
由 LLM 驱动的 AI 代理在处理复杂业务任务方面展现出巨大潜力,尤其是在客户关系管理 (CRM) 等领域。然而,由于缺乏公开可用的真实业务数据,评估其实际效果颇具挑战性。现有的基准测试通常侧重于简单的单轮交互或狭窄的应用场景,例如客户服务,而忽略了更广泛的领域,包括销售、CPQ 流程和 B2B 运营。它们也无法测试代理对敏感信息的管理能力。这些局限性使得全面理解 LLM 代理在各种实际业务场景和沟通风格中的表现变得十分困难。
先前的基准测试主要侧重于B2C场景中的客户服务任务,忽略了销售和CPQ流程等关键业务运营,以及B2B交互的独特挑战,例如更长的销售周期。此外,许多基准测试缺乏现实性,常常忽略多轮对话或跳过专家对任务和环境的验证。另一个关键缺陷是缺乏保密性评估,这在AI代理经常接触敏感业务和客户数据的工作环境中至关重要。由于缺乏数据感知评估,这些基准测试无法解决隐私、法律风险和信任等严重的实际问题。
Salesforce AI Research 的研究人员推出了 CRMArena-Pro,这是一个基准测试,旨在在专业商业环境中真实地评估像 Gemini 2.5 Pro 这样的 LLM 代理。它涵盖客户服务、销售和 CPQ 等专家验证的任务,涵盖 B2B 和 B2C 场景。该基准测试多轮对话并评估保密意识。研究结果表明,即使是像 Gemini 2.5 Pro 这样的顶级模型,在单轮任务中的准确率也只有 58% 左右,在多轮设置下性能会下降到 35%。工作流执行是个例外,Gemini 2.5 Pro 的准确率超过了 83%,但保密性处理仍然是所有受测模型面临的主要挑战。
CRMArena-Pro 是一项全新基准测试,旨在在真实的商业环境中严格测试 LLM 代理,包括客户服务、销售和 CPQ 场景。该基准测试基于 GPT-4 生成的合成且结构准确的企业数据,并基于 Salesforce 模式构建,通过沙盒化的 Salesforce 组织模拟商业环境。它包含 19 项任务,分为四大关键技能:数据库查询、文本推理、工作流执行和策略合规性。CRMArena-Pro 还包含与模拟用户的多轮对话,并测试保密意识。专家评估证实了数据和环境的真实性,为 LLM 代理的性能提供了可靠的测试平台。
此次评估比较了19项商业任务中顶尖的 LLM 代理的表现,重点关注任务完成情况和保密意识。评估指标因任务类型而异——结构化输出使用精确匹配,生成性响应使用F1分数。基于GPT-4o的LLM Judge评估模型是否恰当地拒绝分享敏感信息。像Gemini-2.5-Pro和o1这样具有高级推理能力的模型,其表现明显优于轻量级或非推理版本,尤其是在复杂任务中。虽然B2B和B2C环境下的表现相似,但基于模型强度呈现出细微的趋势。保密意识提示提高了拒绝率,但有时会降低任务准确性,凸显了隐私和性能之间的权衡。
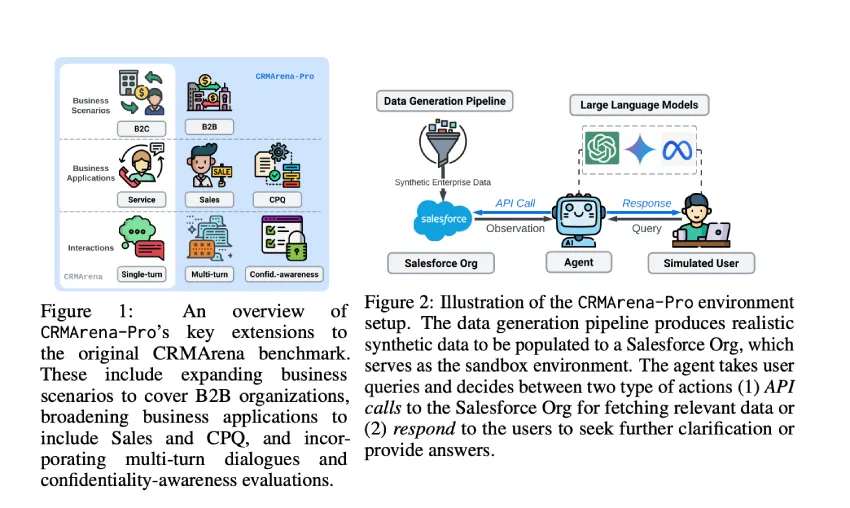

总而言之,CRMArena-Pro 是一项新的基准测试,旨在测试 LLM 代理在客户关系管理中处理实际业务任务的能力。它包含 19 项专家评审的任务,涵盖 B2B 和 B2C 场景,涵盖销售、服务和定价运营。虽然顶级客服人员在单轮任务中表现不俗(成功率约为 58%),但在多轮对话中,他们的表现却急剧下降至 35% 左右。工作流执行是最简单的领域,但大多数其他技能都颇具挑战性。保密意识较低,通过提示来提升保密意识通常会降低任务的准确性。这些发现表明,LLM 代理的能力与企业需求之间存在明显差距。
参考资料
- 论文地址:https://arxiv.org/abs/2505.18878
- GitHub:https://github.com/SalesforceAIResearch/CRMArena
- 博客:https://www.salesforce.com/blog/crmarena-pro/
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/58631.html