
总部位于加州的语音 AI 初创公司 TwinMind 发布了 Ear-3 语音识别模型,声称其在多项关键指标上均达到了业界领先水平,并扩展了多语言支持。此次发布使 Ear-3 成为与 Deepgram、AssemblyAI、Eleven Labs、Otter、Speechmatics 和 OpenAI 等供应商提供的现有 ASR(自动语音识别)解决方案竞争的有力产品。
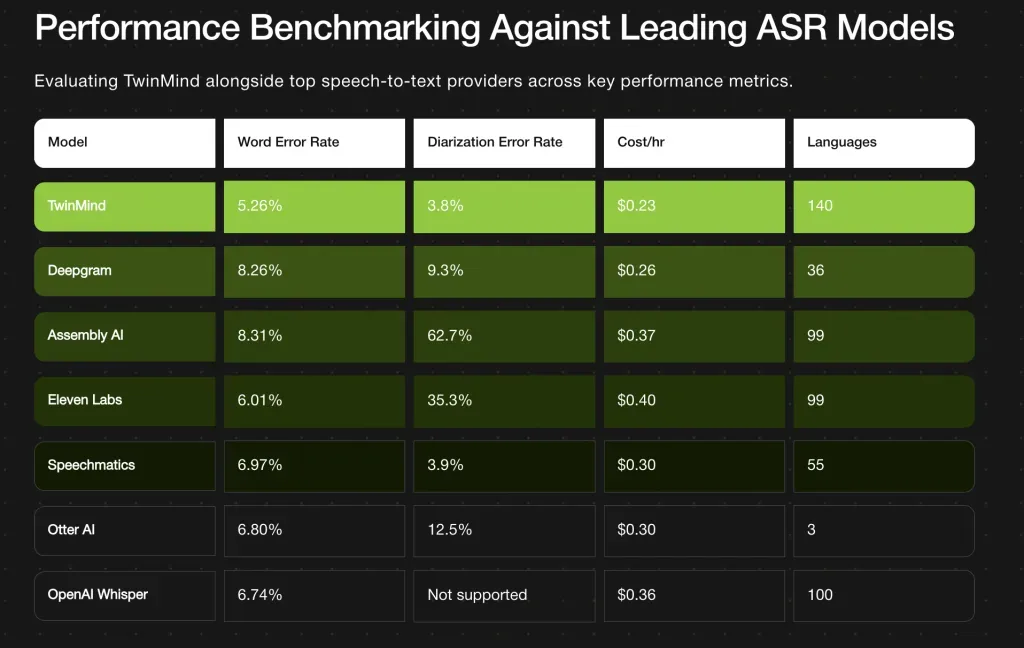
关键指标
| 指标 | TwinMind Ear-3 结果 | 比较/备注 |
|---|---|---|
| 单词错误率(WER) | 5.26% | 明显低于许多竞争对手:Deepgram ~8.26%,AssemblyAI ~8.31%。 |
| 说话人分类错误率 (DER) | 3.8% | 比 Speechmatics 之前的最佳成绩略有提高(~3.9%)。 |
| 语言支持 | 140多种语言 | 比许多领先模型多出 40 多种语言;旨在实现“真正的全球覆盖”。 |
| 每小时转录成本 | 0.23美元/小时 | 在主要服务中排名最低。 |
技术方法和定位
- TwinMind 表示 Ear-3 是“几种开源模型的精细混合”,在包含人工注释的音频源(如播客、视频和电影)的精选数据集上进行训练。
- 通过包括二值化之前的音频清理和增强以及“精确对齐检查”以改进说话者边界检测的管道,二值化和说话者标签得到了改进。
- 该模型处理代码转换和混合脚本,由于语音、口音差异和语言重叠等因素,这些对于 ASR 系统来说通常很困难。
权衡与运营细节
- Ear-3需要云部署。由于其模型大小和计算负载,它无法完全离线。TwinMind 的 Ear-2(其早期型号)在连接中断时仍可作为备用方案。
- 隐私:TwinMind 声称音频不会长期存储;只有文字记录会存储在本地,并提供可选的加密备份。录音会被“即时”删除。
- 平台集成:该模型的 API 访问计划在未来几周内面向开发者/企业开放。对于终端用户,Ear-3 功能将于下个月在 TwinMind 的 iPhone、Android 和 Chrome 应用程序中面向专业版用户推出。
比较分析与启示
Ear-3 的 WER 和 DER 指标使其领先于许多成熟模型。较低的 WER 意味着更少的转录错误(误识别、漏词等),这对于法律、医疗、讲座转录或敏感内容存档等领域至关重要。同样,较低的 DER(即更好的说话人分离 + 标注)对于会议、访谈、播客等任何多人参与的活动都至关重要。
每小时 0.23 美元的价格使得高精度转录对于长篇音频(例如数小时的会议、讲座、录音)来说更加经济实惠。加上对超过 140 种语言的支持,我们力求将其应用于全球环境,而不仅仅是以英语为中心或资源丰富的语言环境。
然而,对于需要离线或边缘设备功能的用户,或者对数据隐私/延迟要求严格的用户来说,云依赖可能会成为一种限制。支持 140 多种语言(口音漂移、方言、代码转换)的实施复杂性,可能会在不利的声学条件下暴露出较弱的区域。实际性能可能与受控基准测试结果有所不同。

结论
TwinMind 的 Ear-3 模型体现了其强大的技术优势:高准确度、说话人分类精准、广泛的语言覆盖范围以及大幅降低的成本。如果基准测试在实际使用中保持稳定,这可能会改变人们对“高端”转录服务应有的期望。
参考资料:
https://twinmind.com/transcribe
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/61513.html