
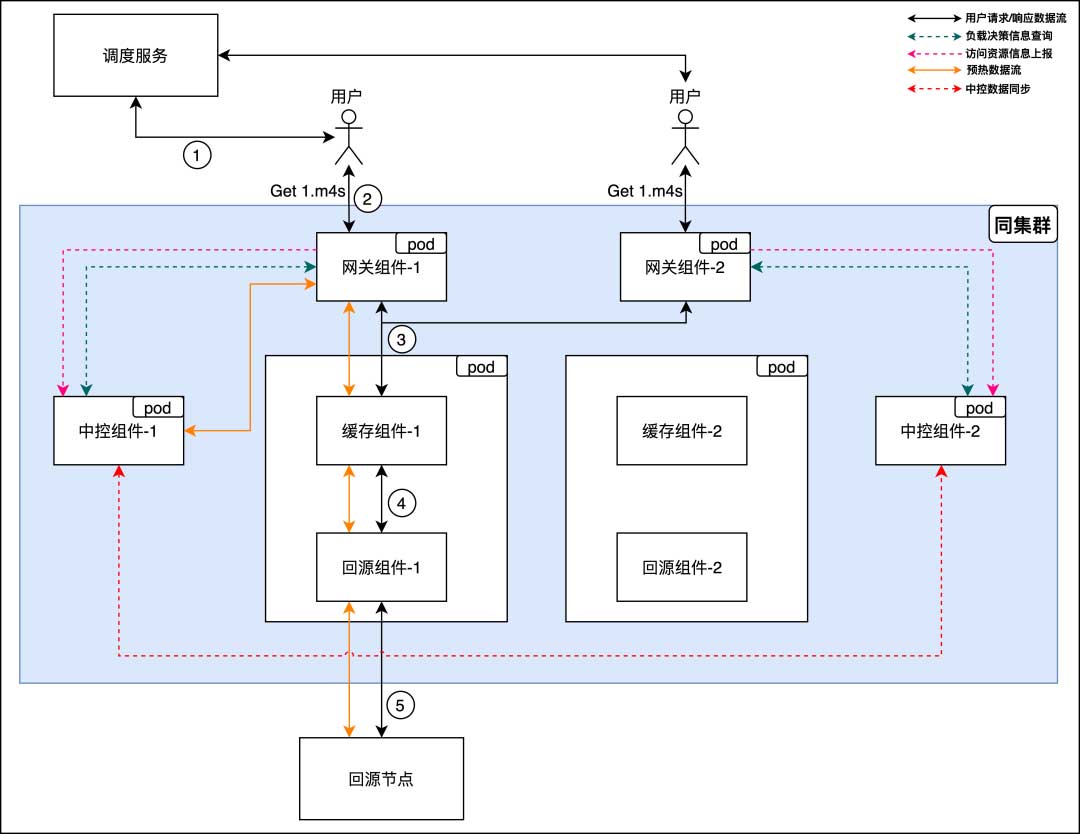
B站的下行CDN旧架构如下图所示,可以看到边缘CDN节点与中心调度服务有紧密协作,简单说是先由调度服务进行流量调度(负责均衡的调度到每个网关组件节点),再由回源组件进行集群内的回源收敛,最终到对应的回源节点进行回源。随着业务体量的增加,这种模式所带来的风险也不断的被暴露出来。
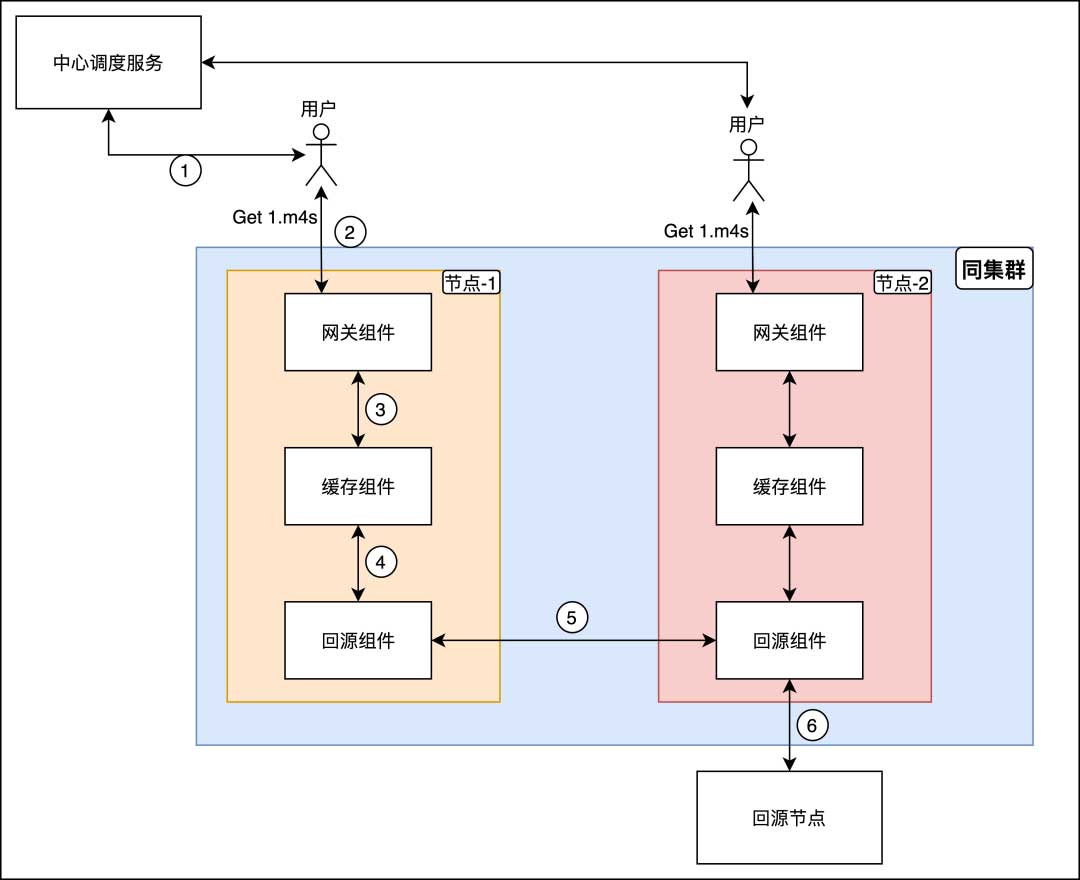

注:同集群指在相同机房;节点指物理机器或者容器
这种模式存在以下几种弊端:
- 中心调度服务的负载均衡策略与边缘同集群内的回源收敛策之间的协作难度大(回源节点选择不一致、资源冷热判断不一致等等),导致”事故”频繁
- 边缘节点出故障后,中心调度服务从感知到故障事件,再到流量切走,再到长尾流量干涸,这一过程起码需要20分钟,遇到直播业务那就更惨
