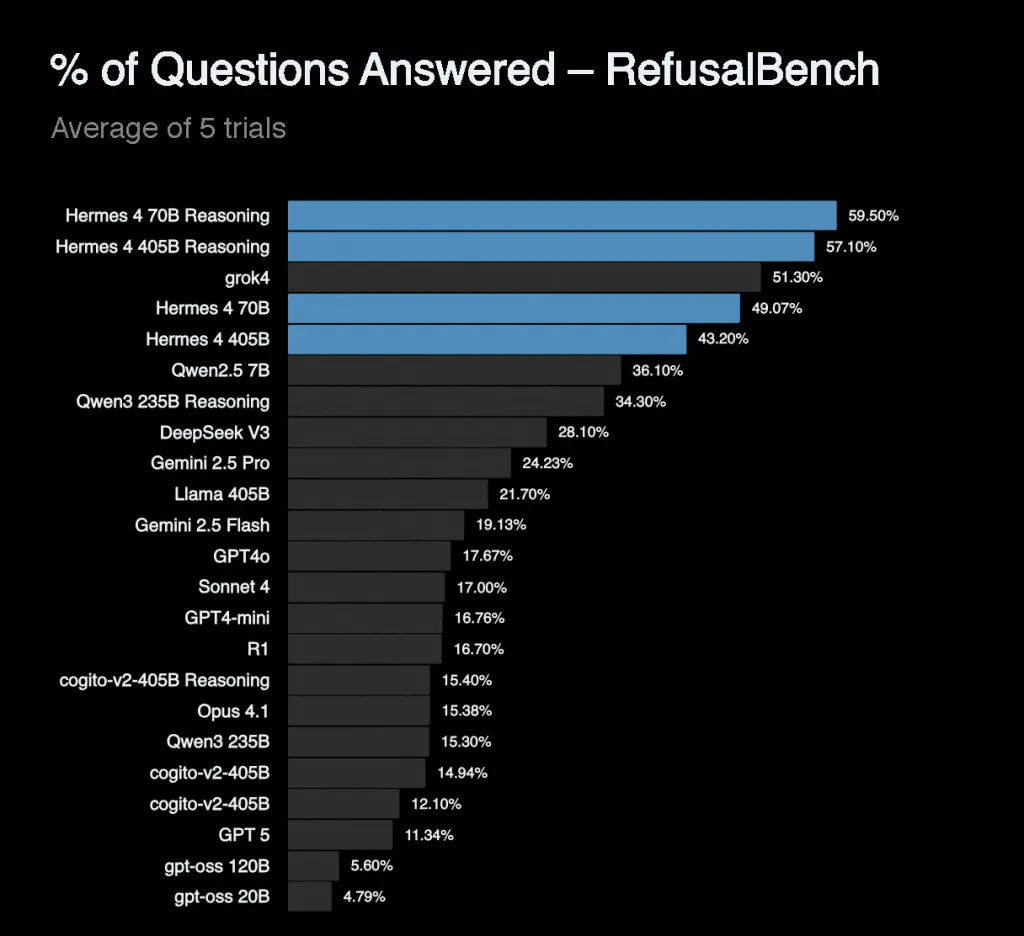
基准性能和中性一致性
Hermes 4 在开放权重模型中展现了最佳性能。405B 模型在 MATH-500(推理模式)上达到了96.3% ,在 AIME’24 上达到了81.9% ,在 AIME’25 上达到了 78.1% ,在 GPQA Diamond 上达到了70.5%,在 LiveCodeBench 上达到了61.3% 。
尤其值得注意的是它在 RefusalBench上的表现,其推理模式准确率高达57.1%,是所有受测模型中的最高分,显著优于 GPT-4o(17.67%)和 Claude Sonnet 4(17%)。这表明该模型在保持适当界限的同时,愿意探讨有争议的话题,这也体现了 Nous Research 的中立立场理念。
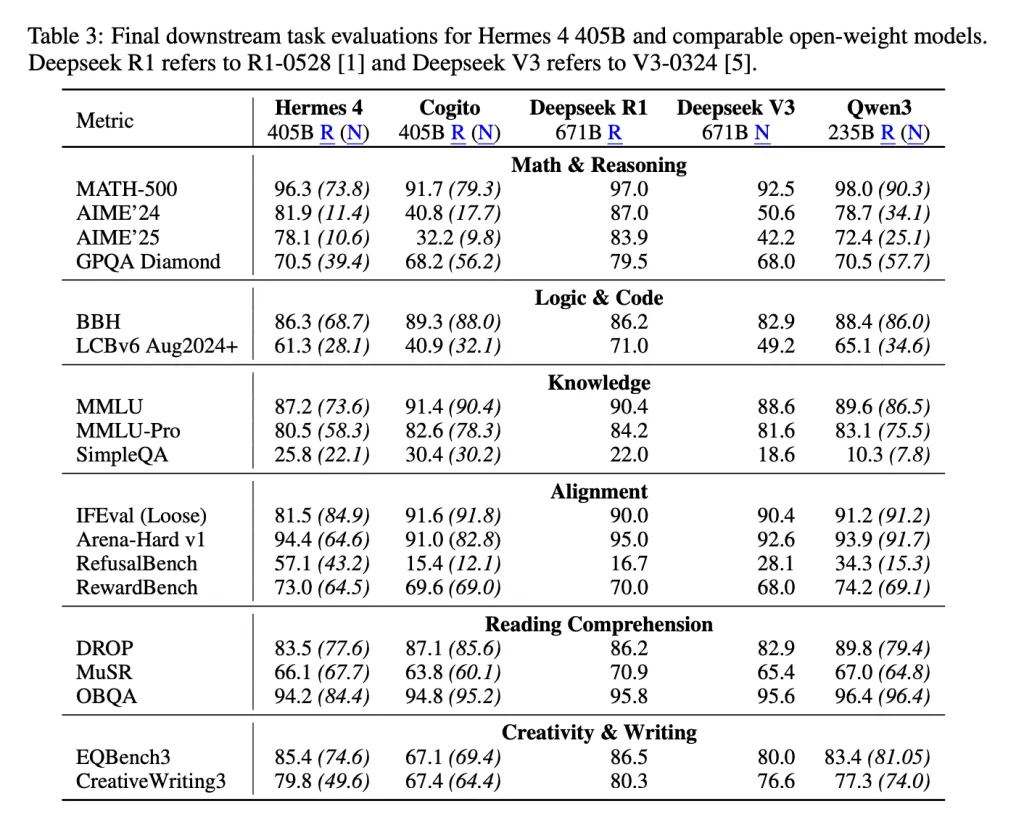
技术架构与训练
Hermes 4 的训练利用了192 块 NVIDIA B200 GPU上改进的TorchTitan。该系统通过高效的打包(实现 >99.9% 的批量效率)、弹性注意力机制和复杂的损失掩蔽机制来处理高度异构的样本长度分布,其中只有辅助角色 token 会导致交叉熵损失。
训练遵循余弦学习率计划,其中预热步骤 300 个,总步骤 9,000 个,上下文标记长度为 16,384 个,全局批量大小为 384 个样本,结合了数据并行、张量并行和完全分片数据并行。
总结
Hermes 4 标志着开源人工智能开发的重大进步,证明了前沿水平的推理能力可以通过透明、可重复的方法实现,而无需依赖专有训练数据或封闭的开发流程。通过结合创新的基于图的合成数据生成、大规模拒绝采样和精简的长度控制机制,Nous Research 创建的模型不仅性能媲美领先的专有系统,而且还保持了中立的一致性和可操控性,使其成为真正有用的工具,而非限制性的助手。
参考资料:
https://arxiv.org/abs/2508.18255
https://hermes4.nousresearch.com/
https://huggingface.co/collections/NousResearch/hermes-4-collection-68a731bfd452e20816725728
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/61144.html