
Khronos® 的 OpenVX™ 工作组发布了两个专门针对现代异构系统上计算机视觉和人工智能应用开发而开发的扩展,旨在解决长期以来制约开发者构建此类应用的瓶颈。这两个新扩展分别是目标内核扩展 ( Target Kernel)和节点命令扩展 (Node Command extension ),它们都着力解决随着片上系统 (SoC) 架构日益复杂而愈发严峻的问题:如何在专用硬件上高效分配计算任务,以及如何在运行时动态调整处理流水线而无需触及数据路径。这两个扩展的功能将作为核心特性包含在下一个主要 API 版本 OpenVX 2.0 中。
现代计算机视觉系统必须在日益复杂的硬件架构上高效处理海量传感器数据。例如,车辆的环视系统可能需要同时协调十几个摄像头、雷达传感器和人工智能加速器,而主机处理器则需要管理中断、直接内存访问 (DMA) 和多个数据流水线。工业机器人和智慧城市基础设施也面临着类似的挑战,它们的处理流水线必须实时调整,避免丢帧或操作停滞。这两个扩展正是为了满足这些需求而开发的。
Node Command 扩展:毫不妥协的运行时控制
现实世界的生产系统并非一成不变。一辆自动驾驶汽车从拥堵的市中心驶入开阔的高速公路,需要相同的视觉流水线在从人行横道行人检测切换到高速跟踪远处车辆时,能够根据不同的参数、阈值和处理优先级进行切换,并且无需停止系统进行重新配置。
在此扩展之前,OpenVX 并没有为开发者提供简洁的解决方案,迫使他们做出妥协。他们可以使用静态参数,但这限制了灵活性,并且通常需要停止并重新创建整个处理图才能调整一个阈值。一些开发者尝试通过输入/输出参数传递控制信号,本质上是将数据路径重新用于控制,但这会给每个处理帧增加不必要的开销。另一些开发者则采用自定义的、特定于供应商的控制机制,这导致他们被锁定在专有解决方案中,并且代码无法跨平台移植。
Node Command 扩展消除了这种权衡。它引入了一个轻量级的异步控制通道,该通道独立于数据路径运行。因此,发送用于调整阈值、请求诊断或触发安全检查的命令不会影响流水线的吞吐量。控制和数据各自独立运行,系统保持便携性。
Target Kernel:释放异构计算潜力
