
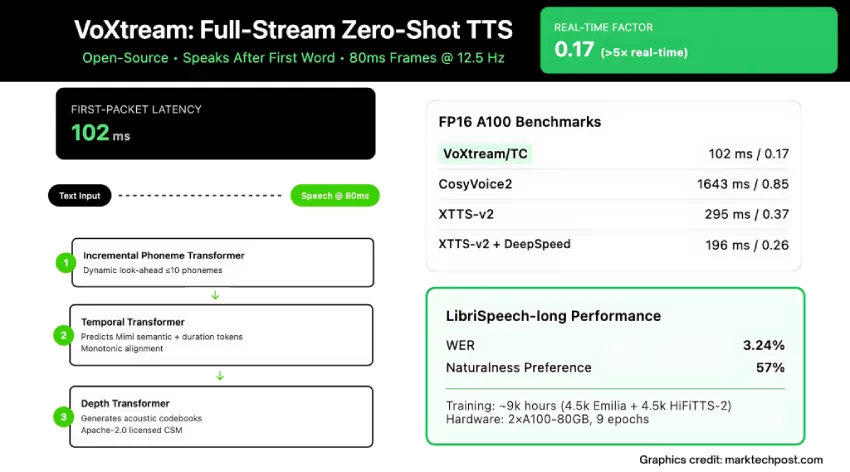
实时语音代理、现场配音和同声传译都因千分之一秒的延迟而受阻。大多数“流式”文本转语音(TTS)系统仍需等待整段文本处理完毕才开始发声,导致听者在语音启动前会听到短暂的停顿。由KTH 皇家理工学院语音、音乐与听觉团队推出的VoXtream技术直击痛点:它在首个单词后即刻发声,以 80 毫秒为帧输出音频,并在现代 GPU(采用PyTorch编译)上实现102毫秒的首包延迟(FPL)。
何谓“全流式”TTS?它与“输出流式”有何区别?
输出流式系统虽分段解码语音,仍需预先获取完整输入文本,导致计时延迟。全流系统则实时处理接收到的文本(从大型语言模型逐词获取),并同步输出音频。VoXtream采用后者方案:它接收词流并持续生成音频帧,在保持低帧计算量的同时消除了输入端缓冲。该架构明确以首个词的起始点为目标,而非仅追求稳态吞吐量。
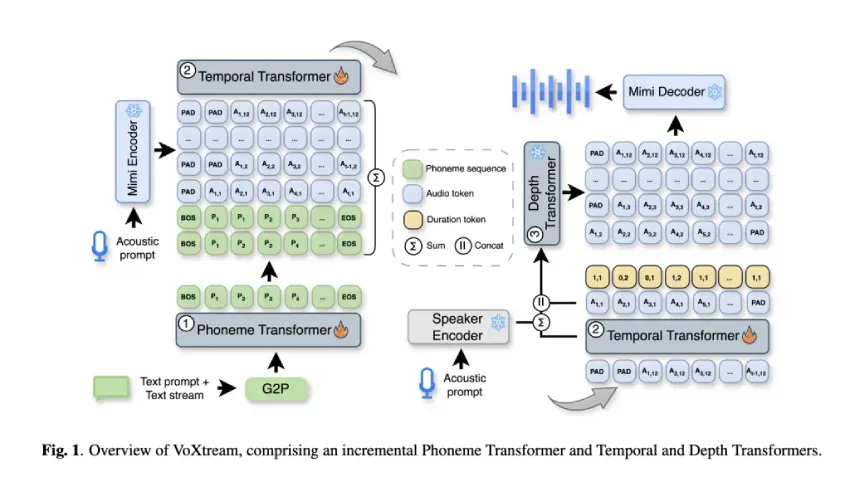

VoXtream 如何在不等待后续词汇的情况下开始说话?
核心技巧在于增量式音素转换器(PT)内部的动态音素前瞻机制。PT 最多可预览 10 个音素以稳定韵律,但无需等待完整上下文。生成过程可在首个词汇进入缓冲区后立即启动。这种设计规避了固定前瞻窗口带来的起始延迟。
VoXtream 底层模型架构是什么?
VoXtream 采用单一全自回归(AR)管道,包含三个变换器:
- 音素转换器 (PT):仅解码器,增量式;动态前瞻≤10 个音素;通过 g2pE 在单词级别进行音素化。
- 时间变换器 (TT):基于Mimi编解码器语义标记和时长标记的 AR 预测器,该标记编码了单调的音素到音频对齐(“停留/离开”和每帧 {1, 2} 个音素)。Mimi 以12.5 Hz的频率运行(→ 80 毫秒帧)。
- 深度变换器 (DT):用于剩余 Mimi声学码本的 AR 生成器,以 TT 输出和ReDimNet扬声器嵌入为条件,实现零样本语音提示。Mimi 解码器逐帧重建波形,实现连续发射。
Mimi 的流编解码器设计和双流标记化有据可查;VoXtream 使用其第一个代码本作为“语义”上下文,其余部分用于高保真重建。
实际运行中它真的很快吗?还是仅限于“纸面速度”?
