
Miso Labs 发布了 MisoTTS,这是一款开放权重、拥有 80 亿参数的文本转语音模型。它能够根据文本和音频上下文生成富有表现力的语音。该模型采用残差矢量量化 (RVQ) 技术来拓宽其音域,从而避免了在保持参数数量不变的情况下,对单一扁平词汇表进行缩放。
什么是 MisoTTS
MisoTTS 是一个 8B 参数的文本到对话 RVQ Transformer,其设计灵感源自 Sesame CSM 架构。它采用 Llama 3.2 风格的主干架构,并搭配一个更小的音频解码器。该模型能够根据文本和可选的音频上下文生成 Mimi 音频代码。文本和先前的音频信息都会影响模型的运行。第二个输入信息使其能够响应说话者的语气。
文本词汇表包含 128,256 个词元,音频码本有 32 个。音频分词器为 Mimi,最大序列长度为 2,048。默认推理在torch.bfloat16环境下运行。
Miso Labs 声称其延迟为 110 毫秒。它列出的竞争对手包括 ElevenLabs(延迟 700 毫秒)和 Sesame(延迟 300 毫秒)。
词汇量问题
标准Transformer模型基于固定的离散词元词汇表生成模型。当目标空间仅需少量词汇即可覆盖时,这种方法是有效的。但人类语音并不符合这一假设。它的音调、节奏、重音、情感和口音各不相同。
扩展音频词汇量显然是最佳解决方案。但更大的词汇量需要标准Transformer模型提供更多参数。每个词元都必须由模型表示和预测。Miso Labs将此称为词汇量大小问题。
第二个问题是条件反射。大多数文本转语音(TTS)模型仅基于文本进行条件反射训练,而忽略了对话者的语气。Miso Labs认为,这会导致“恐怖谷效应”。
残余矢量量化:核心思想
MisoTTS 利用残差矢量量化 (RVQ) 解决了这两个问题。Miso Labs 认为 RVQ 源于图像生成研究和 Sesame 的音频 CSM 技术。该模型不再使用单个标记索引,而是生成一个索引向量。
每个音频标记包含 2048 个码本中的 32 个码本索引。该模型为向量中的每个位置维护一个单独的码本。为了恢复声音,它将查找到的向量相加。每个码本都会对信号进行一次精细化处理。
