
在智能手机上运行强大的 AI 不仅仅是硬件问题,更是模型架构问题。大多数最先进的视觉编码器体积庞大,当为了适应边缘设备而将其精简时,它们会失去原本使其发挥作用的功能。更糟糕的是,专用模型往往擅长某一类任务,例如图像分类或场景分割,但一旦超出其能力范围,它们就会束手无策。
Meta 公司的 AI 研究团队现在提出了一条不同的道路。他们推出了高效通用感知编码器(EUPE):一种紧凑型视觉编码器,可以同时处理各种视觉任务,而无需占用大量空间。
核心问题:专家型与通才型
要理解 EUPE 为何重要,我们需要先了解视觉编码器的工作原理,以及为何专业化会成为问题。
视觉编码器是计算机视觉模型中将原始图像像素转换为紧凑表示形式(即一组特征向量)的组件,下游任务(如分类、分割或回答关于图像的问题)可以利用这些表示。不妨将其视为 AI 管道的“眼睛”。
现代基础视觉编码器经过特定目标的训练,这使其在特定领域具有优势。例如:
- CLIP和SigLIP 2使用文本-图像对进行训练。它们在图像理解和视觉语言建模方面表现出色,但在密集预测任务(需要空间精确的像素级特征)上的性能通常低于预期。
- DINOv2及其后续模型DINOv3是自监督模型,能够学习出色的结构和几何描述符,因此在语义分割和深度估计等密集预测任务中表现出色。但它们缺乏令人满意的视觉语言能力。
- SAM(Segment Anything Model,即“任意分割模型”)通过在大规模分割数据集上进行训练,实现了令人印象深刻的零样本分割,但在视觉语言任务上再次表现不佳。
对于需要同时处理所有这些任务类型的边缘设备(例如智能手机或AR头显),典型的解决方案是同时部署多个编码器。但这很快就会导致计算资源消耗过大。另一种选择是接受单个编码器在多个领域性能不佳的现实。
以往的尝试:聚合式方法为何在高效骨干网络构建上未能奏效
研究人员曾尝试通过一种名为“聚合式多教师蒸馏”的方法体系,将多个专业编码器的优势结合起来。其基本思路是:训练一个学生编码器,使其同时模仿多个教师模型,而每个教师模型都是某个领域的专家。
AM-RADIO 及其后续版本 RADIOv2.5 或许是该方法最著名的代表。它们证明聚合式蒸馏在大型编码器(参数超过3亿的模型)上表现良好。但 EUPE 研究揭示了一个明显的局限:当将同样的方案应用于高效骨干网络时,结果会大幅退化。作为 ViT-B 规模变体的 RADIOv2.5-B,在密集预测和 VLM 任务上与领域专家模型相比存在显著差距。
另一种聚合式方法 DUNE 通过异构协同蒸馏融合了 2D 视觉和 3D 感知教师模型,但在高效骨干网络规模下同样表现欠佳。
研究团队认为,根本原因在于容量。高效的编码器根本没有足够的表征容量,无法直接吸收来自多个专业教师的各种特征表征,并将它们统一成一个通用表征。试图一步完成这项工作,最终得到的模型各方面表现都平庸。


EUPE的答案:先扩大规模,再缩小规模
EUPE 背后的关键见解是一个名为“先扩大规模,再缩小规模”的原则。
EUPE 并非直接将多位领域专家的知识提炼成一个小型学生的知识,而是引入了一种中间模型:一个容量巨大的代理教师,能够整合所有领域专家的知识。然后,这个代理教师通过知识提炼,将其整合的通用知识传递给高效的学生。
完整的流程分为三个阶段:
第一阶段:多教师模型提炼为代理模型。多个大型基础编码器同时作为教师模型,处理原始分辨率的无标签图像。每个教师模型输出一个类别标记和一组图像块标记。代理模型(一个使用 4 个注册标记训练的 19 亿参数模型)被训练成同时模拟所有教师模型。选定的教师模型如下:
- PEcore-G(19亿参数)被选为零样本图像分类和检索领域的专家模型。
- 研究团队发现, PElang-G(17亿个参数)对于视觉语言建模,尤其是OCR性能至关重要。
- DNOv3-H+(8.4亿个参数)被选为密集预测的领域专家
为了稳定训练,教师输出通过减去每个坐标的均值并除以标准差进行归一化。该标准差在训练开始前经过 500 次迭代计算一次,之后保持不变。这种方法比 RADIOv2.5 中使用的复杂 PHI-S 归一化方法更为简单,并且避免了动态计算归一化统计信息所带来的跨 GPU 内存开销。