该存储库包含一个基准脚本,用于测量FPL和实时因子 (RTF)。在A100上,研究团队报告未编译时RTF 为 171 ms / 1.00 ,编译时RTF 为 102 ms / 0.17 ;在RTX 3090上,未编译时RTF 为 205 ms / 1.19 ,编译后RTF 为 123 ms / 0.19。
与当今主流流式传输基准相比如何?
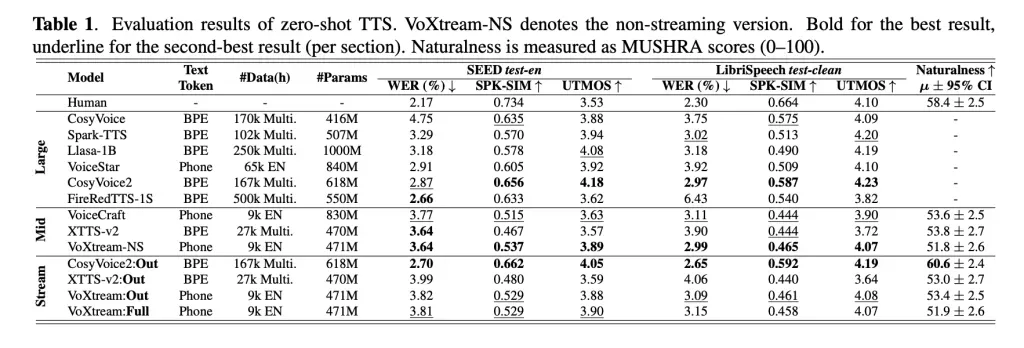
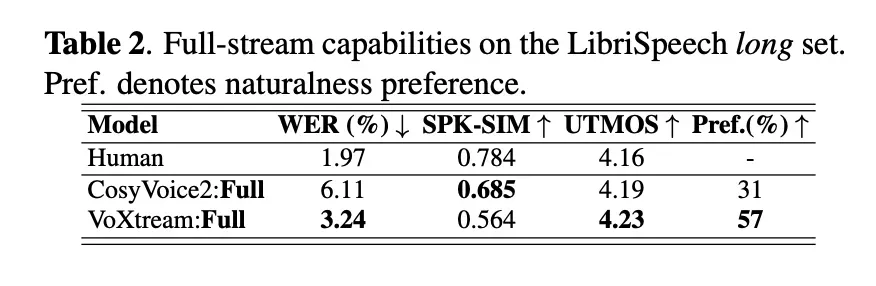
研究团队评估了短格式输出流和全流场景。在LibriSpeech-long全流(文本逐字到达)中,VoXtream 的字错误率 (WER) (3.24%) 低于 CosyVoice2 (6.11%),并且在听众研究中,VoXtream 的自然度显著优于CosyVoice2 ( p ≤ 5e-10 ),而 CosyVoice2 在说话人相似度方面得分更高,这与其流匹配解码器的结果一致。在运行时,VoXtream 在所比较的公开流式系统中拥有最低的 FPL,并且编译后运行速度比实时速度快 5 倍以上(RTF ≈ 0.17)。
为何这种 AR 设计能在起始阶段胜过扩散/流堆栈?
扩散/流语音编码器通常分块生成音频,因此即使文本-音频交织机制设计精妙,编码器仍会对首个数据包延迟设置下限。VoXtream 保持每个阶段的 AR 与帧同步——PT→TT→DT→Mimi解码器——因此首个 80 毫秒数据包仅需通过堆栈一次即可输出,而非经过多步采样器处理。本文开篇回顾了先前的交错式与分块式方案,并阐释了 IST-LM 和 CosyVoice2 中采用的 NAR 流匹配解码器如何在离线质量优异的情况下阻碍低 FPL 实现。
VoXtream 在一个约 9000 小时的中型语料库上进行训练:其中约 4.5 千个 Emilia 和 4.5 千个 HiFiTTS-2(22 kHz 子集)。团队通过日记法删除多说话人片段,使用 ASR 过滤转录本,并应用NISQA去除低质量音频。所有内容均重采样至24 kHz,数据集卡片详细列出了预处理流程和对齐工件(Mimi 标记、MFA 对齐、时长标签和说话人模板)。
除精心挑选的片段外,核心质量指标是否依然保持稳定?
表 1(零样本 TTS)显示,VoXtream 在SEED-TTS test-en和LibriSpeech test-clean的WER、UTMOS(MOS 预测器)和说话人相似度方面均具有竞争力;研究团队还进行了一项消融实验:添加CSM 深度变换器和说话人编码器后,相似度显著提升,且与剥离基线相比,WER 损失不显著。主观研究采用了类似 MUSHRA 的协议和针对全流生成量身定制的第二阶段偏好测试。
这项技术在 TTS 领域处于什么位置?
根据研究论文,VoXtream 被定位于近期交错式 AR + NAR 声码器方法和LM 编解码器堆栈之中。其核心贡献并非新的编解码器或庞大的模型,而是一种以延迟为中心的 AR 方案,加上一个可保留输入端流的时长标记对齐机制。如果您构建实时代理,那么重要的权衡显而易见:说话者相似度略有下降,而FPL比全流条件下的分块 NAR 声码器低几个数量级。
参考资料:
https://arxiv.org/pdf/2509.15969
https://huggingface.co/herimor/voxtream
https://github.com/herimor/voxtream
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/61811.html