
摘要:VISTA 是一种多智能体框架,可在推理过程中提升文本到视频的生成效果。该方法将结构化提示规划为场景,通过成对的比赛机制筛选最佳候选方案,运用视觉、音频及上下文领域的专业评判器,再由深度思考提示智能体重构提示文本。在单场景与多场景设置中,该方法相较于强大的提示优化基线均展现出持续提升,且人类评分者更青睐其生成的输出结果。

VISTA 是什么?
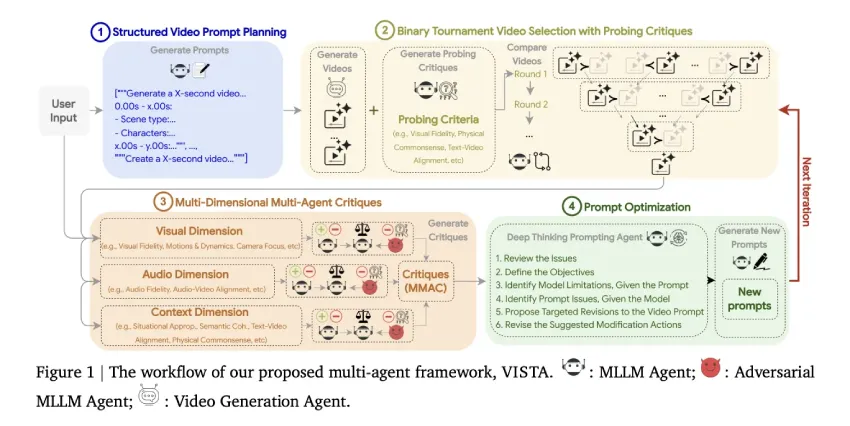
VISTA 是视频迭代自我改进智能体(Video Iterative Self-improvement Agent)的缩写。它是一个黑盒多智能体循环系统,能在测试时优化提示词并重新生成视频。该系统同时针对视觉、音频和上下文三个方面,遵循四个步骤:结构化视频提示词规划、成对竞赛选择、多维度多智能体评价,以及用于提示词重写的深度思考提示智能体。
研究团队在单场景基准测试和内部多场景集上对 VISTA 进行了评估。报告显示,VISTA 取得了持续的改进,在某些场景下,其与最先进的基线相比,成对胜率高达 60%,而与最强基线相比,人类偏好度达到了 66.4%。

了解关键问题
像 Veo 3 这样的文本转视频模型可以生成高质量的视频和音频,但输出仍然对精确的提示措辞敏感,可能无法完全遵循物理规律,并且与用户目标的匹配度可能会出现偏差,这迫使人们进行手动反复试验。VISTA 将此定义为测试时间优化问题。它寻求在视觉信号、音频信号和上下文对齐方面实现统一的改进。
VISTA 如何一步步运作?
步骤 1:结构化视频提示规划
用户提示被分解为定时场景。每个场景包含 9 个属性:时长、场景类型、角色、动作、对话、视觉环境、摄像机、声音和情绪。多模态 LLM 会填充缺失的属性,并默认强制执行对真实性、相关性和创造性的约束。系统还会将原始用户提示保留在候选集中,以方便那些无法从分解中获益的模型。
步骤 2:成对淘汰赛视频筛选
系统抽取多个视频与提示词组合。通过 MLLM 模型担任评判者,采用二元淘汰赛机制并实施双向交换以消除词序偏见。默认评估标准涵盖视觉保真度、物理常识性、文本视频对齐度、音视频同步度及用户参与度。该方法首先通过探询式批判支持分析,随后执行成对比较,并对常见文本视频匹配失效问题施加可定制惩罚机制。
步骤 3:多维多智能体评审
冠军视频和提示将从视觉、听觉和语境三个维度进行评审。每个维度都采用三位一体的评审方式,即一名普通评审、一名对抗性评审和一名整合双方意见的元评审。评审指标包括:视觉保真度、动作和动态、时间一致性、摄像机对焦和视觉安全性(视觉方面);音频保真度、音视频匹配度和音频安全性(音频方面);情境恰当性、语义连贯性、文本视频匹配度、物理常识、参与度和视频格式(语境方面)。评分范围为1到10分,有助于有针对性地发现错误。
步骤 4:深度思考提示剂
推理模块读取元评论并运行 6 步自省,它识别低分指标,澄清预期结果,检查提示充分性,将模型限制与提示问题分开,检测冲突或模糊性,提出修改措施,然后为下一代周期采样精炼提示。

