
NVIDIA 的 Nemotron Speech 团队发布了Nemotron 3.5 ASR。这是一个拥有 6 亿参数的流式自动语音识别 (ASR) 模型。单个检查点即可实时转录 40 种语言区域设置。标点符号和大小写均已原生支持。该模型以开放权重的形式发布在 Hugging Face 上,采用 OpenMDW-1.1 许可。其架构为缓存感知型 FastConformer-RNNT。
什么是 Nemotron 3.5 ASR
Nemotron 3.5 ASR 在 nvidia/nemotron-speech-streaming-en-0.6b 的基础上扩展了多种语言支持。它在基础模型中加入了基于提示的语言 ID 条件判断功能。这使得一个包含 6 亿个参数的检查点即可覆盖 40 种语言区域设置。无需针对每种语言单独构建模型或进行模型切换。
该模型针对两种工作负载。第一种是低延迟实时音频流传输。第二种是高吞吐量批量转录。输出结果是可直接用于生产环境的文本,大小写和标点符号均正确无误。无需单独的标点符号恢复步骤。
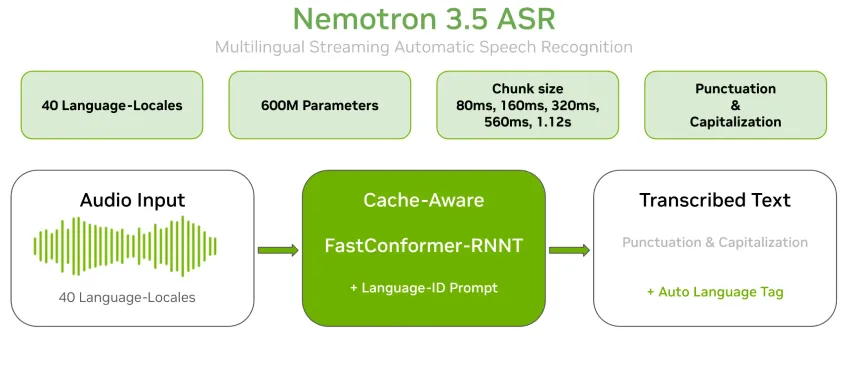

缓存感知型 FastConformer-RNNT 的工作原理
该模型由两部分组成。第一部分是一个24层的缓存感知型FastConformer编码器。FastConformer是Conformer架构的高效演进版本,它采用了线性可扩展的注意力机制。第二部分是一个RNNT(循环神经网络转换器)解码器。RNNT将音频流逐帧解码为文本。
“缓存感知”设计是提升效率的关键。缓冲流式传输会在每个步骤中重复处理重叠的音频窗口,这不仅重复了相同的工作,还增加了延迟。而该模型则缓存编码器的自注意力机制和卷积激活值,并在新音频到达时重用这些缓存状态。因此,每个音频帧都只被处理一次,不存在重叠。计算延迟和端到端延迟都得以降低,且不影响准确率。
延迟调节旋钮:att_context_size
有一个推理设置可以控制延迟与精度的权衡。这就是注意力上下文大小(att_context_size)。较小的上下文能更快生成文本,但能预见未来的音频较少;较大的上下文则能在更高的延迟下提高精度。
同一个检查点覆盖了整个范围。这些设置对应 80 毫秒、160 毫秒、320 毫秒、560 毫秒和 1.12 秒的片段时长。例如,[56,0] 设置对应 80 毫秒的超低延迟模式,而 [56,13] 设置则提供 1.12 秒的片段时长以实现最高精度。团队可在推理时选择工作点,无需重新训练。
语言检测与覆盖范围
这 40 种语言区域设置包括英语、西班牙语、德语和法语的各种变体。此外,还涵盖阿拉伯语、日语、韩语、普通话、印地语和泰语。此外,还包含其他几种欧洲和北欧语言。
语言条件设置有两种方式。将 target_lang 设置为已知的语言环境通常能获得最佳准确率。将 target_lang 设为 auto 则允许模型自行检测语言。在自动模式下,模型会在句末标点符号后输出语言标签。这样,一次部署即可转录混合语言的语音数据,无需单独的语言识别组件。
比较
| 产品 | 公司 | 使用权 | 原生流媒体 | 语言覆盖范围 | 报告的延迟 | 定价模式 |
|---|---|---|---|---|---|---|
| Nemotron 3.5 ASR | NVIDIA | 开放权重(OpenMDW-1.1),自托管;托管于 DeepInfra | 是,缓存感知的 FastConformer-RNNT | 40 个语言区域 | 80毫秒至1.12秒,可在推理阶段配置 | 免费自托管;通过主机商按使用量付费。 |
| Whisper large-v3 | OpenAI | 开源权重(MIT 许可证),可自行托管;API | 否,离线/批量 | 约99种语言 | 非流媒体原生支持 | 自托管免费;API 服务价格约为 0.006 美元/分钟(批量处理) |
