
Hugging Face 发布了ml-intern,这是一款开源 AI 代理,旨在自动化大型语言模型 (LLM) 的端到端训练后工作流程。该工具基于 Hugging Face 的smolagents框架构建,能够自主执行文献综述、数据集发现、训练脚本执行和迭代评估,这些任务通常需要机器学习研究人员和工程师投入大量人力。
ml-intern 能做什么
该智能体以循环方式运行,模拟机器学习研究人员的工作流程。它首先浏览arXiv和Hugging Face Papers,阅读方法论部分并遍历引用图谱,以识别相关的数据集和技术。然后,它在Hugging Face Hub中搜索引用的数据集,检查其质量,并将其重新格式化以用于训练。当本地计算资源不足时,智能体可以通过Hugging Face Jobs启动训练任务。每次训练运行后,它会读取评估输出,诊断故障(例如 RLHF 流水线中的奖励崩溃),并重新训练,直到基准性能得到提升。
整个监控堆栈依赖于Trackio,这是一个 Hub 原生的实验跟踪器,定位为 Weights & Biases 的开源替代方案。

PostTrainBench 性能
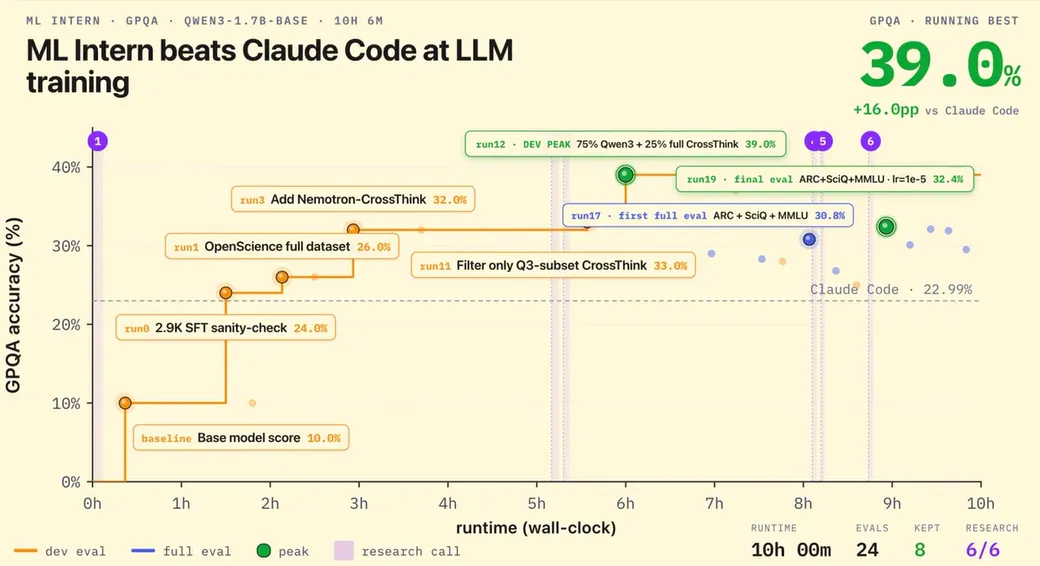
ml-intern 的评估采用了PostTrainBench基准测试,该基准测试由蒂宾根大学和马克斯·普朗克研究所的研究人员推出。该基准测试测试智能体在单个 H100 GPU 上,于严格的10 小时时间窗口内完成基础模型后训练的能力。
在官方发布演示中,ml-intern使用Qwen3-1.7B基础模型(该模型在 GPQA 上的基准得分约为10% ),并在不到 10 小时内将其得分提升至32%。该智能体的进步速度惊人,仅用了 3 个多小时就突破了27.5% 的得分大关。
与现有最先进技术(SOTA)相比,这一结果尤为显著。Hugging Face 的数据显示,该智能体的性能优于Claude Code,后者目前在同一任务上的基准准确率为22.99%。虽然 PostTrainBench 论文使用更大的 Gemma -3-4B 模型取得了 33% 的最高准确率,但 ml-intern 仅使用 17 亿字节的 Qwen 模型就取得了 32% 的准确率,这展现了极高的“数据效率”,而人工研究人员往往难以在如此短的时间内达到这一水平。
技术方法:合成数据和GRPO
ml-intern 在已发布的演示中展示的两种技术策略值得从业者重点关注。
合成数据生成:在医疗保健领域测试中,该智能体评估了现有的医疗数据集,发现其质量不足以进行可靠的微调,于是编写了一个脚本来生成合成训练样本,重点关注一些特殊情况,例如医疗术语和多语言应急响应场景。然后,它对这些数据进行上采样,以扩充训练分布,最后在 HealthBench 上进行评估。
基于GRPO的自主RLHF:在数学领域测试中,智能体实现了组相对策略优化(GRPO)训练脚本——该技术利用人类反馈进行强化学习,且内存开销低于标准PPO。智能体在A100 GPU上启动训练,监控奖励曲线,并在完成检查点之前运行消融实验以分离有效组件。
要点总结
- 自主研究循环:该代理复制完整的机器学习工作流程,从在arXiv上进行文献综述和遍历引用图,到自主执行训练运行和诊断故障。
- 推理能力显著提升:在不到 10 小时内,该智能体将 Qwen3-1.7B 模型在 GPQA 基准测试中的科学推理得分从8.5% 提高到 32% ,超过了 Claude Code 在 GPQA 测试中的特定成绩(22.99%)。
- 高级训练策略:除了简单的微调之外,ml-intern 还可以为边缘情况生成高质量的合成数据,并实现诸如组相对策略优化 (GRPO)之类的复杂技术来优化数学性能。
- 原生生态系统集成:该工具基于 smolagents 框架构建,原生集成 Hugging Face Jobs 进行计算,并使用 Trackio 进行开源实验跟踪。
参考资料:
- https://huggingface.co/spaces/smolagents/ml-intern
- https://github.com/huggingface/ml-intern/tree/main
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/66327.html