
隐写术(Steganography)作为一种将秘密信息隐藏于非机密载体(如图片、音频)的技术,在保密通信、数字水印和版权保护领域具有重要价值。目前“音频隐于图像”这一交叉领域的研究相对匮乏,现有方案多给予深度神经网络,存在训练成本高、可能达到性能瓶颈等问题。
印度马尼帕尔高等教育学院的研究团队在IEEE Access上发表了一项新研究,提出了一种名为 “ASA”(Audio-in-Image Steganography using Analysis and Resynthesis Sound Spectrograph)的新型音频隐写技术。


该方法不依赖深度学习模型,结合声学信号处理与图像嵌入技术,通过将音频转换为高度可塑的声谱图,并将其无损嵌入高分辨率彩色图像中,实现了高效、安全且高保真的音频隐藏与重建。
ASA 框架的整体工作流程
ASA 框架的整体工作流程分为三个阶段,其核心流程如下图所示:
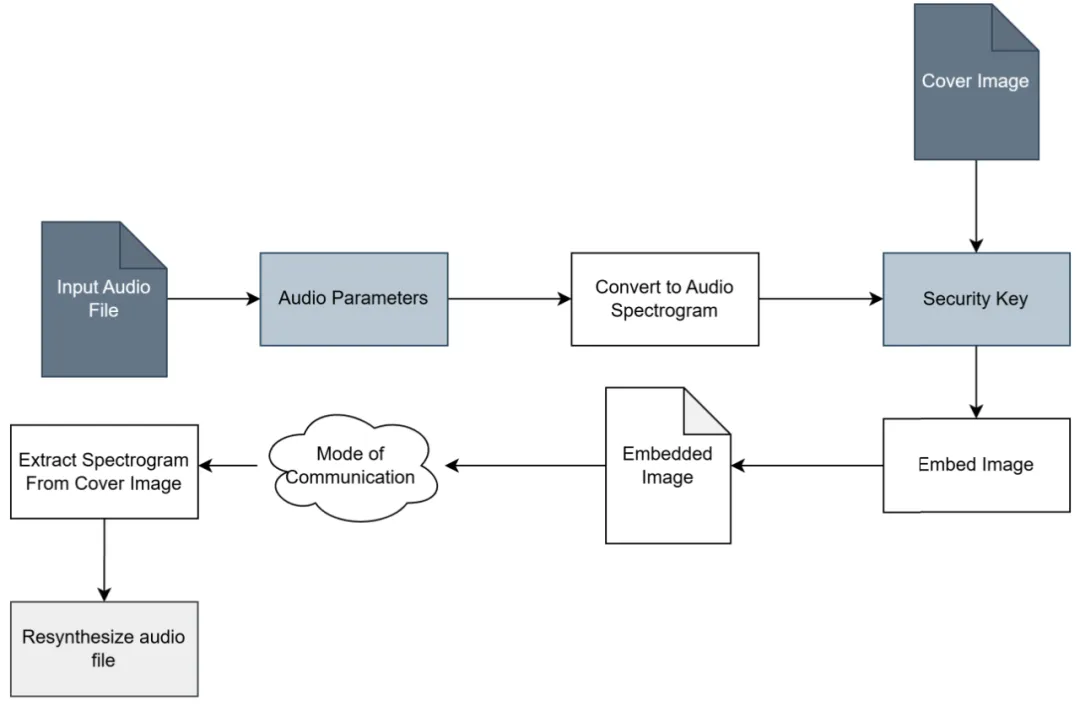
此图为 ASA 框架的整体流程示意图。它展示了从原始音频和封面图像输入,经过“分析 → 隐写嵌入 → 再合成”三个阶段,最终生成含密图像(stego-image)并可在接收端重建音频的完整工作流。图中用深灰色表示输入文件,浅灰色表示安全参数,清晰体现了系统的模块化结构和数据流向。
第一阶段:分析
系统首先接收一段原始音频信号,并利用 ARSS(Analysis and Resynthesis Sound Spectrograph)工具将其转换为一张单通道灰度图像——即声谱图。与传统基于短时傅里叶变换(STFT)的方法不同,ARSS 采用滤波器组 + 包络检测 + 希尔伯特变换的模拟式分析路径,生成的声谱图在时频域上具有更强的“可塑性”,对谱图的修改能更直观地对应音频的物理属性。
ARSS 的转换过程依赖一组关键参数,包括最小/最大频率、每倍频程的频带数、每秒像素数、采样率以及亮度等。这些参数是后续能否正确重建音频的关键,也构成了系统的基础安全要素。
论文通过香农熵计算指出,该参数空间的熵值高达26.86比特,意味着攻击者需进行约226.86次尝试才能猜中正确参数组合。
第二阶段:嵌入
在获得灰度声谱图后,系统将其嵌入到一张高分辨率的彩色封面图像(通常为 PNG 格式,以支持无损存储)中。
ASA 的创新之处在于:将单通道的声谱图信息分散编码至 RGB 三个颜色通道。
具体采用一种简单的加法技术和线性编码函数,将处理后的声谱图数据添加到封面图像的各个颜色通道中。这种多通道嵌入方式提高了数据容量和隐蔽性。该框架设计为模块化,允许在嵌入阶段集成其他加密方法。
根据封面图像的尺寸,系统还可调整声谱图。例如,当使用高度为1368像素的图像时,可容纳约两个高度为555像素的声谱图分区,从而实现单图嵌入多段音频。
第三阶段:提取与重建