- 资源(cpu、缓存)利用率不符合预期,存在毛刺多、不均衡和回源率高等问题,频繁触发SLO告警
- 治理/提升用户播放体验的开发难度大且复杂性高,比如资源预热,需要提前知道直播流会分配到哪几个网关节点上等等
根据以上几个点以及点/直播业务特性,我们提出了几个最基本的要求,以满足日益增长的流量和对播放质量的追求
- 网关组件必须具备流量分流能力,具备7层负载均衡加4层负载均衡能力
- 一套集群内组件服务状态检查机制,做到及时发现过载组件进行扩容以及能敏感发现故障组件进行踢出
- 所有策略功能都收敛到中控组件来完成,避免同个资源在不同节点上出现两种不同流量策略,同时也让原有的其他组件改动最小化(保持单体架构的开发思维,提升开发效率)
新架构设计
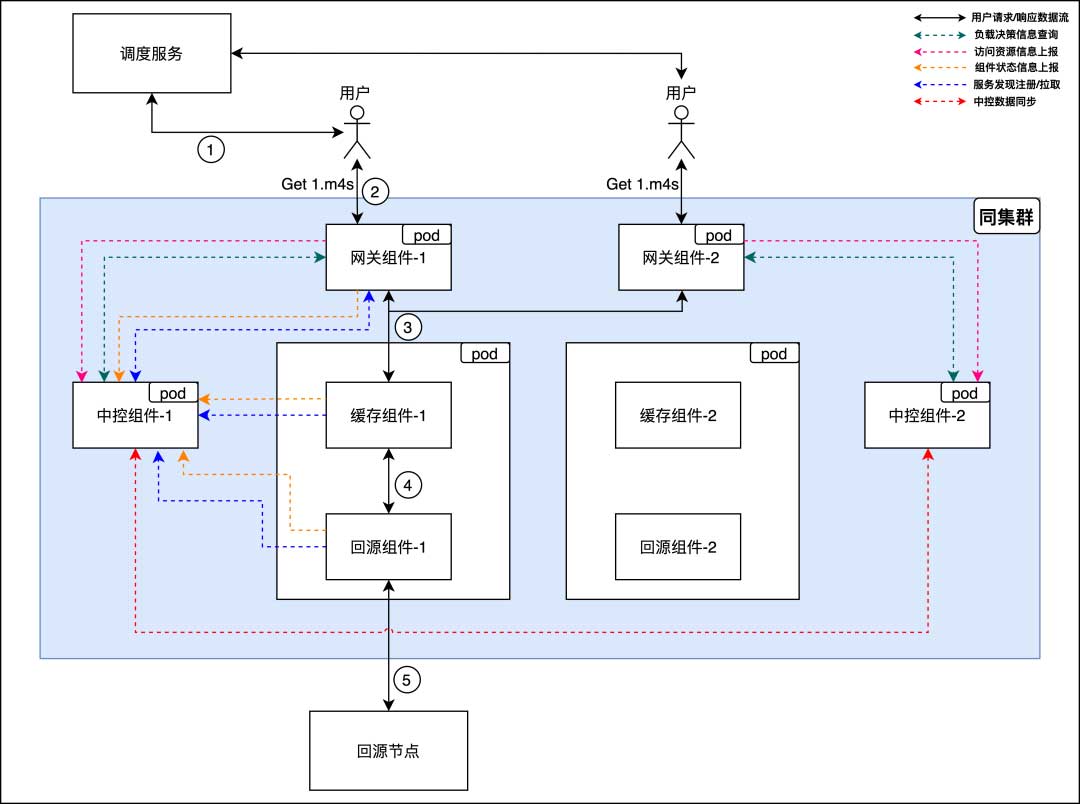
网关组件:对外提供用户的访问协议(H1、H2、H3),具备对访问流量进行鉴权、收敛等功能