这就是扩展性得以实现的原因。可寻址词汇量等于码本大小的深度次方。增加深度不会给模型增加任何参数。因此,MisoTTS 可以达到约 2048³²个可寻址词元,或大约10¹⁰⁵个可寻址词元。Miso Labs 指出,简单的扩展方式需要更大的网络。
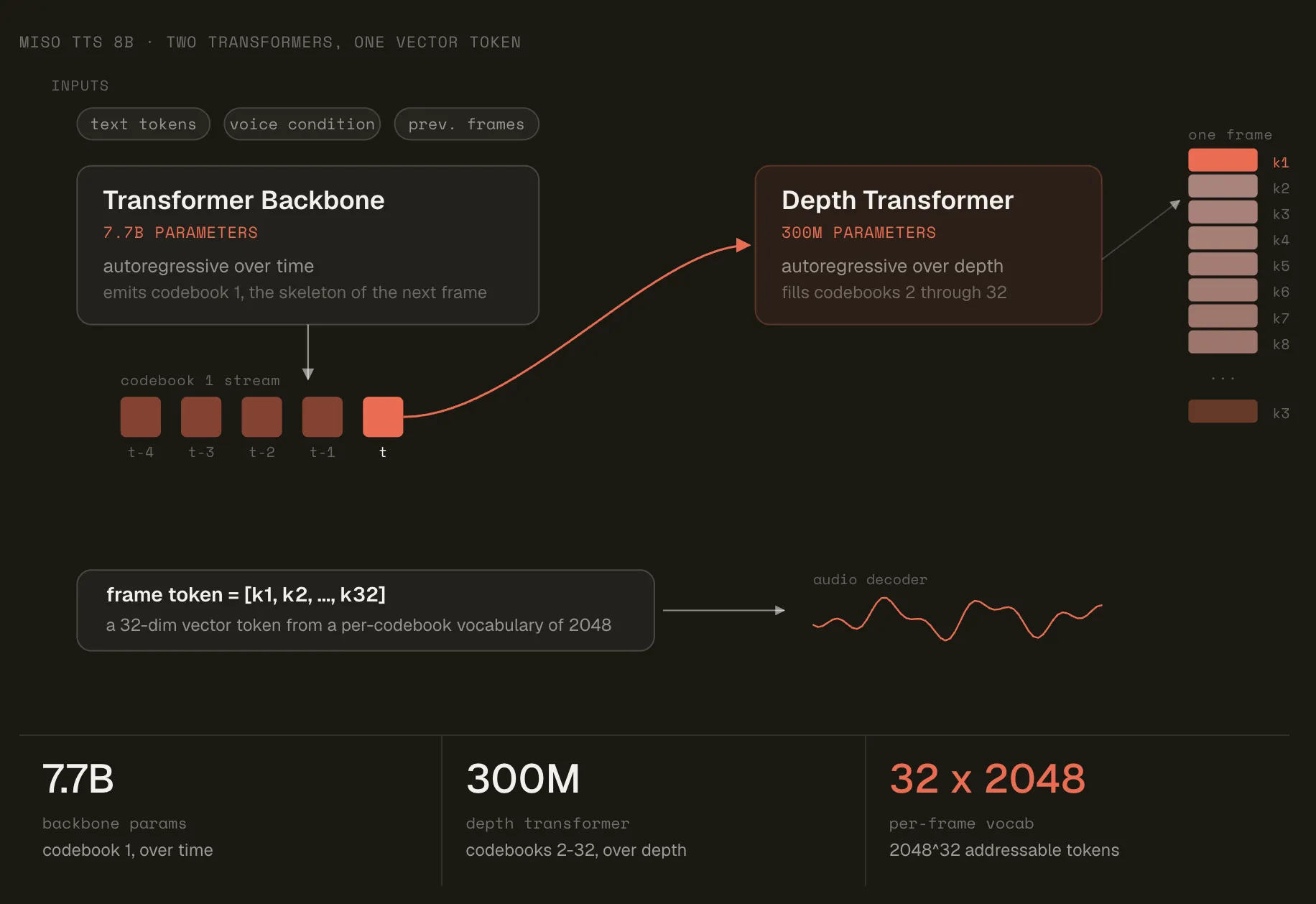

双变压器架构
该模型分为骨干网和解码器两部分。骨干网是一个77亿参数的Transformer模型,具有时间自回归特性。它预测初始码本索引和最终隐藏状态。
然后,一个拥有3亿个参数的解码器以自回归的方式逐层运行。它预测剩余码本的索引,每次预测一个位置。每次预测都基于帧中已选定的索引。对于每个位置,相同的3亿个参数都会被重复使用。
嵌入遵循相同的逻辑。文本标记使用单次查找。音频标记的嵌入是每个位置的码本查找次数的总和。文本和音频的交错排列使得主干网络能够利用对话历史记录。这就是它如何在对话回合之间传递上下文的方式。
优势与挑战
优势:
- 第一天就开放重量级比赛,采用修改后的 MIT 许可证。
- RVQ 缩放声音范围,而不缩放参数数量。
- 条件取决于音频上下文,而不仅仅是文本。
- 本地部署可将敏感音频数据保留在公司内部。
- 架构和数学原理已记录在一篇公开的博客文章中。
挑战:
- 仅限半独立式住宅,目前尚未实行轮流居住制。
- 大型模型需要功能强大的 CUDA GPU。
- API 访问权限已公布,但尚未开放。
- 延迟和质量方面的声明仍需第三方测试。
要点总结
- Miso Labs 根据修改后的 MIT 许可证开源了 MisoTTS,这是一个 8B 文本转语音模型。
- 它取决于文本和音频上下文,使几代人都能对说话者的语气做出反应。
- 残差矢量量化(32 个码本 × 2048 路)在不添加参数的情况下将词汇量扩展到 ~2048³²。
- 架构将 77 亿主干网(随时间变化)和 3 亿解码器(随深度变化)分开。
- 目前仅支持半双工和单向传输;API 访问仍在开发中。
参考资料:
https://huggingface.co/MisoLabs/MisoTTS
https://github.com/MisoLabsAI/MisoTTS
https://www.misolabs.ai/blog/miso-tts-8b
本文来自作者投稿,版权归原作者所有。如需转载,请注明出处:https://www.nxrte.com/jishu/67270.html