现代系统级芯片(SoC),例如DSP、GPU、NPU和专用加速器,虽然计算能力丰富,但OpenVX最初的用户内核模型却将自定义计算功能束缚在主机CPU上。在汽车和物联网部署中,这确实是一个问题。主机已经需要管理来自十几个甚至更多传感器的中断、DMA、缓冲区和数据管道。若强行让自定义内核在主机上运行,则会导致主机过载,或使专用硬件闲置。
Target Kernel 扩展消除了这一限制。开发者现在可以直接在远程计算目标上注册并执行用户内核,无需通过主机进行处理。主机专注于协调与控制,而繁重的计算任务则转移到专为此设计的硬件上。其结果是延迟降低、主机 CPU 负载减轻,且处理管道能够真实反映其运行的架构特性。
这一方案适用于广泛的 SoC 设计。基于异构架构(包括 big.LITTLE 风格配置)的现代平台,使得在不同内核及功耗/性能域之间部署内核变得轻而易举。下图展示了一种可能的配置,其中目标内核分布于多个 CPU 子系统和加速器之上。
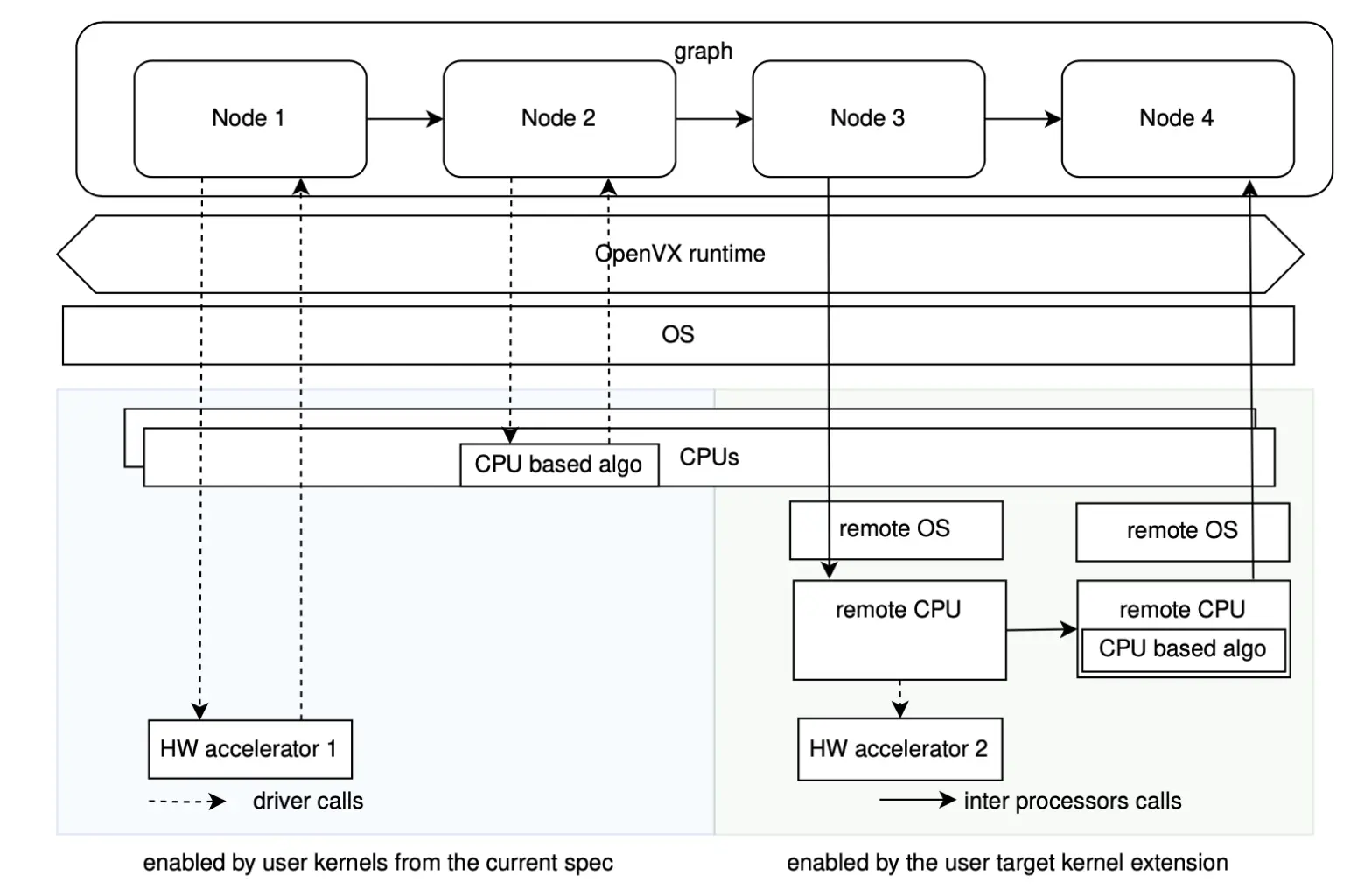

该扩展自然地构建于现有的 OpenVX 用户内核模型之上。在主机端,应用相同的 API,内核处理回调被简单地设置为 NULL,因为执行发生在其他地方。在目标端,vxAddTargetKernel 注册了四个回调:
- 用于 amin 计算逻辑的 process_func
- 用于图验证期间一次性设置的 create_func
- 删除图表发布时清理工作的函数
- control_func 用于通过 vxNodeSendCommand 发送可选的异步命令
最后一个回调直接连接到上面描述的 Node Command 扩展,允许运行时控制消息到达目标端内核而无需触及数据路径。
这些扩展共同完善了 OpenVX 2.0 的功能集。它们直接满足了现代计算机视觉和人工智能系统的两大关键需求:在异构硬件上高效分配计算资源,以及在运行时动态调整处理流水线。
译自:https://www.khronos.org/blog/openvx-extensions-unlock-computer-vision-and-ai-capabilities
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/66178.html