缓存组件:聚焦磁盘IO技术栈、文件系统以及缓存淘汰策略等
回源组件:聚焦回源协议(私有/通用)以及如何提升回源速率等
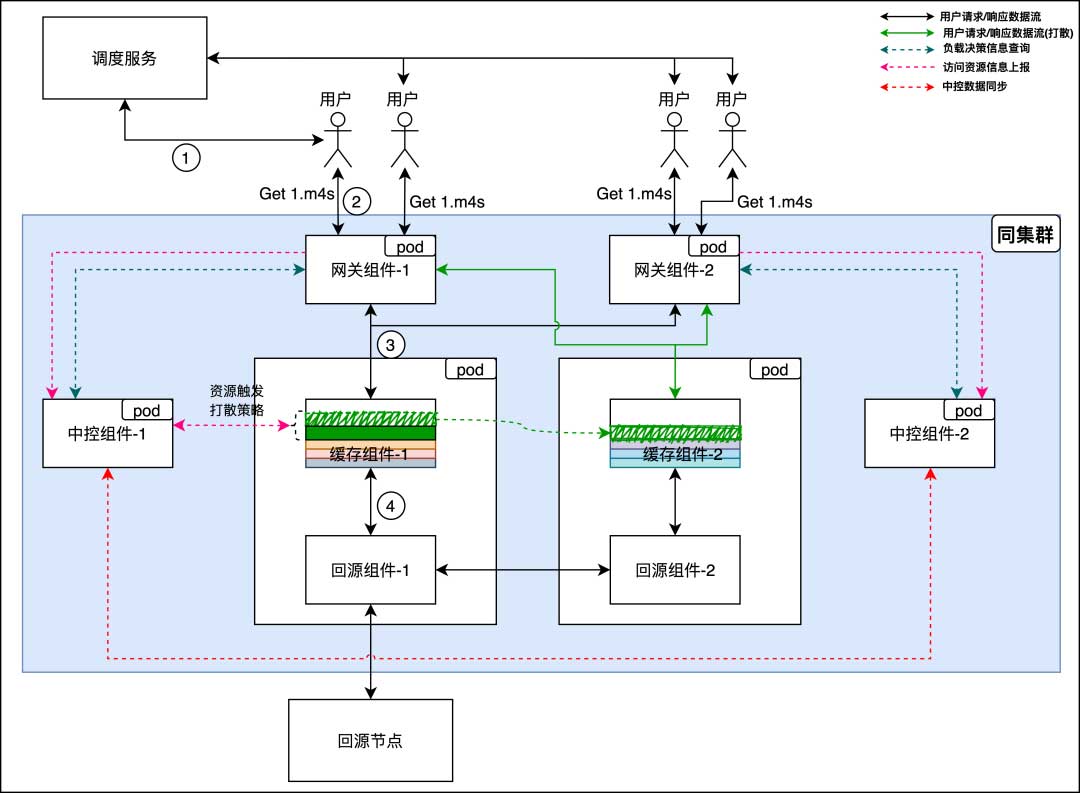
中控组件:聚焦集群内流量路由策略(热流打散、异常组件踢出等等)以及针对业务的定制化优化策略等
网关组件具备流量分流能力
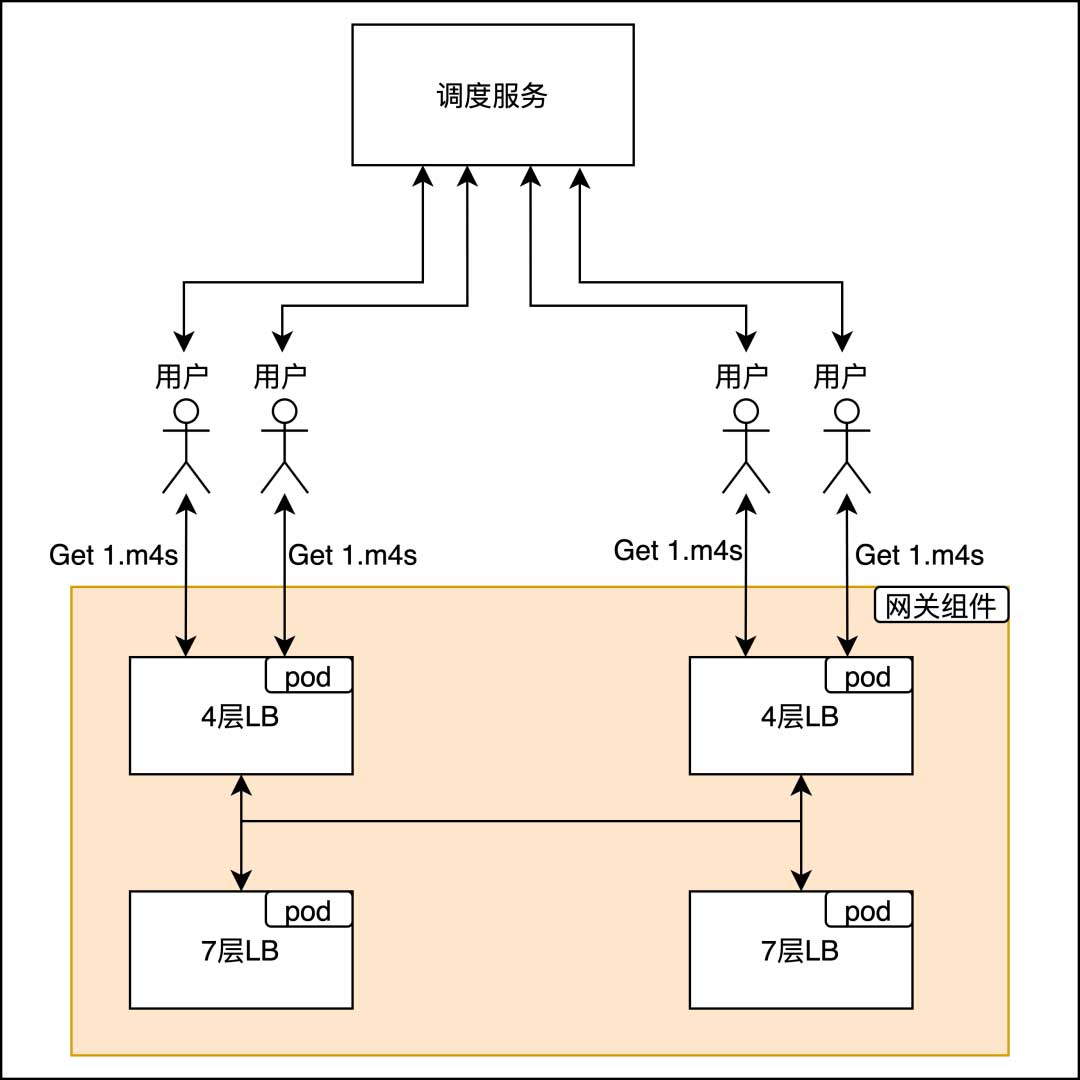
4层负载均衡
主要解决由于调度不均衡导致的节点负载不均衡问题,同时又能及时切走故障的7层节点,提升系统的整体容错性
7层负载均衡
主要解决当缓存组件或者回源组件出现问题时,踢掉问题组件并且重试到其他节点(回源依旧会优先回到之前的回源组件节点:图中5-1路线),保障用户的播放体验
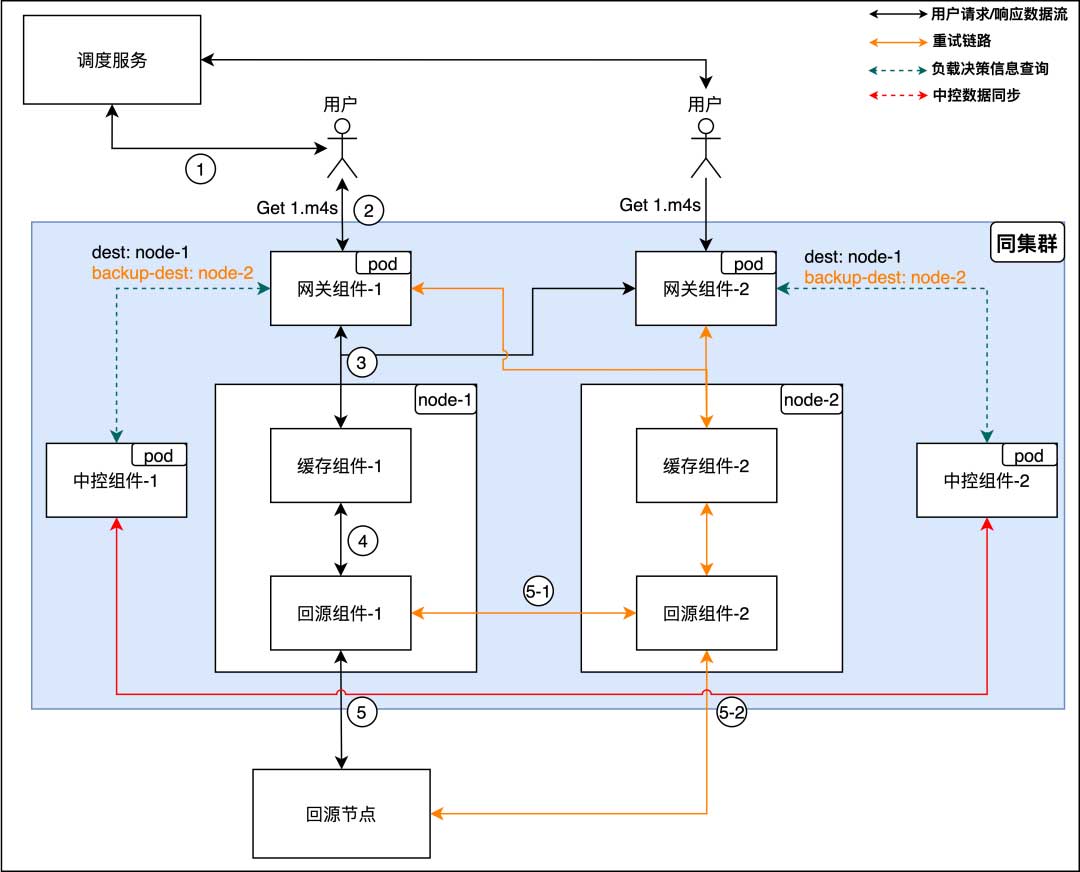
中控组件