接收端从隐写图像的RGB三通道中逆向提取并合并出隐藏的声谱图,随后结合共享的ARSS参数,通过ARSS的再合成模块重建出音频信号。整个流程注重维持高保真度的声音重建。
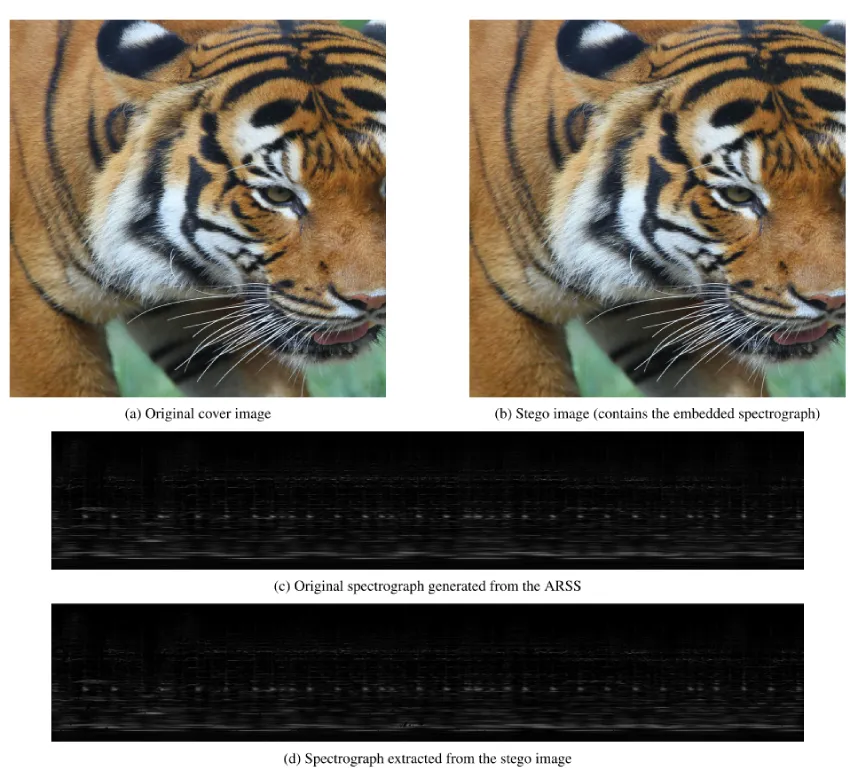
在性能方面,ASA表现出色。隐写图像(Stego-image)相对于原始封面图像的平均 PSNR 为 42.54 dB,重建出的声谱图相对于原始声谱图的平均 PSNR 为 45.02 dB。与U-Net、V-Net等图像隐写方法相比,ASA在图像隐藏质量上更具优势。
在存储效率方面,ASA优势显著。实验表明,嵌入声谱图后,图像文件大小平均仅比原始封面图像增加约1.292%。研究者定义了两种尺寸比率(SR1 和 SR2)来衡量效率,如下图所示,在音频时长不超过30秒时,SR1和SR2稳定在3.5–4之间,意味着实现了70%–75%的体积压缩。
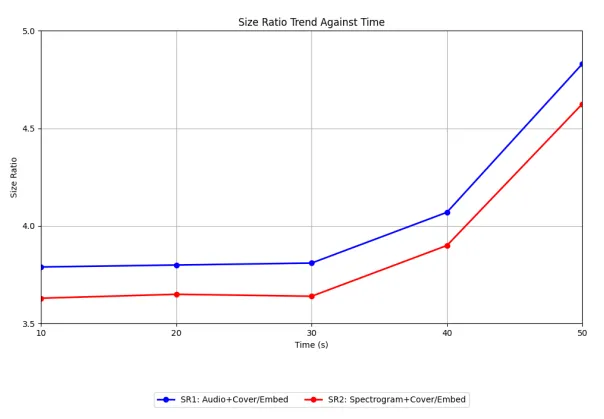
该图用于评估AASA方法的空间效率。其中:SR1=(音频文件大小+封面图像大小)/嵌入后图像大小;SR2=(声谱图大小+封面图像大小)/嵌入后图像大小。图中蓝线(SR1)和红线(SR2)在 0–30 秒区间保持平稳(约 3.5–4),表明此时嵌入效率高、体积压缩显著(达 70–75%);超过 30 秒后曲线上升,说明封面图像开始饱和,无法高效容纳更长音频的声谱图。
此外,回归分析表明,嵌入导致的体积变化与原始音频和封面图像的大小无显著相关性,证明ASA的空间效率主要由其内部机制决定。
总结
ASA框架将 ARSS 技术应用于隐写术,提供了一种简洁、非基于深度学习、且具备高存储效率的音频隐写解决方案。它通过在 RGB 三通道中嵌入可塑性强的声谱图,在保持高图像质量的同时,实现了音频的有效隐藏与重建。
ASA 技术的优势在于摆脱了对深度学习模型的依赖,部署门槛低,仅通过 Python 及相关轻量库就能实现,同时兼顾了一定的安全性和存储效率。
但它也存在明显的不足:音频重建质量受 ARSS 工具本身的限制,高频细节容易丢失;目前仅支持 PNG 格式载体,对 JPEG 等有损压缩图像的兼容性不佳;面对复杂的攻击手段时,现有的安全机制还需进一步强化。
论文信息:A. A. Krishnan, Y. Ramesh, U. Urs, and M. Arakeri, “Audio-in-Image Steganography Using Analysis and Resynthesis Sound Spectrograph,” IEEE Access, vol. 13, pp. 75184–75192, 2025, doi: 10.1109/ACCESS.2025.3563781.
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。