第二阶段:固定分辨率蒸馏到高效学生模型。代理模型现在作为单一的通用教师模型,目标高效编码器以 256×256 的固定分辨率进行训练。这种固定分辨率提高了训练的计算效率,允许更长的学习周期:390,000 次迭代,批大小为 8,192,采用余弦学习率,基础学习率为 2e-5,权重衰减为 1e-4。应用标准数据增强方法:随机裁剪、水平翻转、颜色抖动、高斯模糊和随机曝光。蒸馏损失函数中,类别标记损失使用余弦相似度,而图像块标记损失结合了余弦相似度(权重 α=0.9)和平滑 L1 损失(权重 β=0.1)。将适配器头模块(两层多层感知器)添加到学生模型,以匹配每个教师模型的特征维度。如果学生和教师补丁标记的空间尺寸不同,则应用 2D 双三次插值来对齐它们。
第三阶段:多分辨率微调。从第二阶段的检查点开始,学生模型将进行一个较短的微调阶段,该阶段使用一个包含三个尺度(256、384 和 512)的图像金字塔。学生模型和代理教师在每次迭代中独立且随机地选择一个尺度——因此它们可以处理同一幅图像的不同分辨率。这迫使学生模型学习能够泛化到不同空间粒度的表征,从而适应下游在不同分辨率下运行的任务。该阶段运行 10 万次迭代,批大小为 4096,基础学习率为 1e-5。之所以有意缩短迭代时间,是因为多分辨率训练的计算成本很高——第三阶段的一次迭代所需时间大约是第二阶段的两倍。
训练数据。所有三个阶段均使用相同的DINOv3数据集LVD-1689M,该数据集均衡地涵盖了来自网络的视觉概念以及包括ImageNet-1k在内的高质量公共数据集。ImageNet-1k的采样概率为10%,其余90%来自LVD-1689M。在消融实验中,尽管MetaCLIP(25亿张图像)的图像数量比LVD-1689M多约8亿张,但在几乎所有基准测试中,使用LVD-1689M进行训练的性能始终优于使用MetaCLIP(25亿张图像)进行训练的性能,这表明LVD的数据质量更高。
一项重要的负面结果:并非所有“教师”都能良好配合
其中一项更具实际应用价值的发现涉及“教师”的选择。直观来看,增加更多优秀的“教师”应该会有帮助。但研究团队发现,将 SigLIP2-G 与 PEcore-G 和 DINOv3-H+ 结合使用,会显著降低 OCR 性能。在代理模型层面,TextVQA 得分从 56.2 降至 53.2;在 ViT-B 学生模型层面,得分从 48.6 降至 44.8。研究团队的假设是:教师集同时包含两个 CLIP 风格的模型(PEcore-G和SigLIP2-G)会导致特征不兼容。PElang-G 作为通过与语言模型对齐从 PEcore-G 衍生出的语言专用模型,被证明是更理想的补充方案——它既提升了 OCR 和通用视觉语言模型(VLM)的性能,又未牺牲图像理解或密集预测能力。
数字告诉我们什么
消融实验验证了三阶段设计。直接从多个教师提取高效学生的学习成果(“仅第二阶段”)会导致 VLM 性能不佳,尤其是在 OCR 类型的任务上,且密集预测能力也较差。添加第一阶段(代理模型)可显著改善 VLM 任务:TextVQA 从 46.8 提升至 48.3,Realworld 从 53.5 提升至 55.1,但在密集任务上仍然存在不足。第一阶段 + 第三阶段(跳过第二阶段)可获得最佳的密集预测结果(SPair:53.3,NYUv2:0.388),但会留下 VLM 方面的不足,且运行完整课程的成本较高。完整的三阶段流程实现了最佳的整体平衡。
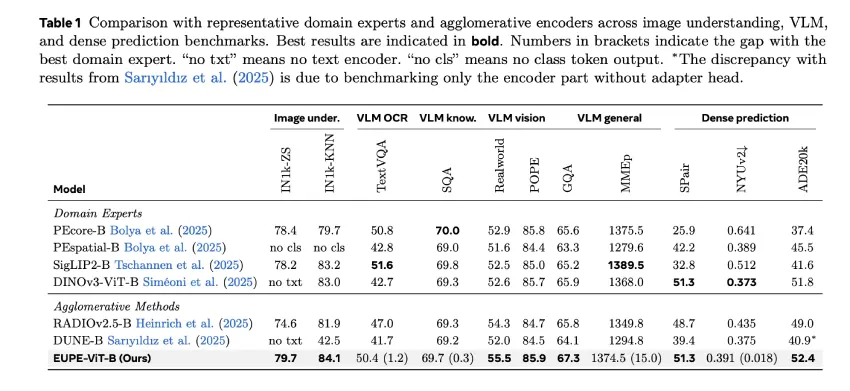
在主要的 ViT-B 基准测试中,EUPE-ViT-B 始终表现突出:
- 图像理解: EUPE 在 IN1k-KNN 数据集上取得了 84.1 的成绩,优于 PEcore-B (79.7)、SigLIP2-B (83.2) 和 DINOv3-ViT-B (83.0)。在 IN1k-ZS (零样本) 数据集上,其得分为 79.7,优于 PEcore-B (78.4) 和 SigLIP2-B (78.2)。
- 密集预测: EUPE 在 ADE20k 数据集上取得了 52.4 mIoU 的成绩,优于密集预测专家 DINOv3-ViT-B(51.8)。在 SPair-71k 语义对应测试中,其得分为 51.3,与 DINOv3-ViT-B 相当。
- 视觉语言建模: EUPE 在 RealworldQA(55.5 对 52.9 和 52.5)和 GQA(67.3 对 65.6 和 65.2)上的表现优于 PEcore-B 和 SigLIP2-B,同时在 TextVQA、SQA 和 POPE 上保持竞争力。