| Nova-3 | Deepgram | 封闭式 API;本地部署/自托管(企业级) | 是,流式传输+批量处理 | 支持多种语言;2026年1月新增10种单语种语言 | 低延迟流媒体(据称低于300毫秒) | ~$0.0077/分钟(Nova-3 单语版,按需付费) |
| Universal-3 Pro Streaming | AssemblyAI | 封闭式 API(欧盟端点可用) | 是 | 6种语言:英语、西班牙语、法语、德语、意大利语、葡萄牙语 | 低于300毫秒(官方数据);第一次部分计时约750毫秒 | 按使用量计费(PAYG) |
| Scribe v2 Realtime | ElevenLabs | 封闭式 API | 是 | 支持90多种语言(ElevenLabs支持99种) | 约150毫秒(p50) | 每小时约 0.28 美元 |
| Ursa / streaming | Speechmatics | API + 本地部署 + 边缘计算 | 是,流式传输+批量处理 | 50多种语言,具备自动识别功能 | 超低延迟(定位) | 企业/使用情况 |
微调结果
由于权重是公开的,各团队可以针对特定语言、领域或口音进行微调。NVIDIA 发布了一个关于希腊语和保加利亚语的示例。该示例使用相同的 Cache-Aware FastConformer-RNNT 方法对基础检查点进行了微调。每个音频片段都带有 target_lang 标签,用于语言条件设置。训练数据来自公开语料库,包括 Granary、Common Voice 和 FLEURS。
结果以保留集 FLEURS 上的 WER 作为衡量标准,延迟设置为 80 毫秒。希腊语 WER 从 35 降至 24,相对改善了 32%。保加利亚语 WER 从 22 降至 15,相对改善了 31%。这些是在最低延迟流式传输模式下的原始 WER 百分比。NVIDIA 指出,在部署延迟下对保留集数据进行评估,能得出更真实的数值。
优势与注意事项
优势:
- 一个600M参数的检查点覆盖了40种语言环境,有效减少了部署规模。
- 支持缓存的流式处理机制仅需处理每帧一次,在H100上报告的缓冲并发数为17倍。
att_context_size参数可在推理时将延迟从80毫秒调整至1.12秒,且无需重新训练。- 内置标点符号、大小写识别及自动语言标注功能。
- 开放权重后,在希腊语和保加利亚语上经过微调,相对WER降低了31–32%。
注意事项:
- 该模型支持英语,但 NVIDIA 建议仅使用英语的用户使用其专用的英语模型。
- 80毫秒模式以牺牲一些精度为代价,换取最低的延迟。
- 日语和韩语都使用 CER,因此跨语言错误比较需要谨慎。
- 吞吐量数据是在 H100 上测量的,因此在其他 GPU 上的结果会有所不同。
- 支持 gRPC 流式传输的生产版 NIM 已经宣布,但尚未发布。
要点总结
- NVIDIA 的 Nemotron 3.5 ASR 是一个开放权重 (OpenMDW-1.1) 的 6 亿参数流式模型,可从一个检查点转录 40 种语言区域设置。
- 其缓存感知快速成型器-RNNT 设计对每个音频帧进行一次处理,据报道,其并发流速度是 H100 缓冲方法的 17 倍。
- 推理延迟可通过配置
att_context_size从 80 毫秒到 1.12 秒不等,无需重新训练。 - 在 80 毫秒设置下,对希腊语 (35→24) 和保加利亚语 (22→15) 进行短暂的微调,削减 FLEURS WER 32% 和 31%。
- 它可自托管且原生支持流媒体,这与封闭式 API(Deepgram、AssemblyAI、ElevenLabs)或离线 Whisper 不同。
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/67424.html