现在流量入口的问题已经解决了,部分节点故障已经影响不到服务质量,接下来我们重点看一下中控组件(中控组件本身是多节点,且保证查询接口是数据一致的)是如何将其他组件节点串起来的
负载均衡策略
直播和点播的业务场景还是有些区别的,叠合一些历史问题,这次改造将点/直播负载均衡策略拆成两个单独模块实现,后续计划还是会整合到一起
- 直播负载均衡策略
我们将负载能力划分成一个个小长方条,当某个资源(流)占据的条数>=N时,则会触发流量打散策略,将溢出的流量划分给其他组件,如图中“组件-1”内的深绿色大长方条,被平均切割成3个中长方条
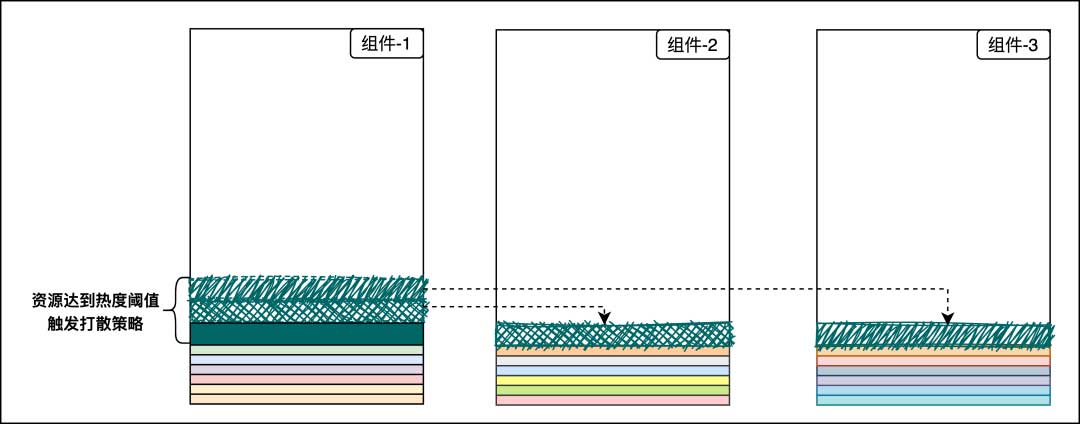
接着,我们可以看到网关组件会将每个请求的实时带宽同步到中控,这也是所有策略的数据源。中控组件对数据进行清洗、整合和观测,实时调整网关组件的流量链路,如图中绿色的实线链路
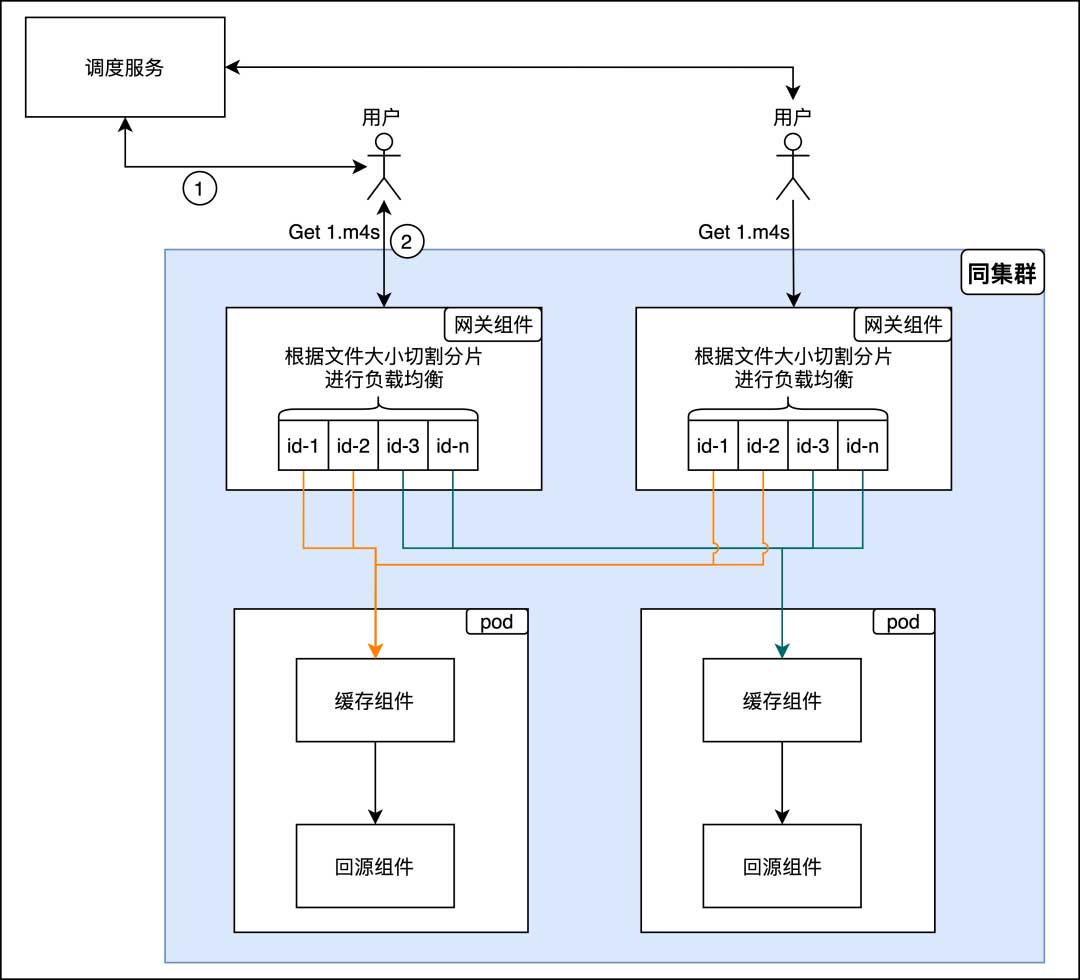
- 点播负载均衡策略