- 与凝聚方法相比: EUPE 在所有 VLM 任务和大多数密集预测任务上都显著优于 RADIOv2.5-B 和 DUNE-B。
这些功能实际看起来是什么样的
该研究还包括使用主成分分析(PCA)将图像块投影到RGB空间进行定性特征可视化——这项技术可以揭示编码器学习到的空间和语义结构。结果令人深思:
- PEcore-B 和 SigLIP2-B 补丁标记包含语义信息,但在空间上不一致,导致表示存在噪声。
- DINOv3-ViT-B 具有高度清晰、语义连贯的特征,但缺乏细粒度的区分(在最后一行示例中,食物和盘子最终具有相似的表示)。
- RADIOv2.5-B 特征过于敏感,破坏了语义连贯性。例如,黑色的狗毛在视觉上与背景融为一体。
- EUPE-ViT-B 同时结合了语义连贯性、精细粒度、复杂空间结构和文本感知,一次性捕捉到所有领域专家的最佳品质。
全系列Edge Ready机型
EUPE是一个完整的系列,涵盖两种架构类型:
- ViT 系列:ViT-T(6M 参数)、ViT-S(21M)、ViT-B(86M)
- ConvNeXt 系列:ConvNeXt-Tiny (29M)、ConvNeXt-Small (50M)、ConvNeXt-Base (89M)
所有模型参数量均低于 1 亿。推理延迟是在 iPhone 15 Pro CPU 上使用 ExecuTorch 导出的模型测量的。在 256×256 分辨率下:ViT-T 运行时间为 6.8 毫秒,ViT-S 为 17.1 毫秒,ViT-B 为 55.2 毫秒。ConvNeXt 变体的浮点运算次数 (FLOPs) 低于同等规模的 ViT 模型,但并不一定能实现更低的 CPU 延迟——因为与 ViT 模型中使用的高度优化的矩阵乘法 (GEMM) 运算相比,卷积运算在 CPU 架构上的效率通常较低。
对于 ConvNeXt 系列,EUPE 在 Tiny、Small 和 Base 变体的密集预测方面始终优于相同大小的 DINOv3-ConvNeXt 系列,同时还解锁了更好的 VLM 功能,特别是对于 OCR 和以视觉为中心的任务,而 DINOv3-ConvNeXt 完全缺乏这种功能。
要点总结
- 一个编码器,统领一切。EUPE是一款紧凑型视觉编码器(参数少于 1 亿),在图像理解、密集预测和视觉语言建模等领域,其性能可媲美甚至超越专业领域专家模型,而这些任务以往需要单独的专用编码器才能完成。
- 先扩大规模,再缩小规模。其核心创新在于三阶段“代理教师”提炼流程:首先将多个大型专家模型的知识聚合到一个包含19亿个参数的代理模型中,然后从这个统一的代理模型提炼出一个高效的学生模型,而不是直接同时从多个代理模型提炼知识。
- 教师的选择是一个设计决策,而非既定事实。增加教师数量并非总能带来改善。将 SigLIP2-G 与 PEcore-G 同时使用会显著降低 OCR 性能。事实证明,PElang-G 才是合适的 VLM 补充。这一发现对任何构建多教师蒸馏流程的人都具有直接的实践意义。
- 专为边缘部署而打造。完整的 EUPE 系列涵盖六款型号,支持 ViT 和 ConvNeXt 架构。其中最小的 ViT-T 在 iPhone 15 Pro CPU 上运行仅需 6.8 毫秒。所有型号均可通过 ExecuTorch 导出,并可在 Hugging Face 上获取,可直接集成到设备端,而不仅仅是用于基准测试。
- 数据质量比数据数量更重要。在消融实验中,基于 LVD-1689M 数据集训练的模型在几乎所有基准测试中都优于基于 MetaCLIP 数据集训练的模型,尽管 MetaCLIP 数据集包含的图像数量比 LVD-1689M 多出约 8 亿张。这有力地提醒我们,更大的数据集并不一定意味着更好的模型。
参考资料
- 论文地址:https://arxiv.org/pdf/2603.22387
- 模型:https://huggingface.co/collections/facebook/eupe
- GitHub:https://github.com/facebookresearch/EUPE
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/65989.html