
本文提出了一种高分辨率的 3D 感知生成模型,该模型不仅能够实现面部形状和纹理的局部控制,还支持实时交互式编辑。模型框架由 multi-head StyleGAN2 特征生成器、神经体积渲染器和基于 2D CNN 的上采样器组成。为了区分不同的面部属性,将形状和纹理代码分别注入基于 StyleGAN 的特征生成器的浅层和深层。然后使用输出特征以有效的三平面表示构建形状(以面部语义编码)和纹理的空间对齐的 3D 体积。给定生成的 3D 体积,可以通过体积渲染和基于 2D CNN 的上采样器以令人满意的视图一致性和照片真实性来渲染自由视图肖像。
来源:arXiv
论文链接:https://arxiv.org/abs/2205.15517
作者:Jingxiang Sun,Xuan Wang,Yichun Shi,Lizhen Wang,Jue Wang,Yebin Liu
内容整理:王睿妍——煤矿工厂
引入
人像合成在计算机图形学中有着广泛的应用,包括虚拟现实(VR)、增强现实(AR)、基于化身的电信等。在这种情况下,生成器有望在控制多种因素(例如发型、穿着、姿势、瞳孔颜色)的情况下合成照片真实的面部图像。文中指出,现有的基于 StyleGAN 的方法通过学习潜在空间中的属性特定方向,或者通过调节各种先验来学习更为清晰和可控的潜在空间,从而实现编辑能力。这种方法对合成 2D 图像有效,但如果直接应用于编辑 3D 面部的不同视图,则会出现视图不一致的问题。早期基于NeRF的生成器用于生成视图一致的肖像,但只能以有限的分辨率和保真度合成图像。
挑战
现有的3D感知面部生成方法在质量和可编辑性方面面临两难境地:它们要么以低分辨率生成可编辑结果,要么生成没有编辑灵活性的高质量结果。
贡献
- 提出了一种高分辨率语义感知 3D 生成器,它可以对局部形状和纹理进行解纠缠控制。
- 提出了一种混合 GAN 反演方法,该方法可以将面部图像和语义掩模真实地反演到潜在空间中。
- 提出了一个规范的编辑器模块,它能够以高质量的结果对自由视图肖像进行实时编辑。
具体实现
该系统由三个主要组成部分组成:(1)一个3D语义感知生成模型:它生成视图一致的、解纠缠的人脸图像和语义面具;(2)一种混合GAN反转方法:其初始化来自语义和纹理编码器的潜在代码,并进一步优化它们以实现真实的重建;(3)规范编辑器:其能够在规范视图中有效地操纵语义掩码并产生高质量的编辑结果。
总体框架图
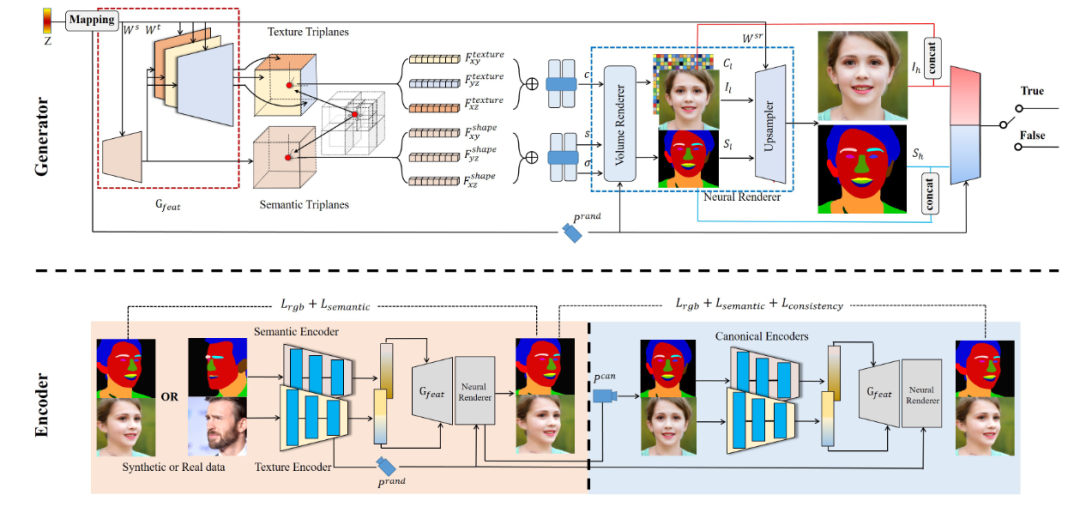

- 3D生成器(上部)由几个部分组成。首先,StyleGAN 特征生成器 Gfeat 在有效的三平面表示中构造语义和纹理的空间对齐的3D体积。为了解耦不同的面部属性,形状和纹理代码分别注入 Gfeat 的浅层和深层。此外,深层被设计为与每个特征平面相对应的三个平行分支,以减少它们之间的纠缠。给定生成的3D体积,可以通过体积渲染和基于 2D CNN 的上采样器来联合渲染 RGB 图像和语义Mask。
- 编码器(下部)通过两个独立的编码器将肖像图像和相应的语义掩码嵌入到纹理和语义潜码中。使用预测的相机姿势,然后固定生成器在预测的相机姿态下重建肖像。为了消除位姿的影响联合训练了一个规范编辑器,该编辑器将规范视图下的肖像图像和语义掩码作为输入,加强了视图一致性。
逼真的 3D 语义感知 GAN
多重 StyleGAN 生成器