理解结果
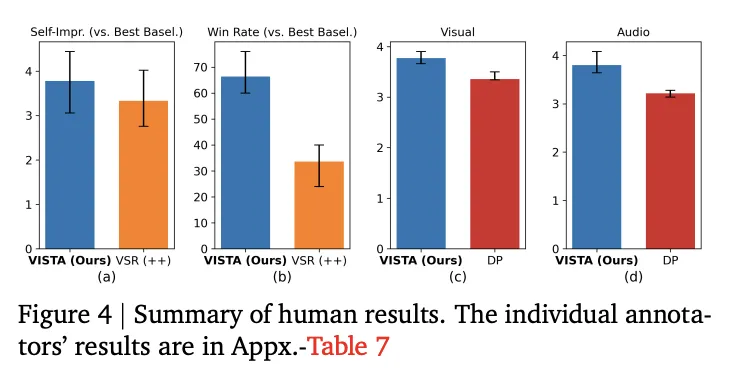
自动评估:该研究报告了基于十项标准的胜率、平局率和负率,并使用MLLM作为评判标准,并进行了双向比较。VISTA在直接提示方面的胜率随着迭代次数的增加而上升,在第5次迭代时,单场景的胜率达到45.9%,多场景的胜率达到46.3%。在相同的计算预算下,VISTA在每条基线上都取得了直接胜率。
人类研究:具有提示优化经验的注释者在第 5 次迭代中与最佳基线进行的 66.4% 的头对头试验中更喜欢 VISTA。专家对 VISTA 的优化轨迹的评价更高,并且他们对视觉质量和音频质量的评分高于直接提示。
成本与扩展:两个数据集中,每次迭代的平均标记数约为 70 万,不包括生成标记。大多数标记的使用来自选择和评论,这些操作将视频作为长上下文输入进行处理。胜率往往会随着每次迭代采样视频和标记数量的增加而增加。
消融:移除即时规划会削弱初始化。移除锦标赛选择会破坏后续迭代的稳定性。仅使用一种裁判类型会降低性能。移除深度思考提示代理会降低最终胜率。
评估者:研究团队使用替代评估模型重复评估,并观察到类似的迭代改进,这支持了趋势的稳健性。
关键要点
- VISTA 是一个测试时间、多智能体循环,可联合优化文本到视频生成的视觉、音频和上下文。
- 它将提示规划为定时场景,具有 9 个属性:持续时间、场景类型、人物、动作、对话、视觉环境、摄像机、声音、情绪。
- 候选视频是通过两两比赛选出的,使用具有双向交换功能的 MLLM 裁判,根据视觉保真度、物理常识、文本视频对齐、音频视频对齐和参与度进行评分。
- 每个维度(正常、对抗、元)的三位评委产生 1 到 10 个分数,指导深度思考提示智能体重写提示并进行迭代。
- 结果显示,在第 5 次迭代中,与直接提示相比,单一场景的获胜率为 45.9%,多场景的获胜率为 46.3%,人类评估者在 66.4% 的试验中更喜欢 VISTA,每次迭代的平均令牌成本约为 70 万。
总结
VISTA 是迈向可靠的文本转视频生成的实用一步,它将推理视为一个优化循环,并将生成器视为一个黑匣子。结构化的视频提示规划对早期工程师非常有用,9 个场景属性提供了具体的检查清单。由多模态 LLM 评委和双向交换组成的成对淘汰赛选择是减少排序偏差的明智方法,其标准针对真实的故障模式、视觉保真度、物理常识、文本视频对齐、音频视频对齐和参与度。多维度的评审将视觉、音频和语境区分开来,常规、对抗和元评委揭示了单个评委所忽略的弱点。深度思考提示智能体将这些诊断信息转化为有针对性的提示编辑。Gemini 2.5 Flash 和 Veo 3 的使用明确了参考设置,Veo 2 的研究提供了一个有用的下限。报告的 45.9% 和 46.3% 的胜率以及 66.4% 的人类偏好表明了可重复的收益。 70 万个代币的成本并不低,但却透明且可扩展。
参考资料
- 论文:https://arxiv.org/abs/2510.15831
- 项目:https://g-vista.github.io/?fbclid=IwY2xjawNlRJZleHRuA2FlbQIxMABicmlkETFac0dMQjZ2ZDBLbXRLWXR5AR40nxx-oIXVJiw6cc07zX0hmZVNpeFVRDM93PdloXGzv7KWqtj0xfc1X-sZ3w_aem_L4b2OUzoeuV4UTl3xGNcFA
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/62406.html