因点播文件大小普遍大于缓存组件的分片大小,所以在网关组件这边根据分片大小进行切分,并用一致性哈希方式进行负载均衡,虽然做法很糙,但也足够用
这里我们在nginx http slice 模块上进行了改造,原有的http_slice_module存在以下几个问题:
1)对齐后的offset会导致读放大(存在冗余数据),原设计是为了缓存,但我们架构有专门的缓存组件,并不需要nginx做缓存
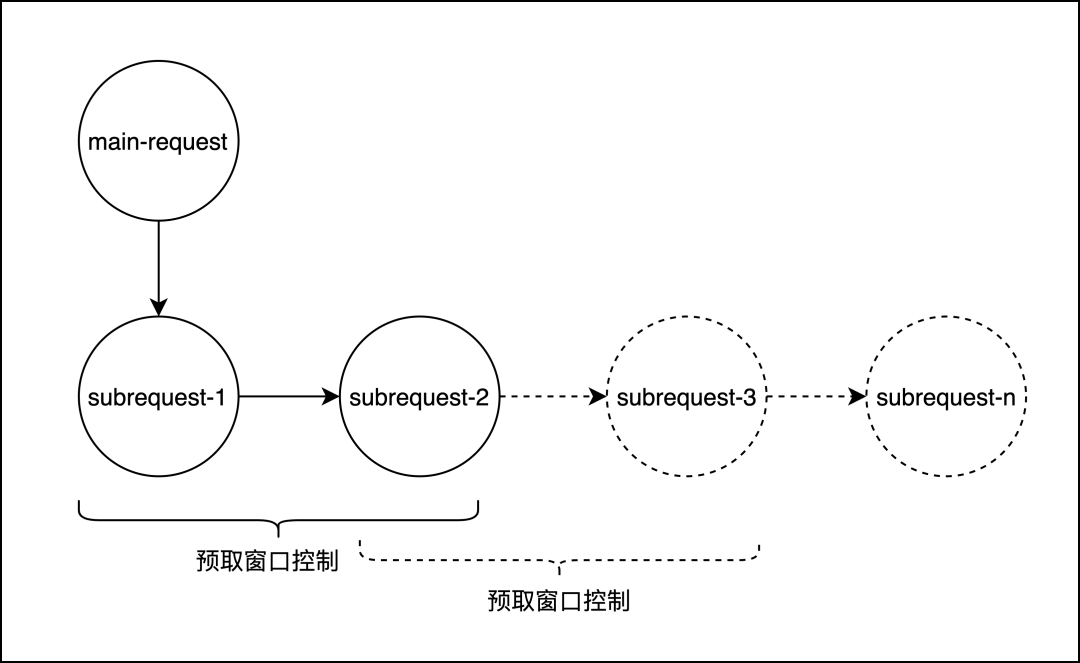
2)一定是前面的子请求结束后,才能发起下一轮的子请求,这可能导致非预期的“等待”(假设用户请求被切成N个请求,则需要多等待N-1个http header的结果)
我们的做法是增加预取窗口,在subrequest-2收到http header时,会触发subrequest-3请求的发送,同时控制同一时间只会存在两个subrequest,这样保证nginx内存不会过于膨胀,同时也不会对后端节点造成过大压力
代码如下:
typedef struct {
...
ngx_http_request_t* prefetch[2];
} ngx_http_slice_ctx_t;
ngx_http_slice_body_filter(ngx_http_request_t *r, ngx_chain_t *in)
{
...
if (ctx == NULL || r != r->main) {
// 确认前面的预取子请求已经完成header处理,可进行下一个分片预取
if (ctx && ctx->active) {
rc = ngx_http_slice_prefetch(r->main, ctx);
if (rc != NGX_OK) {
return rc;
}
}
return ngx_http_next_body_filter(r, in);
}
...