双 MLP 解码器(Dual MLP decoders)

双重鉴别器(Dual discrimination)

密度正则化(Density regularization)
数据集的相机姿态分布不平衡会导致在合成图像和提取的网格中观察到沿着面部边缘的“接缝”伪影,因此从侧视图渲染生成具有平滑形状面部的具有挑战性。在IDE-3D中引入了密度正则化损失,该损失正则化了密度场,使得附近的3D点具有相似的密度值。密度正则化损失为:
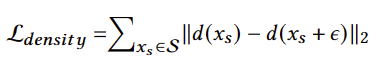
上式中 S 表示精细点的集合,𝑑 (𝑥) 是预测点 x 的密度。
训练损失 loss
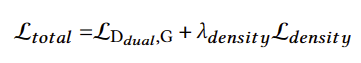
混合GAN反演和标准编辑器
编码器训练和多视图增强
本文介绍了一种混合 GAN 反演方法,它可以看作是基于学习和基于优化的方法的组合。两个编码器将输入图像和语义映射映射到潜在空间 Ws+ 和 Wt+。通过在纹理分支的输出中附加两个维度来预测偏航角和俯仰角来实现从位姿纠缠的2D 图像中提取相机姿势(θ 和 Φ)。同时本文提出了一种多视图增强策略,特别是对于合成肖像图像,从另一个图像渲染𝑘 随机视图,并将它们与双重鉴别约束一起训练。多视图增强有助于内容和姿态更好地解纠缠,并提高不同视图之间基于学习的反转的稳定性,以实现重建效果的真实性。
实验和应用
本文在两个流行的人脸合成和编辑数据集上训练和评估模型:CelebAHQ-Mask和FFHQ。
实验结果
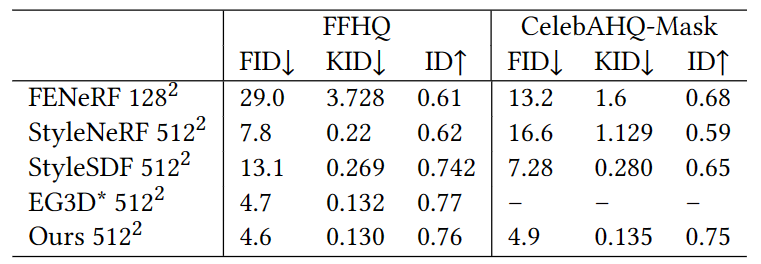
上表是 IDE-3D 在 FFHQ 和 CelebAHQ-Mask 数据集上与 FENeRF 、 StyleNeRF、StyleSDF 和 EG3D 进行定量比较,可以看出 IDE-3D 显示了所有数据集中最先进的图像合成质量和视图一致性。

上图是FENeRF、StyleNRF、StyleSDF和 IDE-3D 的定性比较。FENeRF合成视图一致的图像,而渲染分辨率和图像质量受到限制。StyleNeRF 和 StyleSDF 显示出令人印象深刻的图像合成质量,StyleSDF也在训练过程中通过隐式SDF表示和几何约束学习到了高质量的形状,但无法捕获形状细节。而 IDE-3D 不仅在图像合成中实现了更高的光感度,而且还实现了更高保真程度的几何结构。
应用
交互式神经3D人脸绘制和编辑
给定取自真实肖像图像或从形状潜在空间随机采样的语义掩模,IDE-3D 可以生成具有与输入语义掩模相同布局的 3D 人脸。下图中显示了一些面部属性编辑示例,例如发型、眼镜、帽子、眼睛和表情。可以观察到在处理形状和表达式时,IDE-3D 很好地保留了未编辑的局部区域。

局部纹理编辑
利用神经解码器的语义分割分支,IDE-3D 可以预测每个3D点的语义标签。通过选择用户特定的目标区域(例如头发、眼睛、布料等)可以构建一个3D样式的掩模,该掩模仅根据语义标签选择属于这些语义类的3D点。然后给定所需的纹理样式生成新的纹理三平面,并由此查询来替换所选 3D 点的颜色。该应用如下图所示。

真实肖像本地编辑
下图是IDE-3D 与 SofGAN 和 FENeRF 进行比较的结果图。从图中比较可知我们的方法在编辑保真度、图像质量和视图一致性方面优于 SofGAN 和 FENeRF 。SofGAN和 IDE-3D 都在输入视图中获得了高保真的反演结果,但是 SofGAN 在生成其它视角时明显改变了人脸形状。FENeRF 由于其 3D 特性,实现了高视图一致性,但难以重建高保真纹理细节,同时 FENeRF 也未能对眼镜进行建模。

限制
在本文的最后,作者指出由于自由视图肖像被编码在 3D 体积中,使用单个图像来重建3D面部体积是一个不确定的问题。因此在某些情况下会生成原本不可见的面部几何图形。
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。