rc = ngx_http_next_body_filter(r, in);
if (rc == NGX_ERROR || !ctx->last) {
return rc;
}
if (ctx->start >= ctx->end) {
ngx_http_set_ctx(r, NULL, ngx_http_slice_filter_module);
ngx_http_send_special(r, NGX_HTTP_LAST);
return rc;
}
if (r->buffered) {
return rc;
}
if (ctx->active) {
// 分片预取
rc = ngx_http_slice_prefetch(r->main, ctx);
}
return rc;
}
ngx_http_slice_prefetch(ngx_http_request_t*r,ngx_http_slice_ctx_t* ctx)
{
// control prefetch win
if (ctx->prefetch[1]) {
if (!ctx->prefetch[0]->done) {
return NGX_OK;
}
ctx->prefetch[0] = ctx->prefetch[1];
ctx->prefetch[1] = NULL;
}
if (ctx->start >= ctx->end) {
return NGX_OK;
}
...
if (ngx_http_subrequest(r, &r->uri, &r->args, &ctx->prefetch[1], ps, NGX_HTTP_SUBREQUEST_CLONE)
!= NGX_OK) {
return NGX_ERROR;
}
ngx_http_set_ctx(ctx->prefetch[1], ctx, ngx_http_slice_filter_module);
ctx->active = 0;
...
// init once
if (!ctx->prefetch[0]) {
ctx->prefetch[0] = ctx->prefetch[1];
ctx->prefetch[1] = NULL;
}
ngx_http_slice_loc_conf_t* slcf = ngx_http_get_module_loc_conf(r, ngx_http_slice_filter_module);
off_t cur_end = ctx->start + get_slice_size(ctx->start, slcf);
// 判断对齐后末尾数值如果大于用户请求的末尾数值,则取用户的末位数值,避免读放大
if (slcf->shrink_to_fit) {
cur_end = ngx_min(ctx->end, cur_end);
}
gen_range(ctx->start, cur_end - 1, &ctx->range);
...
}我们做了一个简单的场景模拟,可以看到改造后请求的处理耗时比改造前处理耗时减少了40%,也就能更快响应用户的请求。
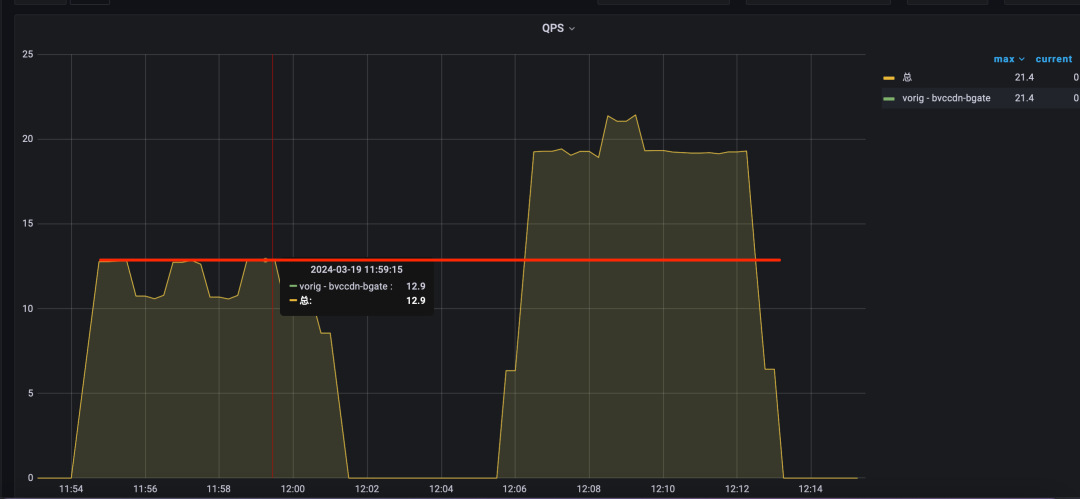
最终成效
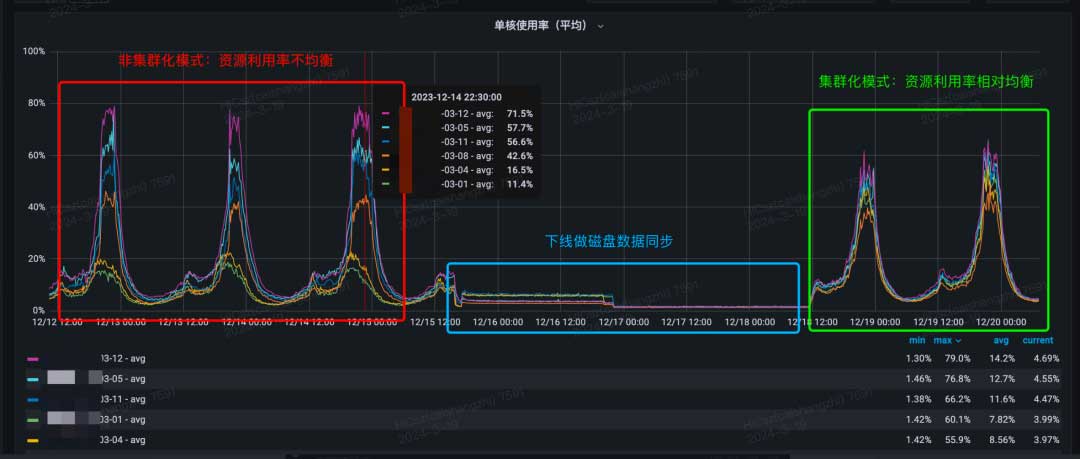
在点/直播负载策略共同生效下,可以看到相比之前旧架构有很大的稳定性提升。
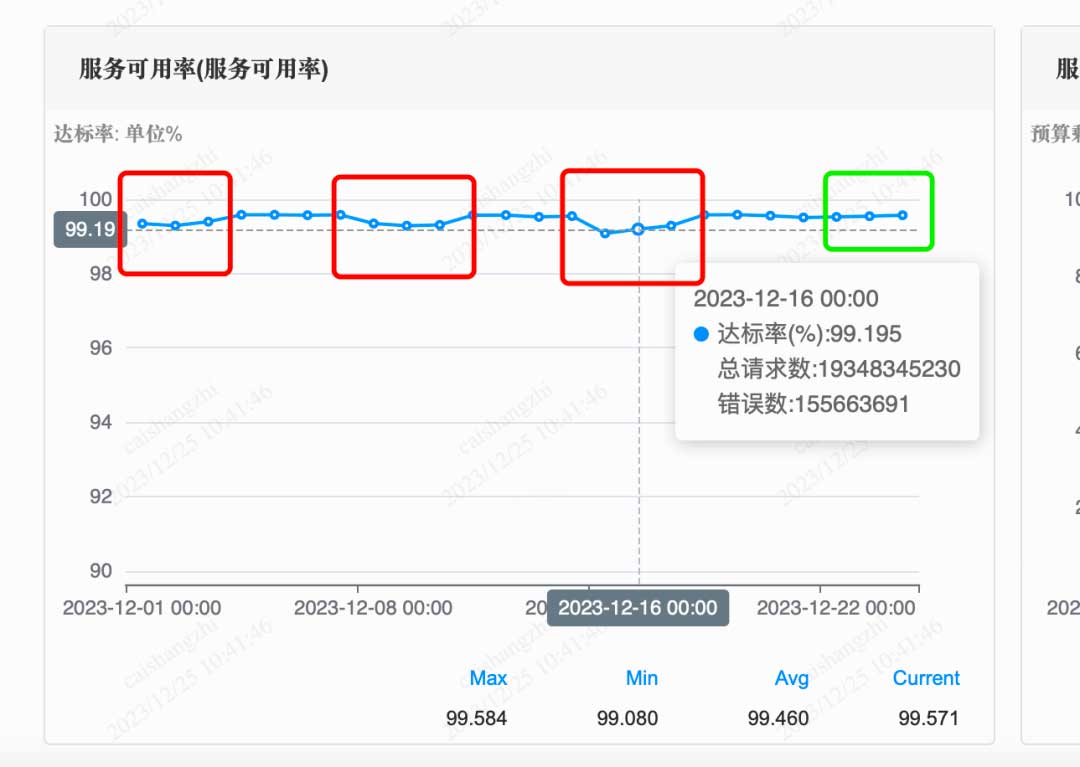
我们再看看SLO监控数据,在新架构未全量前,每个周末都会有部分集群触发SLO告警,在新架构逐步扩量后,SLO的抖动也减少了。
聊聊新架构如何业务赋能
业务混跑
点播、直播业务对于机器资源要求不同,点播更倾向拥有更多的磁盘来做IO吞吐和存储的横向扩容,而直播更倾向拥有更多的cpu资源来做协议的转封装或数据迁移拷贝。这就出现很微妙的关系,点播场景下可以利用DMA来减少cpu参与磁盘数据拷贝(我有空闲的cpu资源),而直播场景对于机械硬盘基本不用(我有空闲的磁盘资源),一拍即合
在点直播混跑情况下,点播回源率得到下降,直播拥有更多cpu资源能跑更多流,不管点播还是直播都能对外提供更好更快的服务,并且我们运营同学再也不需要为节点角色的转换(点播 或 直播?)而苦恼
直/点播预热
在旧架构模式下,开启预热很费劲,因不知道用户会访问哪个节点,所以只能采用广撒网方式,这种方式效率低不说,还可能空增加组件负担,并且预热任务也只能手动下发(并不知道谁是热的)
新架构模式下,每个集群会选出一个中控组件来实时观测集群热流,发现有热流后会触发预热策略,将预热任务下发到其中的一个网关组件。
存储资源最大化利用和编排
显而易见在旧架构模式下,网关组件只被允许访问本节点的缓存组件,所以只能保证单节点的存储资源是互斥的,并非整个集群的存储资源是互斥的。而新架构下,我们会根据每个缓存节点的存储容量和磁盘IO性能,重新规划了每个节点应被分配到的资源访问,尽可能保证每个缓存节点缓存的资源都是互斥的。再聊细点,我们知道机械硬盘的外圈吞吐量是大于内圈的,那在集群闲时期间,我们是不是可以做一些存储资源的重新编排,比如把热的资源移动到外圈以求获得更稳定的服务质量。
作者:蔡尚志,哔哩哔哩资深开发工程师;刘勇江,哔哩哔哩高级开发工程师;杨成进,哔哩哔哩高级开发工程师;张建锋,哔哩哔哩高级开发工程师
出自:B站CDN平台团队
版权声明:本文内容转自互联网,本文观点仅代表作者本人。本站仅提供信息存储空间服务,所有权归原作者所有。如发现本站有涉嫌抄袭侵权/违法违规的内容, 请发送邮件至1393616908@qq.com 举报,一经查实,本站将立刻删除。